
No machine learning, as máquinas são capazes de aprender. Isso significa que a resposta para determinado problema será o resultado desta aprendizagem, e não um código pré-estabelecido que um programador detalhou.
Um dos principais ramos do machine learning é o Deep Learning, que como o próprio nome sugere, realiza uma aprendizagem profunda, com várias camadas de processamento, através das Redes Neurais Artificiais, que buscam um comportamento similar ao do cérebro humano.
Redes Neurais
De maneira simplificada, podemos enxergar uma rede neural como uma estrutura que conecta pequenas unidades, os neurônios, de forma organizada. Através desta organização, a combinação das operações unitárias simples realizadas por cada neurônio levará a soluções de problemas complexos.
O cérebro humano
Essa estrutura é inspirada no cérebro humano, que possui redes neurais biológicas. O cérebro humano possui cerca de 86 bilhões de neurônios, sendo que cada um destes neurônios realiza cerca de sete mil conexões (sinapses) com outros neurônios. Analisando estes valores percebemos a complexidade que envolve nossos cérebros.

Os impulsos elétricos responsáveis por estas trocas de informações acontecem constantemente, sendo que quando um neurônio está enviando uma informação, dizemos que ele está “ativado”. Aquele neurônio que não está enviando um impulso elétrico está “desativado”. Esta é a mesma terminologia utilizada nas redes neurais artificiais, e um mesmo neurônio pode estar recebendo e enviando impulsos.
Por meio destas trocas de informações extremamente complexas, é possível o reconhecimento de padrões. É assim que nosso cérebro funciona. Esta imensa quantidade de combinações possibilita nosso aprendizado. É importante ainda salientarmos que nosso entendimento a respeito do cérebro humano continua superficial, existindo muitos aspectos a serem estudados e compreendidos, para que efetivamente possamos entender tudo que está por trás desta magnífica massa cinzenta.
Neurônios artificiais

Da mesma forma que em uma rede neural biológica, nas redes artificiais a grande quantidade de neurônios e conexões possibilitarão que operações individuais simples, quando somadas, levem a resoluções de problemas de grande complexidade.
História das Redes Neurais Artificiais
Apesar do Deep Learning estar em alta nos dias atuais, as redes neurais artificiais já existem há muitos anos. O primeiro paper que trata do assunto é do ano de 1943, sendo que suas ideias foram implementadas ainda em um circuito elétrico, pois não existam computadores na época.
Por volta de 1950, após a segunda guerra mundial, ainda no início da utilização dos primeiros computadores, foi quando aconteceu a primeira simulação de uma rede neural em um computador. Este experimento conduzido pela IBM, falhou, e somente 9 anos depois, em 1959 foi possível se obter sucesso em uma simulação semelhante.


Da mesma forma que a mídia exaltou a IA no início da década, alguns anos depois passou a contestar seu potencial, e assim se iniciou um período conhecido como “Inverno da IA”. Os investimentos na área caíram significativamente, levando a uma estagnação no ramo. Sem pesquisa e desenvolvimento a área acabou parando no tempo.
Este inverno sombrio durou algumas décadas, até que em 1982 John Hopfield lançou o paper “Neural networks and physical systems with emergent collective computational abilities”, dando novo fôlego para as redes neurais e a inteligência artificial. O meio acadêmico despertou novamente para o tema, algumas conferências anuais começaram a acontecer, e conceitos como o de redes neurais com múltiplas camadas surgiram.
Apesar dos avanços teóricos, na prática as evoluções não se mostraram consideráveis e os questionamentos sobre o futuro da tecnologia voltaram.

O investimento em hardware também cresceu, permitindo um aprimoramento constante das GPUs. O processamento paralelo vem evoluindo significativamente, possibilitando aplicações mais poderosas e rápidas. Deste então a importância do deep learning vem crescendo a cada ano, inclusive com a entrega de resultados práticos para diversos problemas.

Deep Learning x Redes Neurais
Mas afinal, Deep Learning e Redes Neurais são a mesma coisa? É comum que os dois termos apareçam em conjunto, e a diferença entre eles pode acabar não sendo evidenciada. Para já deixar claro, estes dois termos não são sinônimos. Conforme já mencionamos, o deep learning realiza a aprendizagem profunda, já as redes neurais podem existir com apenas uma camada de neurônios, situação em que, apesar de trabalharmos com uma rede neural, não estamos utilizando deep learning.
Redes neurais rasas
Um exemplo de rede neural rasa é aquele que possui apenas uma camada oculta. Isso significa que teremos apenas uma camada oculta de neurônios entre os dados de entrada e saída da rede.
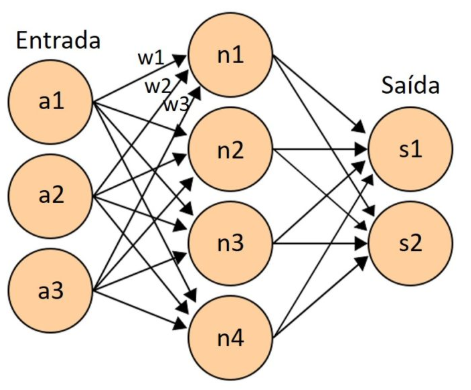

Os dados de entrada serão passados a cada neurônio da camada oculta, sendo que cada dado de entrada terá um peso específico para cada neurônio que o receber. Desta forma, teremos que o valor de cada neurônio será igual ao valor de cada dado de entrada, multiplicado pelo seu respectivo peso, somado com as demais multiplicações, e, também, com um valor constante final, chamado de bias. Obs: o vídeo recomendado no início desse artigo mostra todos esses detalhes.
Uma vez que todos os neurônios de saída tenham seus valores definidos, aquele que tiver o maior valor será o neurônio mais ativado, indicando assim que a resposta para o problema que buscamos é equivalente ao resultado que este neurônio de saída representa (em um problema de classificação). A precisão desta rede neural será definida pelo ajuste dos pesos e bias de cada neurônio.
Redes neurais profundas
Na prática, quando as redes neurais possuem muitas camadas ocultas, trata-se de deep learning. Estas camadas ocultas também são compostas por neurônios, sendo que o valor de cada um será definido da mesma forma que nas redes neurais rasas.
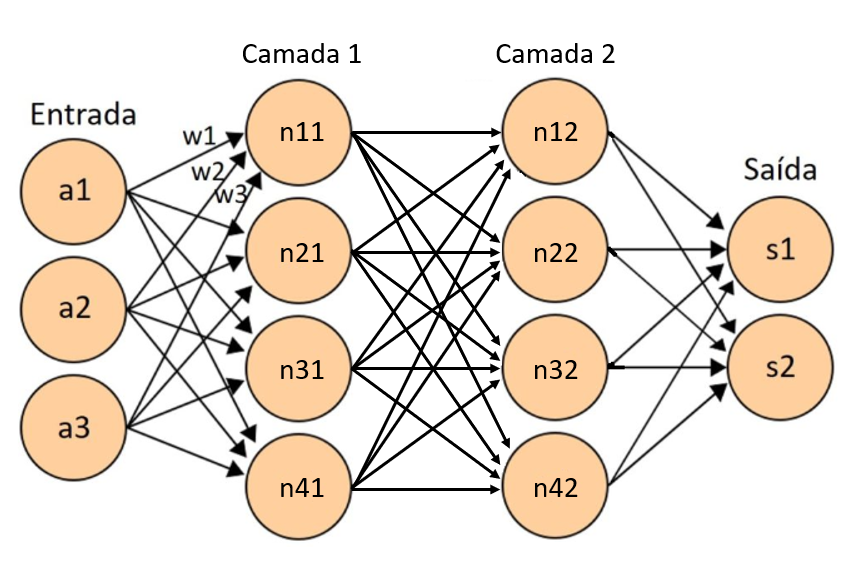

Um ponto importante a se observar é que o significado do resultado (valor) de cada neurônio existente nas camadas ocultas costuma ser obscuro, não sendo possível para nós a sua interpretação. Teremos apenas as evidências do resultado final da rede neural, que poderá melhorar ou não de acordo com a adição de mais camadas ocultas a rede.
Nas redes neurais profundas, a quantidade de cálculos será muito maior, com um número exponencial de pesos e bias a serem ajustados, e esta é sua principal vantagem. Desta forma, as possibilidades de ajustes são muitas, sendo maior a probabilidade de se encontrar uma melhor combinação de ajustes do que em uma rede neural rasa. Porém, não podemos esquecer que essa grande possibilidade de ajustes pode levar ao overfitting, sendo este um ponto de atenção.
O vídeo abaixo mostra detalhadamente como uma rede neural funciona; em cerca de 1h de vídeo você irá poupar semanas de estudo, recomendamos fortemente que assista quando puder:

Código simples em Python criando uma rede neural:
Dataset: https://didatica.tech/wp-content/uploads/2023/02/admission_dataset.csv
import pandas as pd
df = pd.read_csv(‘admission_dataset.csv’)
y = df[‘Chance of Admit ‘]
x = df.drop(‘Chance of Admit ‘, axis = 1)x_treino, x_teste = x[0:300], x[300:]
y_treino, y_teste = y[0:300], y[300:]from keras.models import Sequential
from keras.layers import Dense# Criando a arquitetura da rede neural:
modelo = Sequential()
modelo.add(Dense(units=3, activation=’relu’, input_dim=x_treino.shape[1]))
modelo.add(Dense(units=1, activation=’linear’))# Treinando a rede neural:
modelo.compile(loss=’mse’, optimizer=’adam’, metrics=[‘mae’])
resultado = modelo.fit(x_treino, y_treino, epochs=200, batch_size=32, validation_data=(x_teste, y_teste))# Plotando gráfico do histórico de treinamento
import matplotlib.pyplot as plt
plt.plot(resultado.history[‘loss’])
plt.plot(resultado.history[‘val_loss’])
plt.title(‘Histórico de Treinamento’)
plt.ylabel(‘Função de custo’)
plt.xlabel(‘Épocas de treinamento’)
plt.legend([‘Erro treino’, ‘Erro teste’])
plt.show()
Vídeo explicando o código:

Como aprender mais sobre redes neurais e deep learning
Este é um assunto que vem ganhando importância a cada dia. Explicações detalhadas e didáticas, com teoria e prática são difíceis de se encontrar, ainda mais em português.
Pensando nisso montamos uma série de cursos, onde abordamos de maneira clara e objetiva, desde conceitos básicos de machine learning, até os temas mais complexos e atuais do deep learning.
Estruturamos nossos cursos utilizando Python em 4 grandes módulos. No módulo 1 você aprenderá os conceitos básicos sobre machine learning e IA, manipulação de dados, programação, matemática e também irá utilizar seus primeiros algoritmos de machine learning na prática.
No módulo 2 você irá aprender técnicas e algoritmos avançados de machine learning, ainda sem precisar trabalhar com processamento paralelo.
No módulo 3 é quando mergulhamos no mundo do deep learning e visão computacional, frameworks e processamento paralelo em GPU.
No módulo 4 abordamos tópicos como processamento de linguagem natural, GANs, aprendizado por reforço, sistemas de tradução e algoritmos genéticos.
Clique aqui e confira todos os nossos cursos!
Outros artigos que você pode se interessar:
- História das redes neurais artificiais
- Neurônios artificiais
- Introdução a Redes Neurais Convolucionais
- Redes Neurais em Problemas de Regressão
- Visão Computacional e Processamento de Imagens
- Como funcionam as Redes Neurais Recorrentes
- O que é Processamento de Linguagem Natural (NLP)
- Aplicação de Algoritmos Genéticos em Redes Neurais
- Frameworks na prática das redes neurais
- O que é TensorFlow
- O que é Keras
- Processamento Paralelo e GPU para Deep Learning
- Diferenças entre CPU e GPU
- Quando utilizar GPU para Deep Learning