


Esta biblioteca dispõe de ferramentas simples e eficientes para análise preditiva de dados, é reutilizável em diferentes situações, possui código aberto, sendo acessível a todos e foi construída sobre os pacotes NumPy, SciPy e matplotilib.
Uma das melhores opções para aplicação prática de machine learning é através da linguagem Python.
Um dos fatores que trás destaque a linguagem são justamente suas bibliotecas e pacotes, que proporcionam muita simplicidade as aplicações, além de garantir scripts descomplicados e eficientes. Dentre estes pacotes, temos o NumPy e o Pandas como os principais para a preparação dos dados, e o scikit-learn, ou apenas sklearn, sendo o mais utilizado para efetiva criação de modelos de machine learning.
Principais aplicações
O sklearn está organizado em muitos módulos, cada um desenvolvido para uma finalidade específica. Nestes módulos encontraremos funções para as mais diferentes aplicações.
Analisando estas diferentes aplicações entenderemos a organização da biblioteca, e como encontrar o que buscamos.
- Pré-processamento – normalmente esta é a etapa mais trabalhosa no desenvolvimento de um modelo de machine learning. Como já vimos, o NumPy e o Pandas são largamente utilizados nesta etapa, mas também teremos funções para esta finalidade no sklearn, pensadas especialmente para tratamento de dados que alimentarão algoritmos de machine learning.
- Classificação – desenvolvimento de modelos capazes de detectar a qual categoria pré-determinada um elemento pertence. Podemos identificar se um aluno foi reprovado ou aprovado, se uma pessoa possui ou não determinada doença, ou ainda qual doença uma pessoa pode ter dentre várias possíveis, dentre muitas outras possibilidades.
- Regressão – desenvolvimento de modelos que podem atribuir um valor contínuo a um elemento. Podemos prever o preço de um imóvel, altura de uma pessoa, quantidade de vendas de um produto, e assim por diante.
- Clusterização – desenvolvimento de modelos para detecção automática de grupos com características similares em seus integrantes. Podemos identificar clientes com comportamentos parecidos, grupos de risco de determinada doença, verificar padrões entre moradores de uma cidade, e muitos outros agrupamentos.
- Redução de dimensionalidade – reduzir o número de variáveis em um problema. Com esta redução podemos diminuir consideravelmente a quantidade de cálculos necessários em um modelo, aumentando a eficiência, com uma perde mínima de assertividade.
- Ajuste de parâmetros – comparar, validar e escolher parâmetros e modelos, de maneira automatizada. Podemos facilmente comparar diferentes parâmetros no ajuste de um modelo, encontrando assim a melhor configuração para a aplicação em questão.
Modelo de Regressão linear com sklearn
Para entender o funcionamento da biblioteca na prática, vamos utilizar algumas funções simples para criar uma massa de dados, e um modelo de regressão linear. Caso você queira conhecer um pouco mais sobre a teoria por trás deste modelo antes seguirmos com o script, confira o vídeo abaixo:

Nosso primeiro passo será gerar os dados. Para essa finalidade temos a função make_regression(), que faz parte do módulo datasets do sklearn. Neste link você pode conferir a documentação da função.
O sklearn é muito bem documentado, e você sempre poderá conferir os detalhes de suas funções através do site oficial da biblioteca.
Neste exemplo iremos criar uma massa de dados com 200 observações, com apenas uma variável preditora, que será a variável x e a variável target, que será a y. Para isso indicamos os parâmetros n_samples = 200 e n_features = 1.
O parâmetro noise define o quão dispersos os dados estarão um dos outros. Quanto maior este valor, maior a dispersão. Fiquem a vontade para testarem valores maiores, observando o efeito na criação da regressão.
from sklearn.datasets import make_regression
# gerando uma massa de dados:
x, y = make_regression(n_samples=200, n_features=1, noise=30)
Neste momento a melhor forma para visualizarmos os dados existentes nas variáveis x e y que acabamos de criar é através de um gráfico. Para isso utilizaremos o pacote matplotlib, com o módulo pyplot e a função scatter(), que criará o gráfico, e função show() que o exibirá na tela.
import matplotlib.pyplot as plt
# mostrando no gráfico:
plt.scatter(x,y)
plt.show()
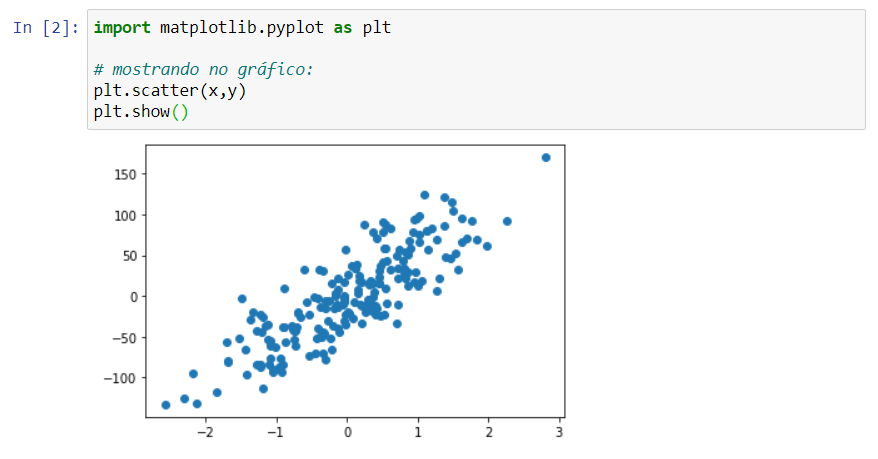

Com os dados gerados, já podemos iniciar a criação de nosso modelo de machine learning. Para isso utilizaremos o módulo linear_model, e a função LinearRegression().
from sklearn.linear_model import LinearRegression
# Criação do modelo
modelo = LinearRegression()
Após esta execução, o objeto modelo que acabamos de criar está pronto para receber os dados que darão origem ao modelo. Como não indicamos nenhum parâmetro específico na função, estamos utilizando suas configurações padrão.
Agora precisamos apenas apresentar os dados ao modelo, e para isso temos o método fit(). Na documentação da função podemos conferir todos os métodos que ela possui.
modelo.fit(x,y)
Após esta etapa, nosso modelo de machine learning está pronto e podemos utilizá-lo para prever dados desconhecidos. Simplificando este primeiro entendimento, vamos apenas visualizar a reta de regressão linear que o modelo gera, com os mesmos dados que criaram o modelo. Para isso iremos utilizar o método predict(), indicando que queremos aplicar a previsão nos valores de x.
O resultado do método será uma previsão de y para cada valor de x apresentado.
modelo.predict(x)
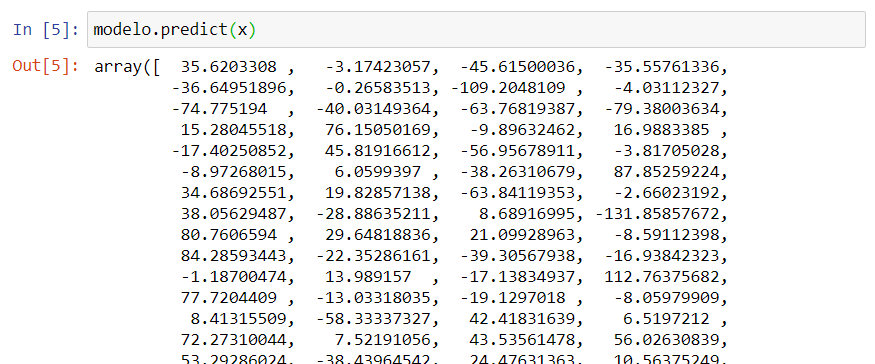

Como podemos ver, estes valores soltos não nos dizem muito. Precisamos analisá-los de outra forma. Neste caso, uma boa opção é através da reta de regressão que eles geram. Poderíamos utilizar os atributos coef_ e intercept_ do modelo, sendo eles respectivamente o coeficiente angular e linear de nossa reta, e com estes valores visualizá-la em um gráfico, porém existe uma opção ainda mais simples.
A função plot() do pacote pyplot gera uma reta com os dados apresentados. Como já temos os dados de x e y, basta indicá-los na função. Assim, primeiramente montamos novamente o gráfico de x e y original com a função scatter(), e somamos a ele a reta de regressão criada a partir dos valores de x, e dos valores previstos de y. Para melhorar a visualização estamos indicando que a cor da reta será vermelha, e aumentando sua espessura.
plt.scatter(x,y)
plt.plot(x, modelo.predict(x), color='red', linewidth=3)
plt.show()
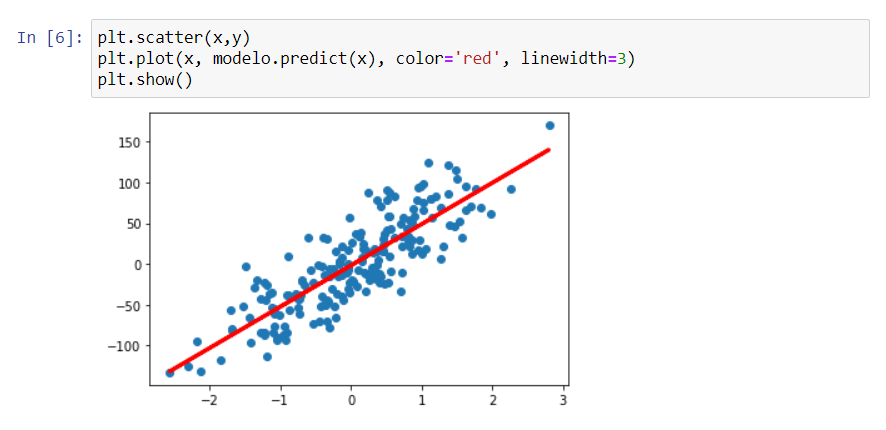

Esta é a reta que melhor se ajusta aos dados existentes no gráfico, e foi gerada através do modelo de regressão linear que criamos. Com ela podemos prever qualquer valor de y sabendo o valor x.
Machine learning com Python
Se você pretende continuar aprendendo os detalhes de Python para Machine Learning, assim como a teoria por trás de cada algoritmo, confira aqui nosso curso completo – módulo I. Com muita didática, sem deixar nenhum detalhe passar, avançamos nesta tecnologia que a cada dia se torna mais importante em nossas vidas.
Confira também: