As redes neurais convolucionais – CNN (“Convolutional Neural Networks”) são diferentes das redes neurais densas, ou totalmente conectadas.
As CNN’s não são totalmente conectadas, não tendo a ligação completa de todos os neurônios como acontece com as redes neurais densas.
Arquitetura de uma CNN
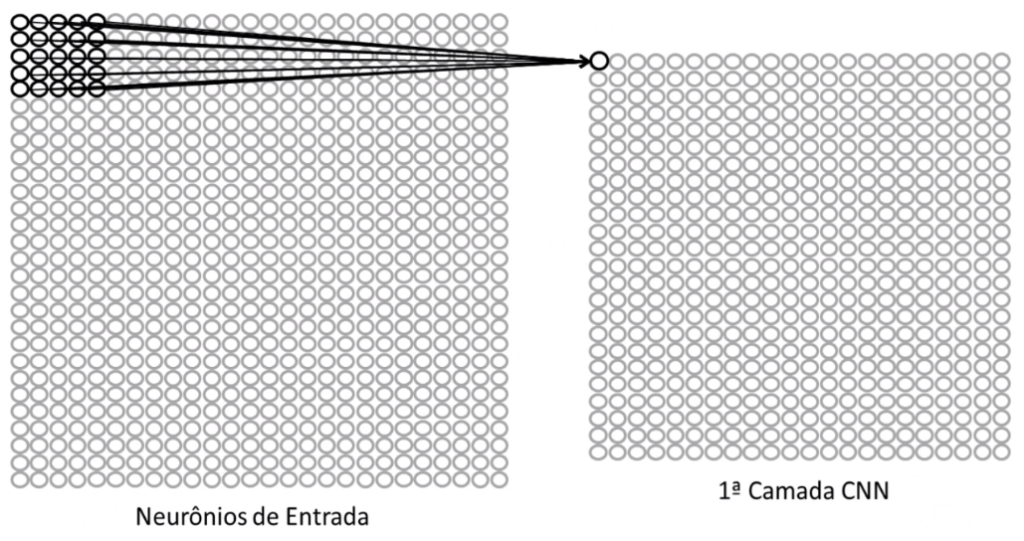
No exemplo acima este conceito fica evidente, pois existem 784 neurônios de entrada, cada um representando um pixel de uma imagem, mas apenas 25 deles estão conectados com um neurônio da primeira camada.
Em uma rede neural densa, todos os 784 neurônios de entrada estariam conectados com cada um dos neurônios da primeira camada.
Neste exemplo de rede neural convolucional, o neurônio seguinte da primeira camada oculta também estará conectado a 25 neurônios de entrada, porém de forma deslocada (sem os 5 neurônios da primeira coluna e com os 5 da próxima, que no caso é a sexta coluna).
Observe a imagem abaixo para ficar mais claro:
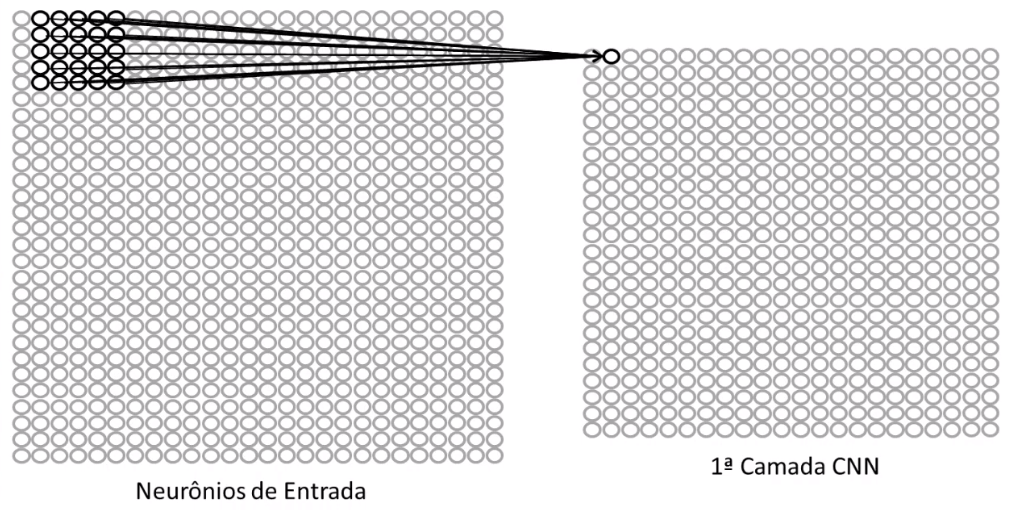
Este processo se repetirá, avançado para a direita, coluna a coluna, e para baixo, linha a linha, até que a totalidade dos neurônios de entrada esteja conectada a ao menos um neurônio da primeira camada.
Finalidade das Redes Neurais Convolucionais
As redes neurais convolucionais foram criadas para resolverem uma tarefa específica: o reconhecimento de imagens, que são problemas de visão computacional.
As redes neurais densas são úteis para problemas de propósito geral, e podem ser usadas, praticamente, para qualquer situação. Já as CNN’s funcionam majoritariamente para reconhecimento de imagens.
As redes neurais totalmente conectadas também podem ser usadas para reconhecimento de imagens. No entanto, elas têm algumas limitações para essa finalidade de reconhecimento de imagens. Vejamos uma ilustração disso: vamos imaginar que há um gato bem no centro de uma figura grande.

Se queremos reconhecer que isso é um gato, ou seja, se passarmos essa figura para a rede neural informando que a classe é gato, e passamos uma nova imagem onde esse gato está localizado em outra região da figura:

Para a rede neural totalmente conectada, essas duas figuras são completamente diferentes uma da outra. Apesar das duas serem um gato, ela não vai enxergar isso logo de cara; ou seja, se ela aprendeu com apenas uma das figuras (com o gato no centro), e mostramos uma nova figura em que o gato não está mais no centro, a rede neural não consegue entender que aquilo é um gato.
Ela terá que aprender de novo, compreendendo novamente que se trata de um gato, repetindo todo o processo, completamente do zero.
Visão da Rede Neural Densa
E por que são vistas como figuras completamente diferentes, se é a mesma figura de um gato apenas deslocada? Porque, nas redes neurais totalmente conectadas, cada neurônio da rede está aprendendo especificamente aquele pixel que está entrando.
Cada um dos neurônios terá um número de 0 a 1 – se for uma escala de cinza – e se houver mais cores serão mais três dimensões, uma para cada cor. Mas pensando numa escala mais simples como a de cinza, cada pixel, ou cada neurônio de entrada, terá um valor entre 0 e 1, e se o gato estiver deslocado (se a figura de entrada estiver deslocada), significa que são outros neurônios que estarão aprendendo aquela figura.
Porque se a figura está deslocada, o neurônio que antes estava aprendendo que uma parte da figura (o olho ou o bigode do gato, por exemplo), deixou de aprender isso e passou a aprender outra coisa da figura por conta do deslocamento existente.
Então, cada um dos neurônios está aprendendo coisas diferentes para cada figura de entrada, se elas estiverem um pouco deslocadas. É como se fosse uma figura completamente nova.
Como resolver este problema?
Como é possível então para uma rede neural conseguir aprender que se entramos com um gato, não importando se ele estiver no centro, se estiver deslocado, ou até mesmo se ele estiver um pouco cortado, o que existe ali é um gato? Como ela pode entender que já viu essa figura antes, mesmo que em posição diferente?Como ela reconhecerá que é um gato, mesmo que noutra posição, ou mesmo apenas partes dele? É exatamente para isso que as redes convolucionais foram criadas!
As CNNs funcionam como se cada retângulo que varre a figura (como vimos anteriormente) fosse uma espécie de filtro. Esse filtro tenta extrair alguma característica da figura. Podemos ter um filtro que se especializou em identificar bigode de gato.
Outro filtro reconhece o olho esquerdo. Outro filtro reconhece parte do rabo. E assim por diante. Uma CNN geralmente possui vários filtros, todos varrem a mesma figura, mas possuem pesos e bias diferentes.
Após varrer uma figura, cada filtro cria uma nova camada de neurônios, a chamada feature map, que como o próprio nome diz, representa um mapa de características. Na prática, esse mapa aponta onde a característica que o filtro está procurando foi encontrada.
Dessa forma, mesmo que o gato de nosso exemplo esteja deslocado, os filtros irão encontrar as partes do gato, afinal cada filtro varre a figura inteira de forma independente.
Depois, em outra camada, um conjunto de neurônios será responsável por unir as peças dos feature maps criados, para concluir do que se trata a figura.
Aqui estamos fazendo uma pequena introdução, mostrando as limitações das redes neurais densas totalmente conectadas para este tipo de problema e explicando o conceito básico das CNNs.
A arquitetura das redes neurais convolucionais começou a crescer em popularidade, por serem muito poderosas e especialistas para esse tipo de problema de reconhecimento de imagens.
Especialização das Redes Neurais Convolucionais
Existiam algumas competições para reconhecimento de imagens em vários países, para estimular o avanço e pesquisa no ramo de redes neurais, e, até certo ponto, esses problemas de reconhecimento de imagens e visão computacional eram resolvidos com redes neurais densas completamente conectadas, com leves variações em sua arquitetura.
A primeira vez que a arquitetura de uma rede neural convolucional foi usada por alguma equipe participante acabou lhe dando a vitória na competição de machine learning relacionada ao reconhecimento de dígitos. A partir de então, na competição do próximo ano, todos os primeiros lugares usaram redes convolucionais.
Partindo desta situação, em qualquer concurso ou competição que seja na fronteira da tecnologia para tentar ver a melhor performance possível para o reconhecimento de imagens, os primeiros colocados, nesse âmbito, sempre estão ligados à arquitetura de redes neurais convolucionais. Isto porque realmente ela se mostrou ser mais poderosa para esse tipo de problema.
Aqui mostramos um problema específico, onde uma rede neural especialista foi de encontro ao problema em questão e o resolveu. Este sucesso se dá justamente em função desta especialização. Como temos vários problemas diferentes no mundo real, temos arquiteturas que acabam funcionando melhor e são mais eficientes para determinados problemas.
É claro que essa arquitetura que resolve bem um problema não será útil para um problema completamente diferente! Então, as redes neurais completamente conectadas têm a vantagem de poderem ser usadas em qualquer problema, não sendo, dessa forma, as mais específicas para aquilo, mas são bem generalistas e conseguem resolver uma grande gama de questões e problemas.
Agora, se estamos falando de um problema específico, limitado a uma esfera específica, podemos usar uma arquitetura mais específica, mais voltada para ele e, assim, teremos uma performance ainda melhor.
Redes Neurais Convolucionais na prática
Para colocar em prática estes conceitos, tanto em redes neurais densas, quanto em convolucionais, confira nosso curso Redes Neurais, Deep Learning e Visão Computacional.
Nesse curso abordamos a teoria completa necessária para o entendimento dos conceitos, e também a prática detalhada, de maneira que mesmo aqueles que não possuem boa base de programação possam entender e utilizar esses recursos avançados.
Além disso, também abordamos com mais profundidade a teoria por trás das CNNs, de maneira que você possa entender como funciona todo o processo de aprendizagem da rede, desde a entrada de uma imagem até a saída do modelo.
Ao todo, temos cursos de machine learning e inteligência artificial divididos em 4 módulos usando python, indo do básico até o avançado. Clique aqui e confira.
Artigos relacionados:
