Técnicas Avançadas de Inteligência Artificial ao seu Alcance
CONTEÚDO DAS AULAS
GANs
1) Introdução a Redes Neurais Adversariais (GANs)
2) Transposed Convolutional Layer
3) Upsampling
4) Batch Normalization
5) Leaky ReLU
6) Arquitetura de uma GAN – Generator
7) Arquitetura de uma GAN – Discriminator
8) Programando uma Deep Convolutional GAN
9) Criando um Generator
10) Criando um Discriminator
11) Criando o loop de treinamento da DCGAN
12) Salvando as imagens geradas
13) Treinando e analizando os resultados da GAN
Séries Temporais e Redes Neurais Recorrentes
14) Introdução a Séries Temporais
15) Como funciona uma Rede Neural Recorrente (RNN)
16) Unrolling RNN
17) Truncated Backpropagation Through Time (TBTT)
18) Problemas de uma RNN
20) Como funciona uma Long Short-Term Memory (LSTM)
21) Empilhando LSTMs (Deep Learning)
22) Transformando dados temporais em um problema não temporal
23) Conexões temporais limitadas
24) Utilizando o método Window na prática
25) Aumentando o tamanho da janela
26) Utilizando LSTMs – parte 1
27) Utilizando LSTMs – parte 2
28) Separando Features de Timesteps
29) Utilizando Statefull em LSTM
30) Utilizando Dropout em LSTM
31) Empilhando LSTMs na prática
32) Prevendo o preço de ações na Bolsa de Valores com método Window
33) Prevendo o preço de ações na Bolsa de Valores com LSTM
34) Apresentação do Exercício de Dados Temporais
35) Solução do Exercício de Dados Temporais – Pré-processamento
36) Solução do Exercício – Treinamento
Processamento de Linguagem Natural
37) O que é Processamento de Linguagem Natural (NLP)
38) O teste de Turing
39) Como transformar textos em números
40) Tokenização de palavras
41) Temporalidade em NLP
42) Modelos baseados em palavras vs caracteres
43) Bidirectional Recurrent Neural Networks (BRNNs)
44) Word Embedding
45) Similaridade entre vetores embedding
46) Matriz Embedding x Vetores Embedding
47) Word2vec Skip-grams
48) Negative Sampling
49) Criando uma matriz embedding com aprendizado supervisionado
50) Sentiment Analysis
51) O problema do viés em NLP
52) A evolução dos Sistemas de Tradução
53) Como funcionam os Sistemas de Tradução
54) Beam Search
55) Length Normalization
56) Como saber qual modelo aperfeiçoar (Beam Search vs RNN)
57) Bleu Score
58) Como funciona o Speech Recognition
59) As funções split() e join()
60) Substituindo strings
61) Transformações entre maiúsculas e minúsculas
62) Extraindo texto de um arquivo .txt
63) Extraindo texto de um arquivo .docx
64) Extraindo texto de um arquivo .PDF
65) Utilizando operadores lógicos para comparar textos
66) Interpretando um arquivo robots.txt
67) Como fazer Web Scraping
68) Expressões Regulares: funções search() e finditer()
69) Expressões Regulares: caracteres coringa
70) Expressões Regulares: trabalhando com mais de um operador
71) Expressões Regulares: conjuntos de caracteres
72) Expressões Regulares: pesquisando por datas
73) Expressões Regulares: a função sub()
74) Prevendo a próxima palavra em um texto – parte 1
75) Prevendo a próxima palavra em um texto – parte 2
76) Prevendo a próxima palavra em um texto – parte 3
77) Exercício: prevendo palavras em letras de uma cantora pop
78) Solução do exercício: prevendo palavras em letras de uma cantora pop
79) Fazendo análise de sentimento em textos
80) Utilizando transfer learning com uma matriz embedding
81) Criando um Sistema de Tradução – parte 1
82) Criando um Sistema de Tradução – parte 2
83) Criando um Sistema de Tradução – parte 3
84) Verificando o Bleu Score da tradução
85) Fazendo Reconhecimento de Fala – parte 1
86) Fazendo Reconhecimento de Fala – parte 2
Aprendizado por Reforço
87) Introdução a Aprendizado por Reforço
88) Como estudar Aprendizado por Reforço
89) Diferenças entre Aprendizado por Reforço e outras técnicas
90) O que são Ações, Estados e Recompensas
91) k-armed Bandit Problem
92) Exploration vs Exploitation
93) 10-armed Bandit Problem
94) Optimistic Initial Values
95) UCB (Upper-Confidence-Bound Action Selection)
96) Otimizando o cálculo da média em cada iteração
97) Associative Search (Contextual Bandits)
98) MDP (Markov Decision Process)
99) Calculando probabilidades de ações, estados e recompensas
100) Ganho Esperado e Fator de Desconto
101) Policy, Value-function e Action-value function
102) Exemplo Gridworld
103) Optimal Policy
104) Iterative Policy Evaluation
105) Policy Iteration (PI)
106) Value Iteration (VI)
107) Dynamic Programming
108) Método de Monte Carlo
109) First-visit MC
110) Every-visit MC
111) Monte Carlo Control
112) On-policy vs Off-policy
113) Temporal Difference Learning – TD
114) Exemplo TD learning
115) Comparando TD learning com Monte Carlo
116) Value-function vs Action-value-function
117) Algoritmo SARSA
118) Algoritmo Q-Learning
119) Exemplo Q-Learning vs Sarsa
120) Deep Q-Learning
121) Experience Replay
122) Double Q-Network
123) Policy Gradient
124) Reinforce com Baseline
125) Actor-Critic
126) Ações contínuas vs discretas
127) A2C e A3C
128) ACKTR (Actor Critic Kronecker-factored Trust Region)
129) PPO (Proximal Policy Optimization)
130) Como o Alpha-Zero funciona
131) Instalando a biblioteca Gym
132) Explorando um ambiente na Gym
133) Criando uma Policy Determinística
134) Visualizando estados com matplotlib
135) Instalando a biblioteca Stable Baselines
136) Equilibrando um bastão com Deep Q-Learning
137) Visualizando um modelo treinado
138) Controlando um braço robótico com Deep Q-Learning
139) Skipping e Stacking
140) Dominando o jogo Pong com Deep Q Learning
141) Utilizando Wrappers
142) Rodando vários ambientes em paralelo com SubprocVecEnv
143) Como salvar o modelo enquanto treina (Checkpoint Callback)
144) Dominando o jogo Breakout com PPO
145) Exercício-Desafio Montain Car
146) Solução do Exercício Montain Car
147) Ensinando um robô a andar com A2C
148) Ensinando um robô a andar em terreno acidentado com ACKTR
149) Dominando o jogo Super Mario Bros com PPO
150) Instalando a biblioteca Gym Retro
151) Instalando jogos extras na Gym Retro
152) Salvando Estados de Jogos
153) Treinando diferentes estados em paralelo
154) Criando função de recompensa personalizada e Discretizando espaço de ações
155) Dominando o jogo Street Fighter com PPO
156) Visualizando uma IA virando o game Street Fighter
157) Fazendo o agente apenas se defender no Street Fighter
158) Carregando e Retomando um Treinamento
Algoritmos Genéticos
159) Como funcionam os Algoritmos Genéticos
160) Algoritmos Genéticos em Redes Neurais
161) Algoritmos Genéticos com DEAP – parte 1
162) Algoritmos Genéticos com DEAP – parte 2
163) Utilizando a função eaSimple()
164) Transformando um indivíduo em arrays de pesos e bias para o Keras
165) Calibrando uma rede neural com Algoritmos Genéticos
166) Reinforcement Learning com Algoritmos Genéticos
Testando seus conhecimentos
EXERCÍCIOS TEÓRICOS
EXERCÍCIOS PRÁTICOS
Muitos exercícios foram elaborados para você colocar em prática tudo o que está aprendendo ao longo do curso. Confira abaixo alguns exemplos de aplicações que você irá aprender:
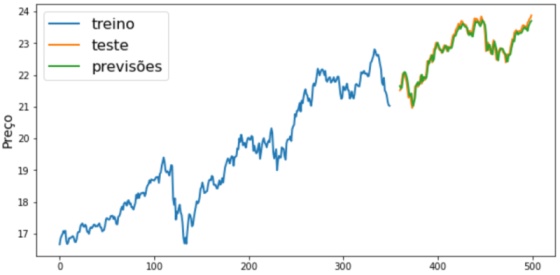
Séries Temporais

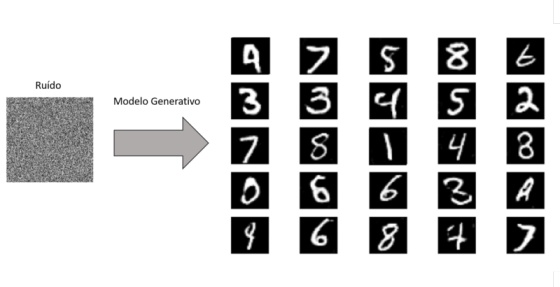
Redes Neurais Adversariais (GANs)

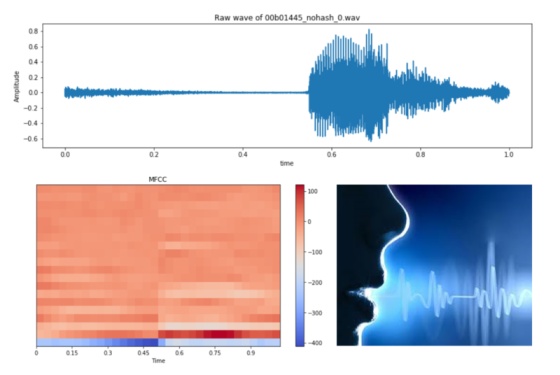
Processamento de Linguagem Natural

Sistemas de Tradução
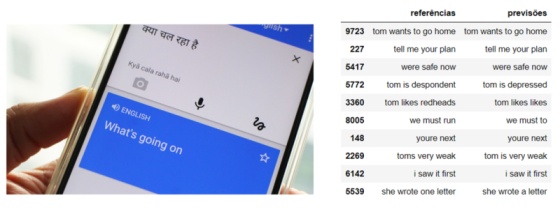

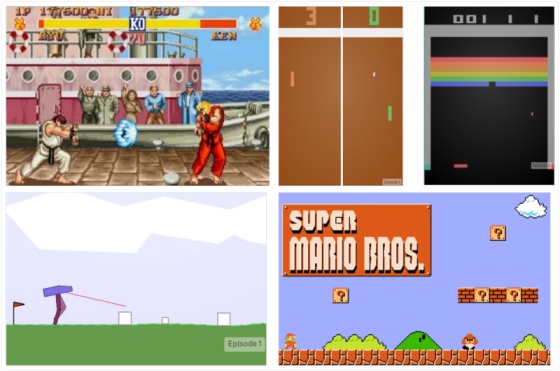
Aprendizado por Reforço

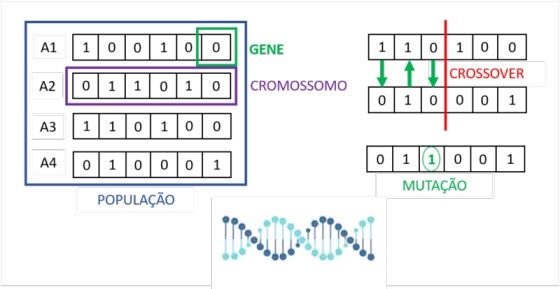
Algoritmos Genéticos

O QUE OS ALUNOS ESTÃO DIZENDO?