Para um bom entendimento sobre o funcionamento dos sistemas de tradução, vamos conferir um exemplo prático. Abaixo temos uma frase em português e, na sequência, a mesma frase em inglês:
“De acordo com vários autores”
“According to several authors”
Podemos, de imediato, verificar que há diferenças significativas entre elas, como por exemplo, a quantidade de palavras. Uma frase traduzida para outro idioma não terá, necessariamente, a mesma quantidade de palavras; o que nos leva a nosso primeiro problema, pois não podemos fixar um tamanho específico da entrada e dizer que esse será o mesmo tamanho da saída, considerando a quantidade de palavras.
Encoder e Decoder
Neste caso, precisamos utilizar um sistema de encoder/decoder, onde temos um número de entradas que será diferente do número de saídas: o tamanho da entrada X não será, necessariamente, igual ao tamanho da saída Y; a saída Y pode ser maior ou menor do que a entrada X. Então, como podemos resolver esse problema?
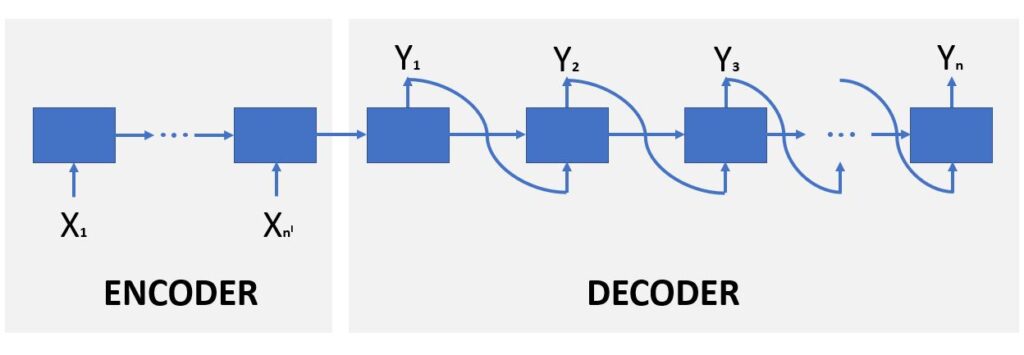
Na rede neural recorrente acima, temos as entradas sendo utilizadas em cada caixa no encoder, assim como acontece em uma LSTM, por exemplo, como vemos em detalhes na arquitetura e no empilhamento de LSTMs.
Mas em nossa rede atual, quando chegamos na primeira caixa do decoder, não temos somente um estado passando para a próxima caixa, mas também uma saída Y que é utilizada como entrada para a próxima LSTM – a próxima entrada no próximo time step – gerando outra saída que, por sua vez, será utilizada como entrada na sequência da estrutura.
Dessa forma, visto que cada saída é utilizada como entrada para um próximo time step, podemos ter quantas caixas quisermos. Poderemos definir o tamanho da saída Y, conforme nossa necessidade, com quantas caixas forem necessárias; porque as entradas no decoder não estão dependendo da entrada X do encoder.
Não é cada entrada X que está resultando numa saída Y, pois as entradas estão sendo as próprias Y anteriores. Essa é a diferença básica e a topologia usada para sistemas de tradução.
Como, então, podemos entender o problema de tradução existente entre uma frase em português que passa a ser uma frase em inglês? Como a frase é utilizada na entrada e como se dá o processo em relação ao encoder e decoder que acabamos de ver?
Lidando com Probabilidades na saída do decoder
Podemos pensar na solução, utilizando a lógica de probabilidades.
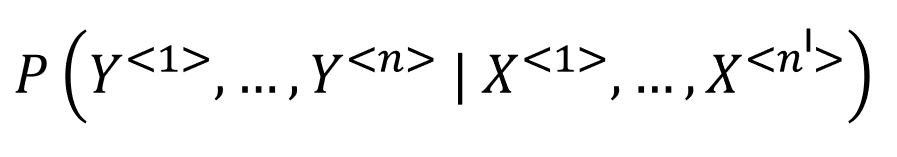
Temos toda uma entrada X que é o X¹, X² até Xnˡ; sendo que cada palavra representa um time step específico até um Xnˡ, que será o tamanho de nossa entrada X. Então, há nˡ palavras e estamos interessados em saber qual é a probabilidade da nossa saída – da sentença Y – que representa o Y¹, o Y² até o Yn (aqui estamos utilizando n e nˡ porque o n não será, necessariamente, igual a nˡ).
Queremos saber, então, qual é a probabilidade de gerar uma sentença Y, de um tamanho específico, em relação à nossa entrada X que tem outro tamanho específico.
Aqui não estamos interessados na probabilidade de uma saída Y sozinha, mas a probabilidade de uma sentença inteira de várias saídas Y. Estamos interessados na probabilidade cumulativa de todas essas saídas juntas serem a melhor tradução possível, considerando, inclusive, a ordem das palavras, dado que a barra utilizada na equação, no caso de uma probabilidade, significa uma condição.
Então, qual a probabilidade de uma saída específica, dado que temos uma entrada específica.

A nossa rede neural vai tentar maximizar o resultado da maior probabilidade, resultando na sentença que tem a maior probabilidade de saída, considerando a entrada informada.
Esse é o nosso objetivo com o sistema de tradução: encontrar qual é a sentença que tem a maior probabilidade de ser a melhor tradução para uma outra sentença que foi indicada na entrada.
E para essa sentença de saída, podemos imaginar que existem muitas combinações possíveis. Como elas podem ter diferentes tamanhos, podemos traduzir uma frase usando diferentes palavras.
Pode-se utilizar uma tradução direta de palavra a palavra ou combinar duas palavras e agrupá-las numa palavra só, dentre outras combinações possíveis.
No próprio inglês temos, por exemplo, os phrasal verbs – palavras em que uma só palavra representa duas palavras em português, ou vice-versa. Então a rede neural precisa considerar todas essas situações, buscando encontrar a sentença completa que melhor traduz a sentença em outro idioma.
Palavra por palavra?
Conforme estamos destacando, é importante observar que não existe uma comparação palavra por palavra, não havendo uma saída específica para cada palavra na entrada.
O sistema não buscará traduzir uma palavra para depois traduzir a outra, e assim por diante. É evidente que dessa forma a tradução não teria muita qualidade, dado que os idiomas não têm uma correspondência direta, palavra a palavra.
Por este motivo se utiliza esta alternativa muito mais genérica: uma sentença inteira que irá gerar outra sentença inteira.
E como isso acontece na prática? Existem várias técnicas que podem ser aplicadas neste problema: podemos utilizar greedy Search, técnicas opostas ao greedy search, ou ainda opções que computacionalmente nos garantem velocidade, como beam search.
Em nosso Curso Aprendizado por Reforço, Algoritmos Genéticos, NLP e GANs vemos em detalhes tanto a teoria quanto a prática necessárias no desenvolvimento de um sistema de tradução, sempre focando no aprendizado do aluno, com didática e objetividade.
É um curso imperdível onde você vai aprender tudo que há de mais avançado no mundo do deep learning!
Leia também:
- A evolução dos Sistemas de Tradução
- O que é Processamento de Linguagem Natural (NLP)
- Como funcionam as Séries Temporais
- Introdução a Redes Neurais e Deep Learning
- O que são Redes Neurais Recorrentes
- Processamento Paralelo e GPU para Deep Learning
- Todos os artigos sobre inteligência artificial e ciência de dados
