
Após o entendimento inicial sobre dados temporais, podemos iniciar a análise da arquitetura de uma rede neural recorrente.
O desenho abaixo mostra uma rede neural recorrente de forma bem simples, com dois neurônios de entrada, três neurônios na camada oculta, e dois neurônios na saída, além de três neurônios posicionados abaixo dos demais, na camada oculta.
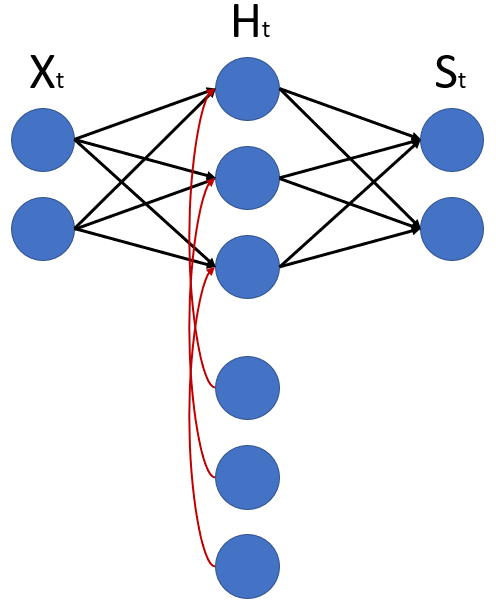

Os nomes são o “X” da entrada, o “H” é a camada oculta e o “S” é a saída. Podemos reparar que foi colocado o índice “t” em cada um desses neurônios, tanto a entrada quanto a camada oculta, ou a saída têm o índice “t” porque para cada entrada que estivermos colocando essa entrada corresponde a um momento de tempo.
Podemos falar, por exemplo, do tempo 1: quando o “t” é igual a 1 estamos entrando com uma entrada que vai passar pela camada oculta e teremos uma saída no tempo 1; depois, no tempo 2 esses dois neurônios de entrada receberão valores no tempo 2 e, consequentemente, passarão esses valores para a camada oculta, e terão uma saída no tempo 2; e assim por diante.
Até aqui não há nenhuma novidade em relação ao que aprendemos nas redes neurais densas e, por enquanto, está tudo muito parecido! Uma diferença que pode ser notada no desenho é que os neurônios da camada oculta não estão recebendo apenas os dados da entrada, mas, também, dos outros neurônios mais abaixo.
O restante é igual: todos os neurônios de entrada compartilham informação com todos os neurônios da camada oculta que compartilham informações com todos os neurônios de saída.
Nesse ponto não há nenhuma novidade! Mas os neurônios do meio não recebem valores somente da entrada anterior, recebem de um outro lugar também. Essa é a grande diferença das Redes Neurais Recorrentes para uma Rede Neural Densa, totalmente conectada.
Que neurônios são estes? De onde está vindo essa informação?
Essa informação está vindo da própria camada oculta: a camada de cima está enviando informação para a camada de baixo; e esta é a grande diferença!
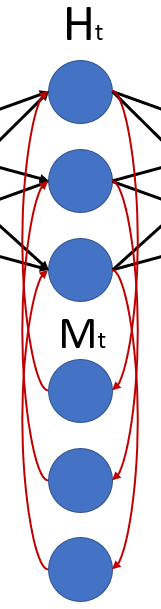

Pensando na primeira entrada do tempo 1 – ela passa informação para a camada oculta (vamos imaginar que não há nada na parte de baixo do desenho, apenas os 3 neurônios de cima) e a camada oculta vai passar as informações recebidas para a saída.
Nenhum mistério nesse primeiro momento. Só que a camada oculta não passou apenas para a saída, passou também para os três neurônios M.
Então, essa camada oculta está enviando para dois lugares: para a saída e para essa outra camada abaixo, que chamaremos de “M”, de memória.
Na próxima iteração, no tempo “t=2”, teremos outra entrada X que passará informação para a camada oculta e, agora, a camada oculta receberá informação não somente da entrada, mas também da camada “M”.
Nesse momento, a camada “H” vai calcular, com base não somente na entrada, mas, também, nos seus valores do próprio “H” do tempo anterior. Em outras palavras, podemos dizer que o “Mt” é igual ao “Ht-1”, ou seja, a nossa camada “Mt” é igual ao nosso “Ht” do tempo anterior.
Essa que é a grande diferença aqui! Se estamos falando do tempo anterior (t-1), estamos falando da iteração anterior, os dados que entraram imediatamente anteriormente aos dados atuais.
Separando cada momento de tempo
Se formos pensar em cada momento de tempo, podemos reparar que a saída está recebendo valores sempre somente dessa camada “Ht”; nesse momento o “St” está sendo calculado com base no “Ht”.
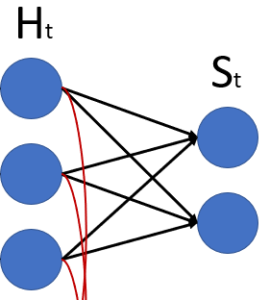

Pensando na iteração no Tempo 2 – quando temos um X2 – e vamos ter um H2 e um S2, o “H2” será calculado com base no X2 e, também, no H1, porque o “Mt” equivale ao Ht-1.
Então, há duas entradas que estão influenciando sempre a camada “Ht”. É a entrada “Xt” mais o “Ht-1” da iteração anterior.
Por isso que colocamos três neurônios na camada “M”. Tínhamos três neurônios na camada oculta, que são os mesmos que estão abaixo (no desenho) – os neurônios da iteração anterior – os mesmos valores que eles vão assumir serão replicados na camada “M”, vão aguardar um clock, uma próxima iteração, um próximo tempo, para serem transmitidos de volta.
Realimentação cumulativa
O que está acontecendo é que, sempre, as iterações estão sendo replicadas e realimentadas para a rede de forma cumulativa. Afinal, como o “Ht” está sendo influenciado pela entrada e, também, pelos seus valores anteriores, esses valores, por sua vez, foram formados pela entrada anterior e o “Ht” anterior.
Esses valores anteriores carregam dentro de si uma informação de todo o histórico, se formos pensar, porque ele carrega informação do “Xt” anterior e do “Ht” anterior. Só que o “Ht” anterior também carregava informações do “Xt” anterior ainda, e do “Ht” anterior ainda; e aquele “Ht” anterior tinha também informações do “Xt” anterior.
Então, de forma cumulativa essas informações estão sempre sendo salvas na memória “Mt”, que vai retroalimentar o nosso “Ht”.
Essa é a arquitetura e a estrutura de uma Rede Neural Recorrente. Se entendemos este assunto, entendemos a parte principal de uma Rede Neural Recorrente!
Quer aprender mais sobre redes neurais recorrentes?
Clique aqui e conheça nossos cursos, temos opções gratuitas e completas, para iniciantes e também para aqueles que já dominam estes conceitos mas desejam se especializar ainda mais, avançando na teoria e prática.
Trabalhamos bastante com redes neurais recorrentes no módulo 4 de nossos cursos de machine learning e deep learning. Nesse curso, estudamos não apenas a teoria, mas também muita prática em problemas reais de séries temporais, que vão desde bolsa de valores até processamento de linguagem natural. Imperdível!
Leia também: