
Você ainda não sabe programar? Quer aprender Machine Learning mas fica na dúvida se será possível com pouco, ou nenhum, conhecimento em programação?
Aqui iremos mostrar como executar e aplicar modelos de Machine Learning sem complicações. Você verá que, de início, nenhum conhecimento em programação será necessário. Fique conosco até o final para entender como será possível.
Obviamente, nós recomendamos que você aprenda conceitos básicos sobre programação desde já, pois isso irá ajudar no domínio do Machine Learning e da análise de dados facilitando seu aprendizado. Se desejar, antes de prosseguir, você pode conferir gratuitamente nosso curso de Python básico. Nele você começará a se familiarizar com a programação de maneira simples e objetiva, sem enrolações.
Entretanto, não há necessidade de realizar o curso para aprender a aplicar Machine Learning. Não espere para começar apenas sendo um programador. Comece agora!
Utilização do Power BI
Primeiramente, é importante deixar um conceito muito claro: Machine Learning não é programação! É claro que, com todo o poder computacional que temos hoje, a programação possibilitará a criação de nossos modelos.
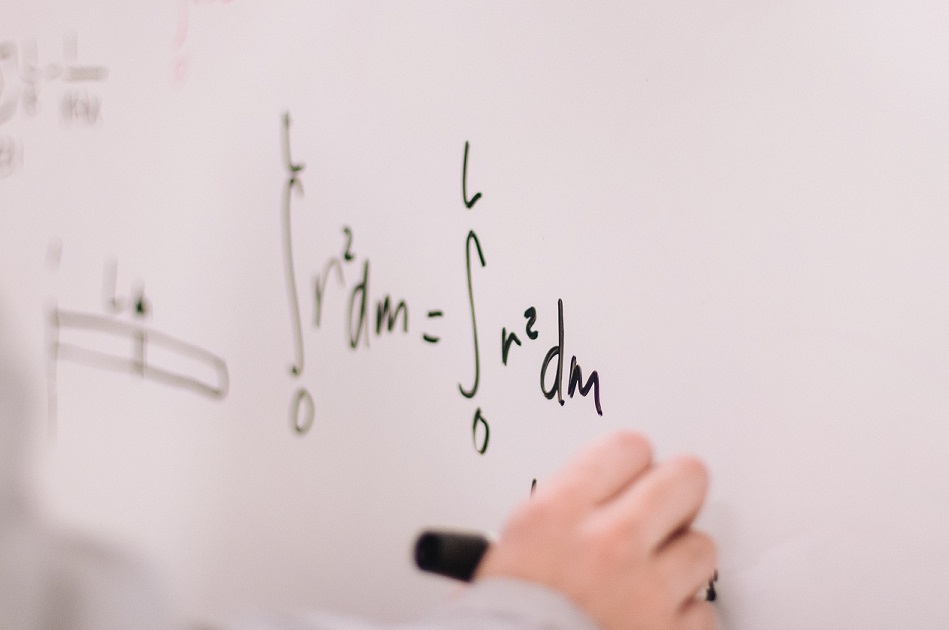

No entanto, a essência e a teoria do Machine Learning estão muito mais ligadas à matemática.
Assim sendo, é possível entender o que acontece, como as previsões são geradas, como um modelo é criado, sem saber programar. Uma forma muito fácil de fazermos isso é através do Power BI. Esse programa nos possibilita uma integração completa com linguagem R e linguagem Python. Assim, nós conseguimos utilizar scripts bem simples e poucas linhas de código para a criação dos nossos modelos.
Além disso, iremos utilizar o Power BI para fazer todo o tratamento nos dados, para carregar nossa base e fazer os ajustes necessários de maneira muito simples e intuitiva. Apenas nos momentos em que precisarmos fazer o treinamento do modelo e a utilização de algoritmos, serão necessárias as linguagens de programação propriamente ditas.
Depois, quando já tivermos os resultados e as previsões, eles serão retornados para dentro do Power BI, o que possibilitará a criação de gráficos e dashboards de maneira completa.
Como começar?
Se você ainda não tem o Power BI no seu computador, confira aqui o processo de instalação.
Além disso, você também deverá instalar a linguagem Python. Siga o tutorial abaixo e você verá como é simples:

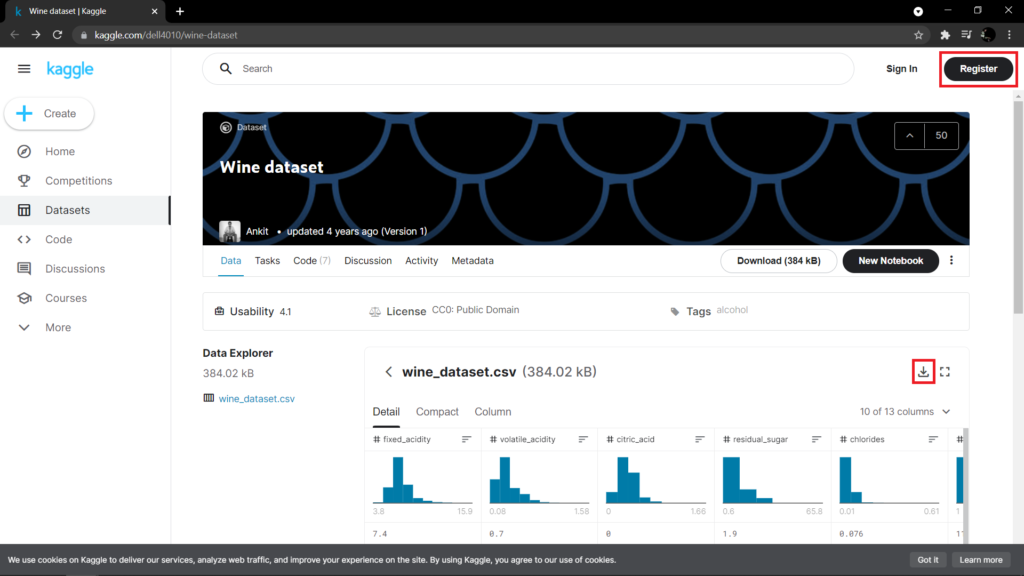
Agora, com tudo instalado, você precisará fazer o download da base de dados que iremos utilizar. Acesse o seguinte link https://www.kaggle.com/dell4010/wine-dataset, faça o registro e baixe o arquivo wine_dataset.csv, conforme a imagem abaixo.
Você verá os botões que devem ser clicados ao longo do processo dentro de retângulos destacados em vermelho.

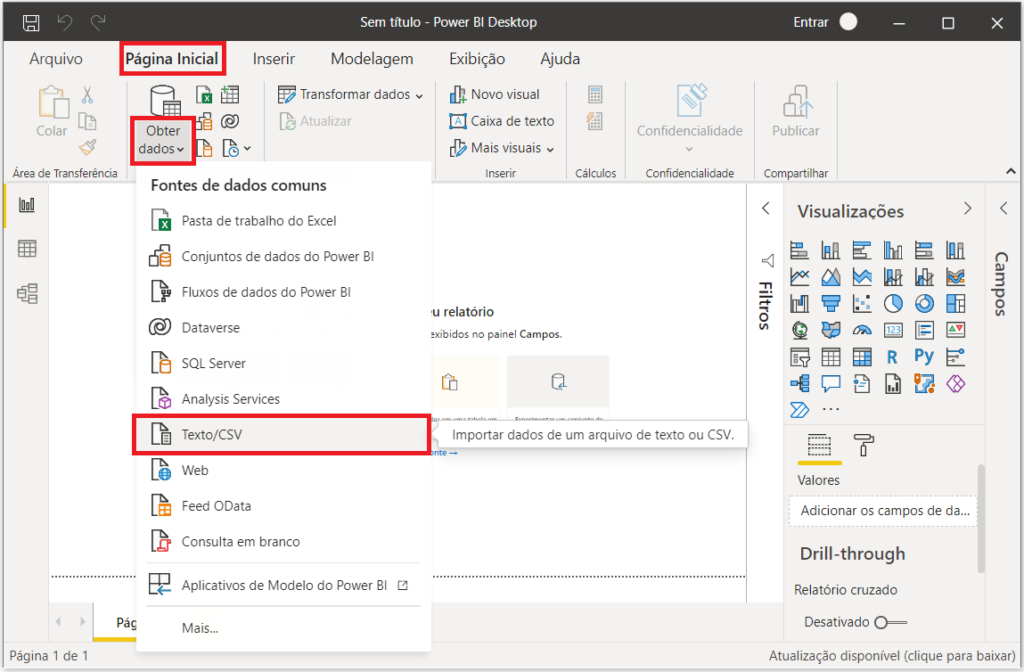
Agora, abra o Power BI e selecione a base de dados que você baixou. Em “Página Inicial”, clique em “Obter dados” e na opção “Texto/CSV”.

Obs: vamos continuar esse artigo mostrando as imagens sobre o que você deve fazer em cada etapa. Se preferir, você também pode conferir este conteúdo na videoaula abaixo:

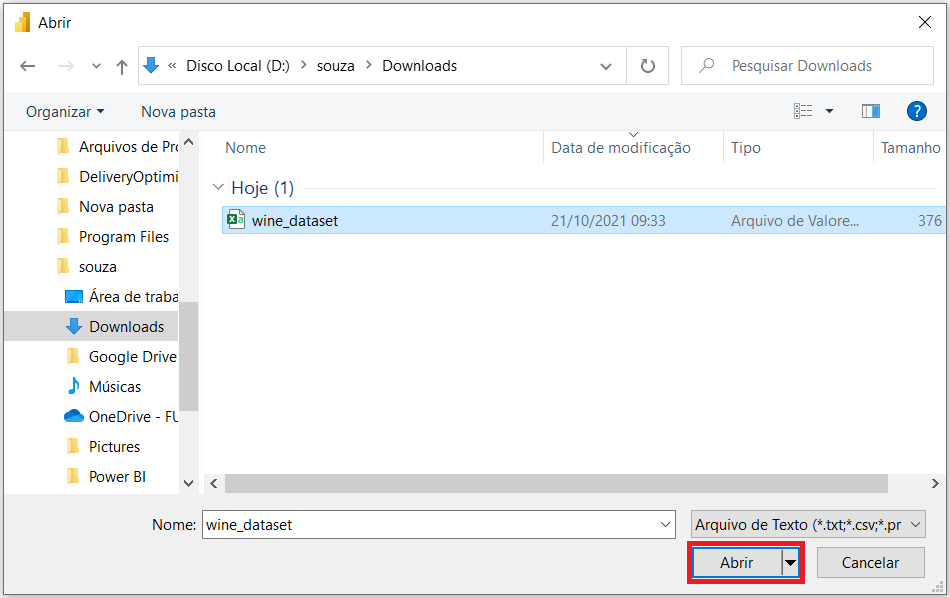
Selecione a base de dados “wine_dataset” e clique em “Abrir”. Note que você encontrará essa planilha na pasta onde baixou o arquivo.

Ao abrir a planilha, você verá que a base conta com cerca de 6.000 linhas de dados, contendo características sobre determinados vinhos – uma dessas características é se o vinho é do tipo tinto ou branco. Nosso objetivo, com esse dataset, é criar um modelo de Machine Learning que consiga, a partir das características registradas, descobrir se um vinho em questão é do tipo tinto ou branco. Faremos isso com vinhos que o modelo ainda não conhece.
Para prosseguir, clique na opção “Transformar Dados”, conforme a imagem abaixo.
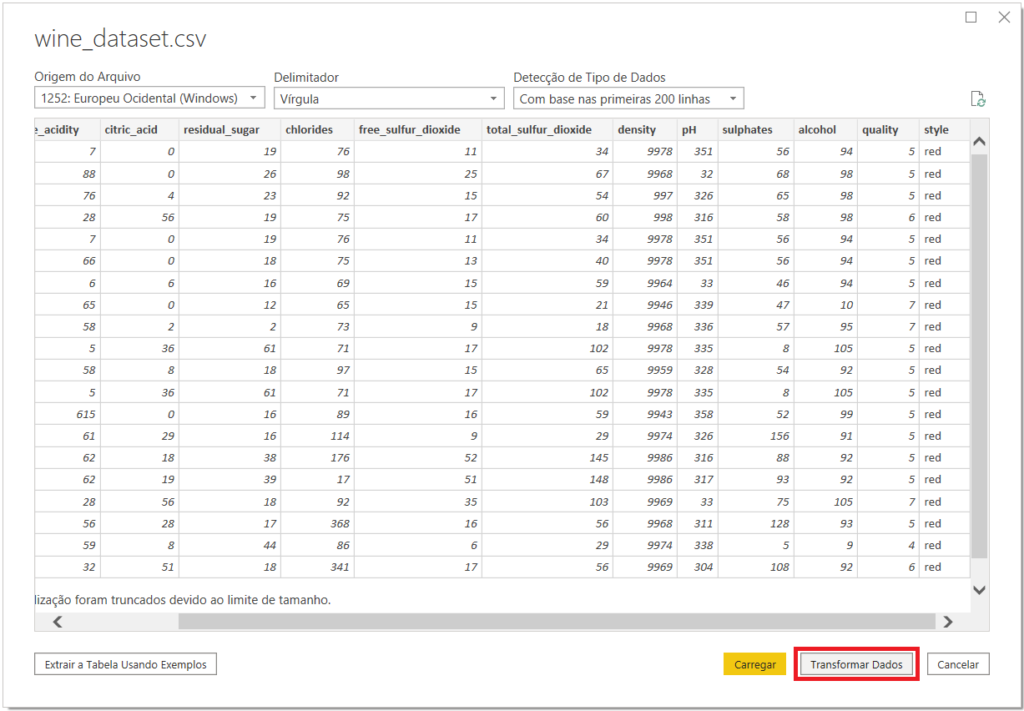

Quando formos, efetivamente, trabalhar com uma base e criar um modelo de Machine Learning com ela, podemos fazer diversos ajustes e criar visualizações no Power BI. Nesse momento, entretanto, não há essa necessidade. Esta base já está devidamente tratada, possibilitando que passemos diretamente para a criação do modelo.
Na aba “Transformar”, selecione a opção “Executar Script em Python”. A janela onde será colocado o script abrirá automaticamente. É nessa etapa do processo que a programação terá de ser utilizada. Entretanto, conseguiremos prosseguir sem saber programar.
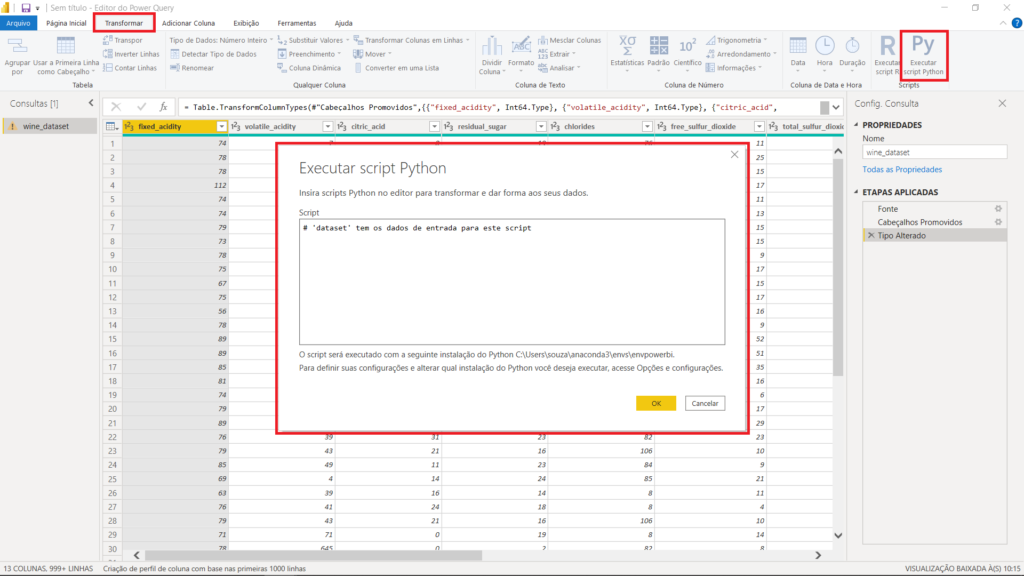
Poderíamos executar tanto um script em R quanto em Python; os dois tem o mesmo objetivo e entregam o mesmo resultado. Dessa forma, conforme você for avançando nos estudos, poderá utilizar a linguagem que preferir. Tanto R quanto Python são muito utilizados para Machine Learning e para análise de dados.
Elas possuem muitas funções e pacotes que foram criados exclusivamente para essa finalidade. Por isso, grande parte das execuções que precisamos fazer já foram criadas por alguém e só precisamos saber como utilizá-las.
No editor do script Python, cole o código abaixo:
y = dataset['style']
x = dataset.drop('style', axis = 1)
from sklearn.model_selection import train_test_split
x_treino, x_teste, y_treino, y_teste = train_test_split(x, y, test_size = 0.30)
from sklearn.ensemble import ExtraTreesClassifier
modelo = ExtraTreesClassifier()
modelo.fit(x_treino, y_treino)
dataset['Previsao'] = modelo.predict(x)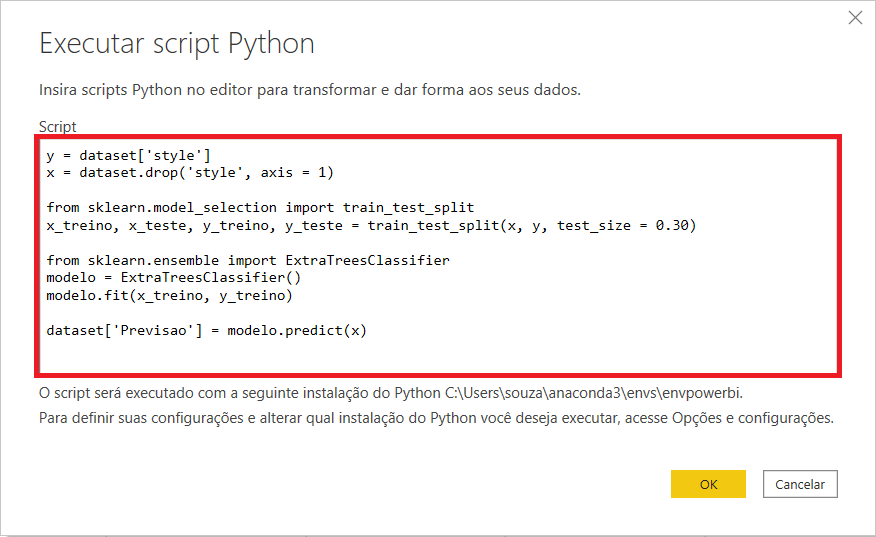

Note que a primeira linha que aparecia anteriormente (# ‘dataset’ tem os dados de entrada para este script) pode ser excluída do editor. Ela não fará parte do nosso código.
Explicando o script
Basicamente, para conseguir compreender o script que estamos utilizando, são importantes alguns conhecimentos sobre Machine Learning. Isso por que os passos utilizados são necessários para a aplicação de um modelo de Machine Learning. Abaixo explicaremos cada linha do código e, se prefirir, confira nosso curso gratuito de introdução a Machine Learning, para ter um entendimento completo:
y = dataset['style']
x = dataset.drop('style', axis = 1)Nessas duas primeiras linhas, simplesmente dividimos a base entre as colunas que possuem as características dos vinhos e a coluna que diz de qual tipo o vinho é (tinto ou branco). Na linha “x = dataset.drop(‘style’, axis = 1)“, nós estamos excluindo a coluna “style” da base e salvando esse resultado em uma nova variável, a variável “x”, que conterá apenas as variáveis preditoras (colunas com as características necessárias para o aprendizado).
Na linha “y = dataset[‘style’]“, nós estamos determinando que a variável target, aquela da qual queremos descobrir o valor, será a coluna “style”, salvando seu conteúdo na variável “y”, que acabamos de criar.
from sklearn.model_selection import train_test_split
x_treino, x_teste, y_treino, y_teste = train_test_split(x, y, test_size = 0.30)Sempre que aparecer o código “from……import…” significa que estamos importando uma biblioteca pronta para nos ajudar.
Na sequência, com as linhas acima, nós separamos os dados em treino e teste. Quando estamos criando um modelo de Machine Learning, é necessário ter uma base para treinar o modelo e outra base para testá-lo.
Realizando essa separação, será possível fazer com que o modelo realize o treinamento e então seja testado em uma nova base, que ele ainda não conhece. Assim, saberemos se ele teve um desempenho razoável ou não. Ou seja, veremos se o modelo se comportou conforme o esperado.
from sklearn.ensemble import ExtraTreesClassifier
modelo = ExtraTreesClassifier()
modelo.fit(x_treino, y_treino)Nessa próxima etapa, estamos criando o modelo propriamente dito.
Com a linha “modelo = ExtraTreesClassifier()“, nós definimos que o modelo utilizará o algoritmo ExtraTrees.
Com a linha “modelo.fit(x_treino, y_treino)“, estamos apresentando ao algoritmo os dados de treino – as variáveis “x_treino” e “y_treino“, que foram criadas quando separamos os dados em treino e teste na etapa anterior.
dataset['Previsao'] = modelo.predict(x)A partir do modelo criado, essa última linha irá realizar as previsões.
Com a função “.predict()“, mostramos para o modelo todos os dados que temos – as 6 mil linhas de vinhos da nossa base de dados. Dessa forma, ele irá retornar a previsão para cada uma dessas linhas. Para cada caso, o modelo dirá se o vinho é tinto ou branco.
Por fim, essa informação será salva em uma nova coluna, a coluna “Previsao”.
Executando o modelo
Dando sequência, vamos clicar em “Ok” para executar o nosso modelo.
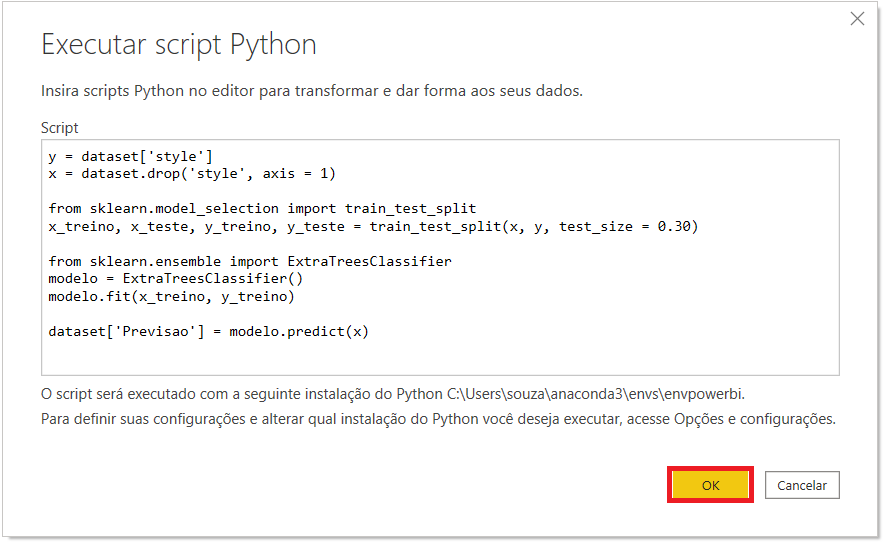

Na primeira vez que você utilizar um script (R ou Pyhton) no Power BI, a mensagem de aviso abaixo irá aparecer. Nesse caso, é só clicar em “Continuar”, selecionar a caixa que diz “Ignorar verificações de níveis de privacidade” e clicar em “Salvar”.
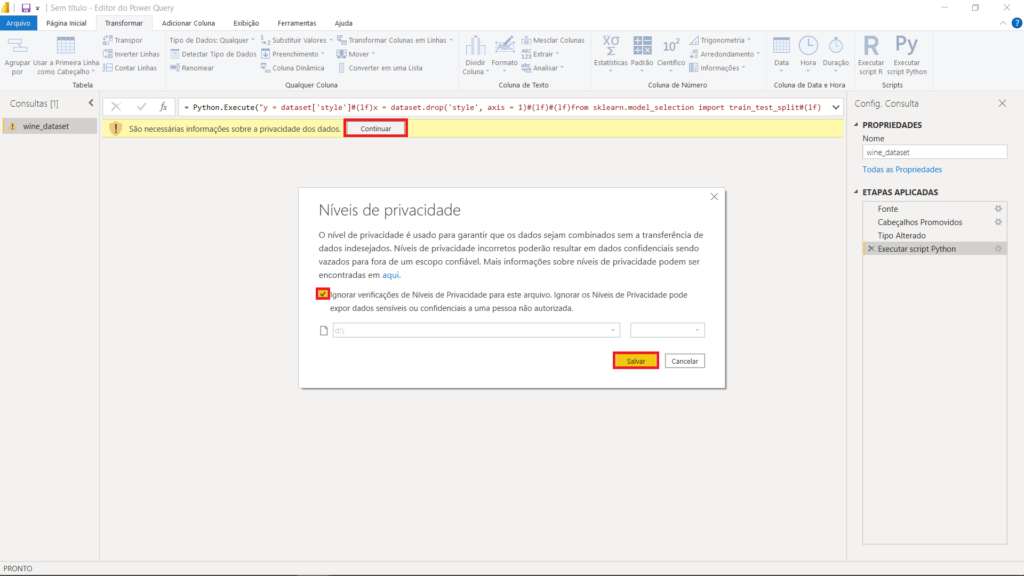
Veremos, então, as várias tabelas que foram criadas como retorno do script. Estamos interessados na tabela “dataset”, que é a tabela completa – com toda a nossa base de dados e a nova coluna “Previsao” que criamos. Clique na opção “Table”, na primeira linha.
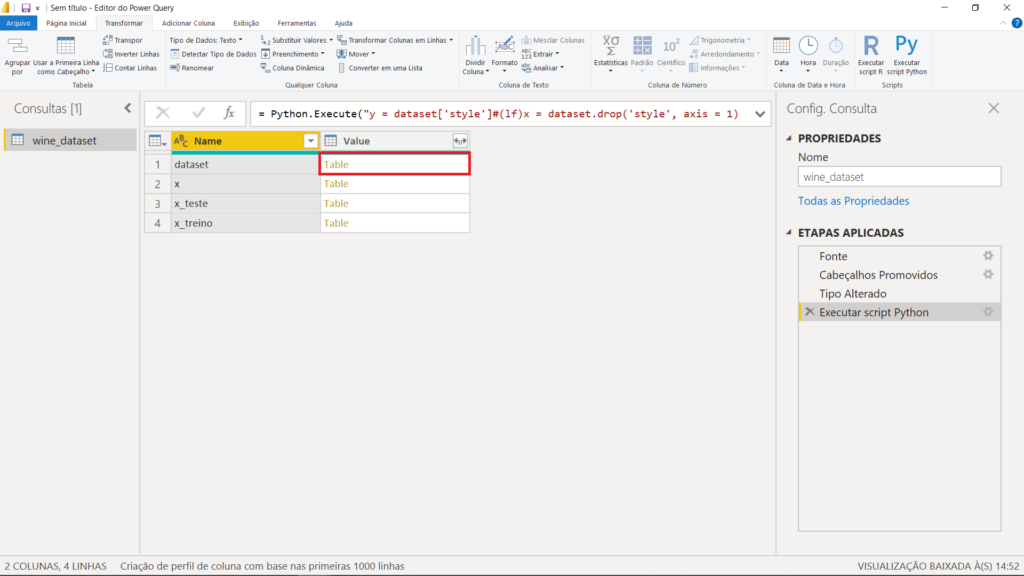
Agora, nós temos a mesma base que foi visualizada inicialmente, quando carregamos os dados, com uma coluna a mais. Se levarmos a barra horizontal toda para a direita, veremos que a coluna “Previsao” foi de fato criada e apresenta o resultado do nosso modelo para cada um dos vinhos.
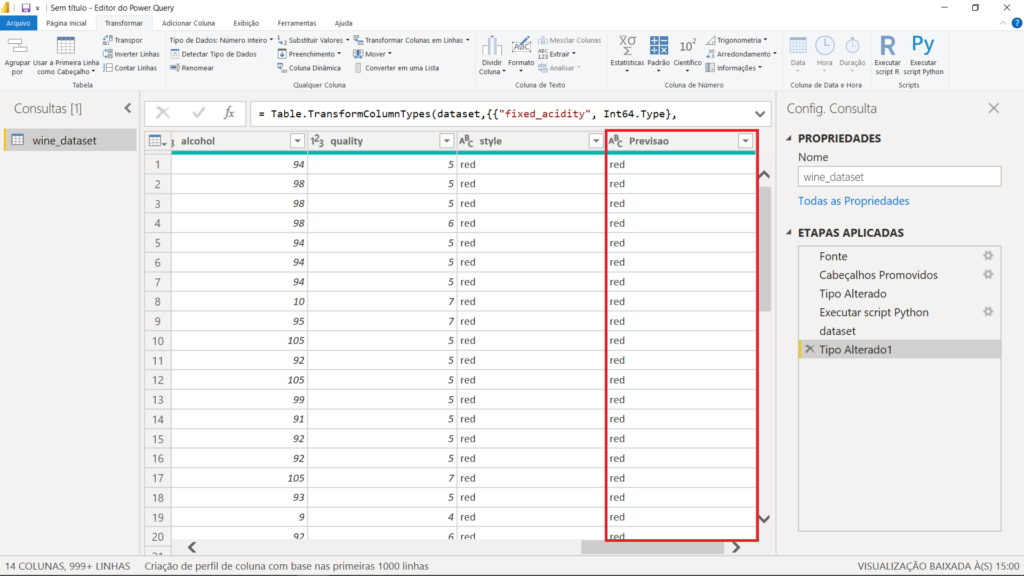
Nós poderíamos conferir, linha por linha, para saber se as previsões do modelo foram corretas. Entretanto, são mais de 6 mil amostras. Podemos, então, selecionar as colunas “style” e “Previsao” e, na aba “Página inicial”, clicar em “Agrupar por”, para assim criar um agrupamento e simplificar nossa conferência. Não esqueça de clicar em “Ok”.
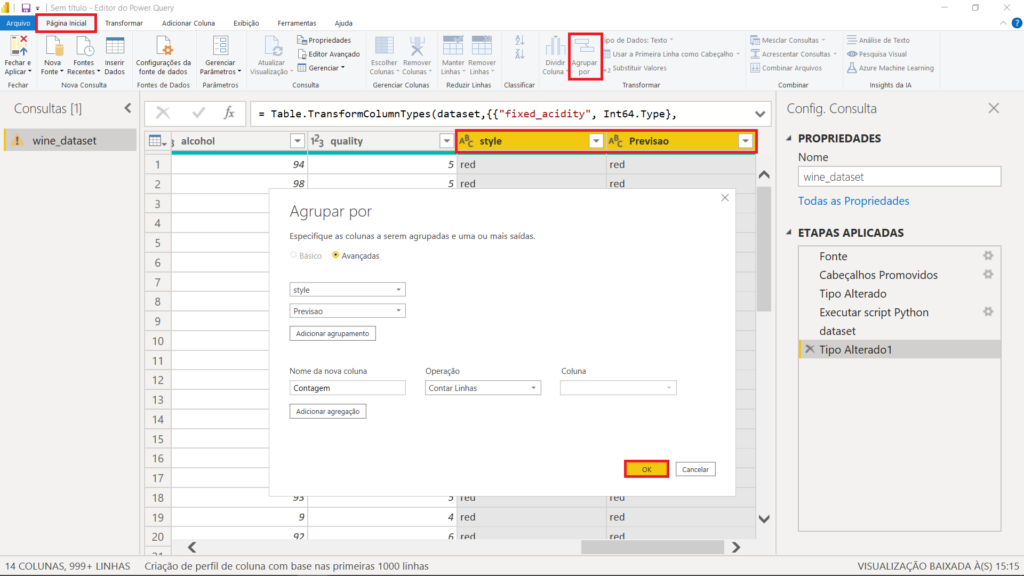
Como resultado, temos todas as combinações entre essas duas colunas.
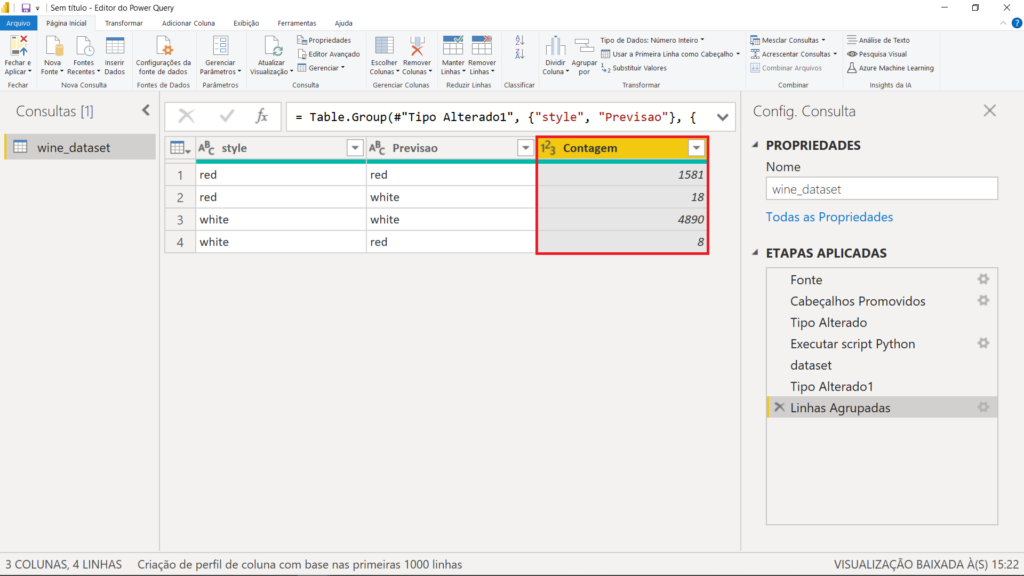
Você verá quatro possibilidades:
- O vinho era tinto e o modelo acertou;
- O vinho era tinto e o modelo errou;
- O vinho era branco e o modelo acertou;
- O vinho era branco e o modelo errou.
Perceba que nosso modelo teve mais de 99% de acurácia na base completa, somando dados de treino e teste. Esse é um resultado excelente. Em mais de 6 mil vinhos, apenas 26 vezes ele errou a previsão.
Ou seja, esse modelo de Machine Learning que estamos usando consegue entender o relacionamento dos dados e realizar as previsões com precisão.
Por fim, observe que esse código que utilizamos separa os dados de treino e teste de forma aleatória. Assim sendo, se você encontrar, como resultado, valores um pouco diferentes dos nossos, não há nenhum problema.
De maneira bem básica e resumida, esse é o processo através do qual conseguiremos aplicar Machine Learning sem precisar saber programação, apenas utlizando um código pronto para criação do modelo.
Não pare seu aprendizado por aqui
Agora você pode estar pensando: “Mas nesse processo todo, estamos utilizando programação e ainda não sei escrever códigos como esse”. Claramente, você pode começar a criar seus modelos apenas copiando e colando os códigos. Se você tiver outras bases de dados, poderá utilizar o mesmo código que apresentamos aqui para fazer alguma previsão.
Entretanto, para um aprendizado mais eficaz, e aplicações diversas, é muito importante que você amplie seu conhecimento.
Por conta disso, criamos um curso de machine learning com Power BI. Nele você ira estudar os conceitos de Machine Learning de mandeira detalhata, entendendo a utilização de vários algoritmos diferentes: ensinaremos regressão linear, regressão logística, árvore de decisão, entre outros.
Assim, você poderá aprender os códigos de Machine Learning de forma didática e intuitiva, com aplicações práticas no Power BI e com uma utilização mínima de código.
Confira também outros cursos! Temos diversas opções, tanto pagas quanto gratuitas.
Leia outros artigos: