


Muitas são as definições utilizadas ao se falar sobre Business Intelligence (BI), mas a melhor forma para se entender o real sentido da expressão é simplesmente traduzindo para o português.
A Inteligência de Negócios existe para que os negócios e as empresas tomem decisões inteligentes, não sendo guiados apenas por opiniões, ideias que no passado traziam resultados, ou mesmo a vontade de quem comanda.
Com este pensamento, percebemos que o BI sempre existiu, porém sua forma de execução está em constante evolução.
Atualmente a inteligência de negócios, os analistas de BI, ou ainda os setores de empresas denominados com estes nomes costumam organizar seus processos de acordo com a imagem abaixo:
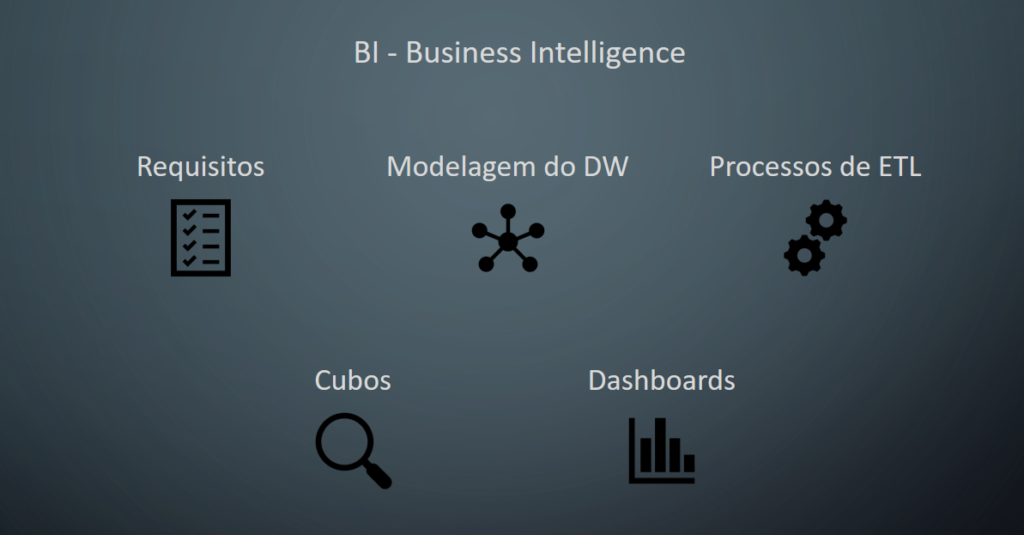

Hoje a melhor maneira de enxergar o Business Intelligence é através de suas cinco etapas principais, sendo que a única razão da existência delas é responder perguntas e fornecer insights sobre o negócio.
Desta forma, as 4 etapas iniciais existem em função da última, e não estando esta bem definida, todo processo estará destinado ao fracasso.
De maneira objetiva, podemos enxergar estas etapas da seguinte forma:
- Requisitos: verificação da existência dos dados necessários para a solução
- Modelagem do DW (Data Warehouse): organização e armazenamento destes dados de maneira a otimizar a análise.
- Processos de ETL: extração, transformação e carregamento. Os dados são extraídos de onde estão arquivados, transformados conforme estabelecido na organização anterior e carregados no DW (data warehouse).
- Cubos: cruzamento dos dados, levando as respostas e insights esperados.
- Dashboards: apresentação do resultado.
Porém antes de analisarmos com calma cada uma dessas etapas, é necessário situarmos o BI dentro de um contexto cada vez mais importante, e que em pouco tempo receberá mais atenção do que o próprio Business Intelligence: a Ciência de Dados.
Ciência de Dados
A Ciência de Dados pode ser vista como a área responsável por transformar dados em informação.
Acabamos de dizer que o BI existe para tomada de decisão inteligente, e agora definimos que a Ciência de Dados existe para transformar dados em informação, e o objetivo desta informação é a tomada de decisão. Então estamos falando da mesma coisa?
Sim e não. Realmente ainda é um pouco complicado comparar esses dois termos, não existindo uma definição unânime do que é cada uma das áreas. Vamos tentar esclarecer isso a seguir:


Ciência de Dados vs Business Intelligence
Normalmente quando alguém menciona BI, a pessoa está fazendo referência a análises do passado, do que já aconteceu e como isso aconteceu, utilizando-se dados estruturados, muito comuns nos bancos de dados das empresas. Portanto é comum o BI ser associado a negócios, como o próprio nome diz.
Por sua vez, a Ciência de Dados possui uma conotação muito mais abrangente, podendo inclusive possuir todo Business Intelligence dentro dela. Muitas empresas já possuem setores de Ciência de Dados que absorveram o setor de BI da empresa, e seus analistas de BI se tornaram Cientistas de Dados.
Na Ciência de Dados, pode-se utilizar dados estruturados ou não, como vídeos, áudios, postagens em redes sociais, usufruindo de toda capacidade do Big Data.
Aqui também veremos com frequência uma das grandes tecnologias da atualidade, o Machine Learning (ou Aprendizado de Máquina), que faz parte da inteligência artificial, possibilitando previsões com alto grau de precisão.
Em resumo, a principal diferença do BI para a ciência de dados é que o BI tenta mostrar de forma clara o status de um conjunto de dados específico, enquanto a ciência de dados tenta extrair informações outrora ocultas a partir do reconhecimento de padrões de dados diversos utilizando algoritmos avançados.
Entendidas estas diferenças, podemos voltar para o BI e entender em detalhes cada uma de suas etapas.
Dashboards – Visualização de dados
A visualização de 

Apesar de ser a última etapa, começamos por ela pois se não soubermos com clareza o que esperamos que estes dados nos informem, não adianta nem iniciarmos o processo.
Mencionamos o termo “Dashboard” pois está na moda, e realmente é muito útil. Um “Dash” tem a capacidade de agrupar muitas informações relevantes em uma única tela.
Por mais complexa que possa ser a análise realizada, quando pensamos em um dashboard para apresentar os resultados, estamos buscando uma resposta objetiva, que resuma muitas informações em poucas, e agrupe diferentes análises em uma única imagem, de maneira que ao olharmos a imagem como um todo ela faça sentido.
É importante observarmos que esta etapa pode existir de muitas formas diferentes. Seu objetivo é transmitir o resultado de uma análise, e há casos onde um simples valor numérico pode ser suficiente, ou ainda uma resposta binária como “compre” ou “venda”.
Conforme explicamos acima, um dashboard pode ser de grande utilidade, mas é fundamental entendermos sua real necessidade. Se o projeto em questão tem o objetivo de informar se o preço de um produto deve aumentar ou diminuir, informe apenas isso, sem firulas.
Normalmente a pessoa que toma decisões não quer perder tempo com distrações. Isto não significa que você deve ignorar todas as demais informações geradas na análise quando elas não são explicitamente solicitadas, neste caso um relatório complementar pode ser o caminho.
Como vocês podem perceber, por mais que a apresentação dos resultados pareça simples, ela é de suma importância para todo o processo, razão pela qual a mencionamos primeiro.
Na elaboração de um projeto, pode-se fazer um rascunho do que se espera como resultado, deixando claro as perguntas que devem ser respondidas, e como as respostas devem ser apresentadas. Com estes dados é possível voltarmos ao início do processo.
Requisitos – Levantamento de Requisitos
Sabendo o que quere
Não é responsabilidade do processo de BI coletar e armazenar os dados da empresa. Os dados podem ser coletados e armazenados de diferentes formas, e no levantamento de requisitos todas essas informações precisam estar à disposição.
Um dos objetivos pode ser saber a cidade que realiza mais compras de uma loja, ou seja, se agruparmos todas as vendas da loja por cidade, ignorando o cliente que fez a compra, teremos esse valor.
Mas para atingir este objetivo todos os dados envolvidos precisam estar armazenados. Toda compra precisa estar associada a uma cidade, do contrário não será possível atingir o objetivo, ou apenas de maneira parcial, indicando que em x % das vendas a cidade y é a que mais compra.
Caso o objetivo não seja atingível, será necessário verificar a possibilidade de execução sem este objetivo, ou ainda conversar com os responsáveis pela coleta e armazenamento dos dados para implementar esta informação nas novas vendas, sabendo que apenas a partir do momento em que a informação for devidamente coletada e armazenada a análise acontecerá.
Para conclusão desta etapa, todos os demais dados necessários para o processo devem ser verificados, confirmando sua disponibilidade e localização.
É comum os dados estarem armazenados em locais diferentes (diferentes bancos de dados), implicando em métodos de extração diferentes. É importante também saber a granularidade na qual eles existem. Por exemplo, a data é informada através de ano/mês, ou ano/mês/dia – hora/minuto/segundo?
Uma aplicação prática de BI


É importante observarmos que em uma aplicação prática de business intelligence, que já esteja em execução, não existirá o levantamento de requisitos, uma vez que esta etapa é executada apenas na implementação do projeto e em suas atualizações.
Outro ponto que merece atenção é a ordem das etapas. Na imagem inicial vemos a ordem “Modelagem do DW”, “Processos de ETL” e “Cubos”.
É nesta ordem que o projeto deve acontecer, porém na aplicação prática, a sequência será “Processos de ETL”, “Modelagem do DW” e “Cubos”. Abaixo ficará claro o motivo desta diferença.
Modelagem do DW – Data Warehouse
O Data W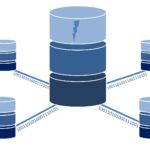
Além destas consultas serem lentas, o desempenho do banco pode ser afetado, e problemas para o usuário final podem acontecer, o que sempre deve ser evitado.
Desta forma, o foco do DW está em sua grande capacidade de armazenamento, com uma organização otimizada para consulta, e agrupamento de dados retirados de diferentes fontes em apenas um local.
No DW podem existir dados históricos que a empresa não utiliza mais em suas atividades diárias, mas que continuam relevantes para análises.
O projeto deste banco de dados, ou sua modelagem dimensional, é essencial para o bom funcionamento de todo o sistema. Por este motivo é fundamental que esta modelagem aconteça antes de se definir os processos de ETL que veremos na sequência, uma vez que eles existirão para alimentar este banco.
Modelagem Dimensional
A mode
Os bancos de dados são organizados em tabelas, podendo ou não existir relação entre uma tabela e outra. Para simplificar o entendimento, imagine um arquivo de Excel com várias planilhas, cada planilha seria uma tabela em um banco de dados, e o banco em si seria o arquivo. É evidente que um banco de dados possui uma complexidade muito maior do que a que costumamos encontrar em arquivos de Excel, mas a lógica para entendimento é válida.
Em um modelo dimensional, utilizam-se dois métodos: o Snowflake e o Star Schema. O mais utilizado é o Star Schema, ou esquema estrela.
Apesar dos nomes complexos, a ideia e a prática são muito simples. No esquema estrela teremos uma Tabela Fato e Tabelas Dimensões (modelo dimensional), sendo que as tabelas dimensões estão ligadas a fato.
- Tabela Fato – como o nome diz, ela registra um fato, um acontecimento. Você foi ao mercado A e comprou o refrigerante B. Na tabela fato haverá uma linha com essa informação, sendo que as colunas irão detalhar este fato com o nome do mercado, data, produto, valor, etc.
- Tabelas Dimensões – tabelas contendo as informações relativas ao que acontece na fato. Poderemos ter uma tabela com o nome “Mercados”, onde existirá uma relação de mercados e seus detalhes, outra tabela com o nome “Produtos”, e assim por diante. Através das tabelas dimensões encontramos detalhes sobre o evento registrado na tabela fato.
Quando visualizamos esta organização, com as tabelas dimensões ligadas à tabela fato no centro, enxergamos algo semelhante a uma estrela.
No esquema Snowflake teremos esta mesma organização, com uma tabela fato e tabelas dimensões, sendo que neste poderão existir dimensões ligadas apenas com outras dimensões. Este modelo pode ser útil quando existe a necessidade de maior detalhamento nos dados das tabelas dimensões.
Definidas as tabelas, suas informações e relacionamentos, podemos então projetar a carga dos dados em cada tabela.
Processos de ETL
ETL é uma sigla para “Extract”, “Transform” e “Load”, que podemos entender conforme a tradução: “Extração”, “Transformação” e “Carregamento”.
Extraçã

Transformação: os dados são tratados, de maneira que todos tenham o mesmo padrão, que foi estabelecido na modelagem do DW. É comum que dados com origens distintas possuam diferentes padrões, estejam repetidos, possuam informações desnecessárias, dentre muitas outras possibilidades.
Carregamento: os dados devidamente tratados são carregados no Data Warehouse, cada um em seu devido local.
Staging Area
Todo processo de ETL pode acontecer de uma só vez, sendo que no momento do tratamento dos dados eles existem apenas em tempo de execução, não sendo armazenados. Esta abordagem pode levar a alguns problemas, principalmente quando o processo envolve grandes volumes de dados.
Uma solução muito utilizada é a Staging Area, que nada mais é do que uma área de armazenamento temporário, de maneira que, após serem extraídos, os dados são salvos em um banco de dados sem receber nenhum tratamento.
A etapa de tratamento usa os dados a partir deste banco, e após o devido carregamento dos dados já tratados no DW, eles podem ser deletados desta área intermediária.
ETL em produção
Após a def
Para quem analisa os dados, quanto mais atuais, melhor será, porém pode não ser uma tarefa simples e viável estabelecer que este processo aconteça a cada 15 minutos.
Em muitos casos, um processo completo de ETL pode levar horas. É comum as empresas ajustarem o processo para acontecer nas madrugadas, aproveitando que neste período o consumo de recursos de seus sistemas costuma ser menor, e garantido que a cada manhã os dados do último dia estejam prontos para análises.
Cubos
Aqui utilizam
Os cubos OLAP (Online Analytical Processing) recebem esse nome pelo fato dos dados possuírem uma organização semelhante a um cubo, com informações agregadas por dimensões e um fato, sendo facilmente localizadas respostas a partir da intersecção das dimensões.
Hoje podemos enxergar esta etapa como sendo a análise efetiva dos dados, que podem ser facilmente consultados no DW, levando as respostas que o dashboard deve exibir.
Para esta finalidade, podemos utilizar ferramentas poderosas, como as linguagens R e Python, realizando análises das mais diferentes formas, conforme a nossa criatividade permitir, inclusive utilizando modelos de machine learning para além de conhecer o passado, prever como o futuro será, utilizando todo poder da Ciência de Dados para isso.
A utilização de linguagens de programação comuns na Ciência de Dados em processos de BI ainda está em crescimento, mas vem ganhando espaço a cada dia, inclusive com a possiblidade de sua integração com os principais softwares de BI que veremos na sequência.
Finalizadas as análises e encontradas as repostas e insights esperados, podemos partir para última etapa: a visualização dos dados, que abordamos no início da conversa.
Principais ferramentas de BI
Como acabamos de perceber, o processo de BI envolve diferentes etapas, podendo ser executado por diferentes ferramentas.
Algumas linguagens de programação poderiam ser utilizadas em todas elas, com a aplicação de apenas uma ferramenta em todo processo. Isto seria possível, mas extremamente trabalhoso.
Existem ferramentas específicas que realizam seu trabalho com excelência, e de maneira simples, em cada uma das etapas. Vamos mencionar algumas destas:
- Linguagem SQL: linguagem de programação para banco de dados. De fácil aprendizado, a linguagem SQL é muito utilizada na criação do Data Warahouse, sendo aplicada em alguns casos para ETL. É possível ainda utilizá-la para análise dos dados, realizando consultas no DW, mas para esta finalidade outras ferramentas são mais fáceis e poderosas.
Foco em ETL:
- IBM DataStage
- Informática PowerCenter
- ODI – Oracle Data Integrator
- Pentaho Data Integration
Foco nas análises e visualizações:
Estas ferramentas têm foco no usuário final, utilizando o conceito de self-service BI, que busca possibilitar a qualquer usuário, mesmo aqueles com pouco conhecimento de análises de dados, gerar suas próprias visualizações, de maneira simples, sem código, com apenas alguns cliques.
Apesar dessa proposta abrangente, elas continuam poderosas, com muitas possibilidades para usuários experientes, inclusive podendo ser integradas com linguagens como Python e R em alguns casos.
- Microsoft Power BI
- Tableau
- QlikSense
As chamadas metodologias ágeis (Agile) também estão incorporando cada vez mais o BI.
A necessidade de velocidade faz com que ferramentas de visualização que tragam insights rapidamente sejam muito valorizadas dentro das empresas.
Muitas vezes, a esperança de agilidade se concentra na organização dos processos, mas quando o Agile não é suficiente para mudar uma cultura corporativa, talvez esteja sendo necessário voltar os olhos para mais tecnologia.
Esteja preparado
Conforme mencionamos no começo do artigo, muitas empresas já incorporaram seus setores de BI ao de Ciência de Dados.
Hoje conhecer apenas os processos e ferramentas de Business Intelligence não é mais suficiente. Precisamos estar em constante atualização, e na área de dados, o que há de mais atual é a Ciência de Dados, principalmente através do machine learning.
Como estudar BI
A melhor forma de estudar BI é colocando em prática todos os conceitos aprendidos na teoria, realizando muitos exercícios e imaginando que informações podem enriquecer a análise de colaboradores de diferentes áreas.
Para tanto, uma ótima forma de começar é por meio do curso Power BI com machine learning, que preparamos exclusivamente para quem está iniciando no setor.
Leituras recomendadas:
- “Agile Data Warehousing” (Ralph Hughes)
- “When Agile isn’t enough” (Wayne Eckerson)
Confira também os artigos: