Talvez ao ou vir o termo aprendizado de máquina (em inglês machine learning) você imagine algo com uma complexidade muito grande. É verdade que existem alguns assuntos complexos nesse ramo, mas o entendimento básico é muito simples, e a utilização da tecnologia também.
vir o termo aprendizado de máquina (em inglês machine learning) você imagine algo com uma complexidade muito grande. É verdade que existem alguns assuntos complexos nesse ramo, mas o entendimento básico é muito simples, e a utilização da tecnologia também.
Vamos iniciar prestando atenção no nome “machine learning”, ou seja, uma máquina que aprende.
O ato de aprender significa que o computador não receberá uma lista de instruções do que fazer em cada situação, ele receberá apenas algumas informações iniciais e terá que aprender o restante por conta própria.
Machine Learning é uma das maiores áreas dentro da Inteligência Artificial e também da Ciência de Dados. Então vamos entender melhor o que é isso:
A diferença entre aprendizado e lista de instruções
Imagine que uma pessoa esteja aprendendo a andar de bicicleta. Não seria muito útil passar uma lista de instruções como “incline o corpo nessa direção”, “vire nesse sentido quando a bicicleta estiver nessa posição”, etc.
O ser humano, nesse caso, aprende melhor com a tentativa e erro. A pessoa pedala e cai, pedala novamente e cai novamente, agora para o lado contrário do primeiro tombo, pois ela entendeu que precisa tentar se equilibrar, e mais do que entender teoricamente, ela começou a praticar.
Após algumas (ou muitas) quedas, ela enfim saberá andar de bicicleta, sem nunca precisar seguir um “manual de instruções” gigantesco.
Esse é o principal conceito que você precisa entender sobre o aprendizado de máquina, pois a ideia é muito semelhante a este exemplo que acabamos de citar. Vamos agora apresentar uma situação real de aprendizado de máquina para você compreender como isso se aplica no mundo da programação de computadores:
Computadores que aprendem são superiores
Antes do machin e learning ser aplicado ao xadrez, em 1997, um programa de computador conseguiu vencer uma partida de xadrez contra o melhor jogador humano da época.
e learning ser aplicado ao xadrez, em 1997, um programa de computador conseguiu vencer uma partida de xadrez contra o melhor jogador humano da época.
Por ser um jogo de grande complexidade, com muitas possibilidades, o conjunto de instruções necessárias é gigantesco e o programa em questão possuía essas instruções em sua memória, que atreladas a um grande poder de processamento possibilitava a simulação de muitas jogadas a frente em um curto espaço de tempo, levando o computador a vitória.
Nos dias atuais, não há mais comparação entre os melhores jogadores de xadrez e os melhores programas, pois os programas conseguem jogar muito melhor.
O computador consegue vencer mesmo iniciando o jogo com algumas peças a menos.
Estamos falando aqui de um computador que segue uma lista gigante de instruções sobre o que fazer em cada situação. Esse computador sabe as regras de xadrez, as estratégias, os conceitos, possui milhares de partidas armazenadas na memória, análises de posição, etc.
Mas em 2017 a empresa Dee pMind (do Google) desenvolveu um programa para jogar xadrez utilizando machine learning. Este programa não recebeu nenhuma instrução sobre estratégias ou melhores jogadas.
pMind (do Google) desenvolveu um programa para jogar xadrez utilizando machine learning. Este programa não recebeu nenhuma instrução sobre estratégias ou melhores jogadas.
A única informação que o programa recebeu foram as regras do jogo, nada mais.
Sabendo as regras do jogo, o programa jogou contra si mesmo inúmeras vezes, e a cada nova partida ele aprendia com os erros e acertos da partida anterior.
Desta forma, sem que o programa conhecesse estratégias desenvolvidas pelo homem, ele aprendeu a jogar sozinho e desenvolver suas próprias estratégias.
O resultado deste aprendizado não poderia exemplificar melhor o poder do aprendizado de máquina: ao jogar contra o melhor programa de computador atual, as vitórias do computador que utilizou aprendizado de máquina foram avassaladoras.
Um marco na Ciência da Computação, evidenciando a superioridade do aprendizado de máquina x instruções pré-estabelecidas.
Isso é muito empolgante, mas para explicar o processo do machine learning é melhor retroceder um pouco.
Como a máquina aprende?
Vamos entender como isso funciona com um exemplo mais simples. Imagine que você é um médico e está interessado em classificar seus pacientes como “saudáveis” ou “doentes”.
Para cada paciente, você possui um conjunto de dados (informações) como: altura, peso, pressão arterial, nível de colesterol, percentual de gordura, entre outros.
Você já possui um histórico muito grande de pacientes com seus respectivos dados e classificações como saudáveis ou doentes, e quer utilizar um algoritmo de machine learning para aprender com esses dados de maneira que, quando você receber os dados de um novo paciente, o algoritmo possa dizer se ele está saudável ou doente.
Então como isso vai funcionar? Você irá alimentar o algoritmo de machine learning com os dados históricos já classificados (entenda que estamos interessados aqui na classificação entre saudável ou doente).
A partir destes dados, o algoritmo de machine learning irá aprender quais condições são necessárias para o paciente ser classificado como saudável e quais condições classificam o paciente como doente.
Essa etapa o algoritmo irá fazer sozinho, você não precisa fazer nada além de alimentar os dados no programa e colocar a função para rodar (essas funções de algoritmos de machine learning já estão prontas e você pode solicitá-las com comandos simples de programação).
Existem diferentes algoritmos de machine learning que poderiam resolver esse problema, mas não vamos nos prender a esses detalhes agora. A figura abaixo ilustra bem esse processo:

Repare que agora, como saída desse processo, temos um modelo já treinado. Em outras palavras, temos um modelo que já aprendeu a relação dos dados (quais características classificam um paciente como doente ou saudável).
Então já podemos utilizar esse modelo para realizar previsões sobre novos dados. Podemos alimentar o modelo treinado com as informações de novos pacientes e o modelo irá prever se cada um desses pacientes é saudável ou doente:

Mas como saberemos se essas previsões que o algoritmo irá fazer estão corretas ou não? Podemos testar o modelo antes para saber o quão confiável ele é!
Dados de treino e dados de teste
Imagine que, em vez de utilizar todos os nossos dados históricos para treinar o modelo, utilizamos apenas 80% desses dados e separamos os outros 20% para servirem como teste depois (esses 20% são dados o modelo não irá receber para treinar).
A lógica é a seguinte: se o modelo conseguir fazer previsões corretas sobre os dados de teste, significa que o modelo está funcionando bem.
Esses dados de teste também são dados históricos, ou seja, já estão classificados, então basta comparar as previsões do modelo com as respectivas classificações para ver se ele acertou ou errou nas suas previsões:
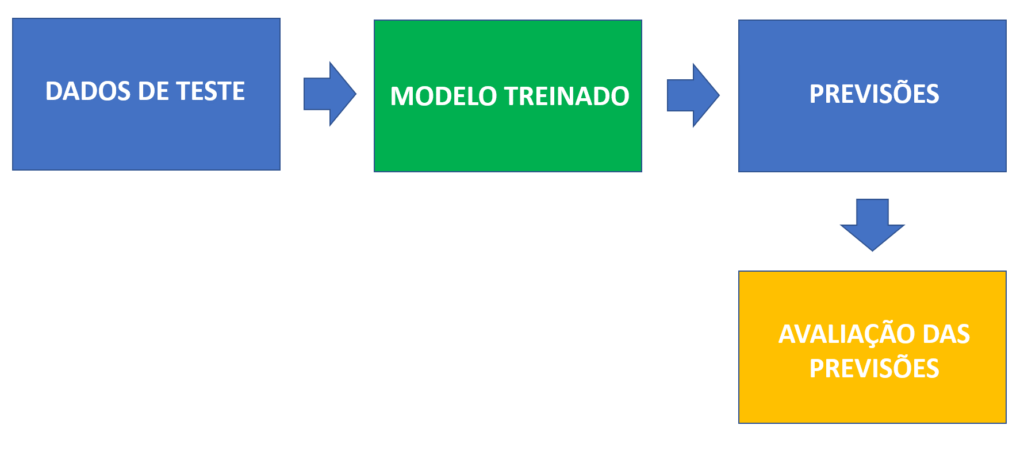
Basicamente, esse é o importante conceito de dados de treino e dados de teste.
Problemas de classificação e de regressão
Acabamos de utilizar aqui um exemplo de classificação, pois o resultado final é a previsão de uma classe. Outros exemplos de problemas de classificação poderiam ser: classificação dos alunos entre aprovados ou reprovados, classificação de clientes em categorias (A, B, C, D), classificação de cogumelos como comestíveis ou não comestíveis, etc.
Problemas de regressão, por outro lado, não preveem uma classe e sim um resultado numérico. Por exemplo: previsão do preço de imóveis, previsão da densidade dos materiais, previsão da quantidade de gols que um time de futebol irá fazer em uma partida, etc.
Um cientista de dados precisa primeiro reconhecer se o problema se trata de classificação ou de regressão, para depois tomar a decisão de qual algoritmo de machine learning utilizar.
Aprendizado supervisionado ou não supervisionado
O aprendizado supervisionado ocorre quando o modelo aprende a partir de resultados pré-definidos. Em nosso exemplo do médico, os resultados eram as classes e o modelo precisava aprender a relação dos dados para fazer uma correta classificação.
O mesmo poderia ter ocorrido com problemas de regressão, onde o modelo iria aprender a partir de resultados numéricos para fazer depois previsões de novos resultados numéricos. Isso tudo é considerado aprendizado supervisionado, pois o modelo possui uma referência daquilo que está certo e daquilo que está errado.
Aprendizado não supervisionado ocorre quando não existem resultados pré-definidos para o modelo utilizar como referência para aprender. Por exemplo, você apresenta para o modelo um conjunto de dados com várias informações sobre plantas (como comprimento do caule, cor da folha, espessura da raiz, etc.) e pede para o modelo separar esses dados em 5 categorias.
Nesse caso, você não especificou para o modelo o que caracteriza cada categoria, o modelo irá sozinho tentar encontrar semelhanças e diferenças entre os dados de maneira que essa separação em 5 categorias seja a melhor possível.
Como não há uma referência (ou critério específico) para o modelo seguir, define-se que esse aprendizado é não supervisionado.
Ok, conseguimos entender até aqui o que é o aprendizado de máquina e vimos também alguns conceitos básicos. Se você está se perguntando como fazer isso na prática utilizando programação, saiba que é mais simples do que parece!
Como programar machine learning
Podemos utilizar Python, Linguagem R, ou outras linguagens de programação para trabalhar com machine learning.
Na maior parte das vezes, você utilizará bibliotecas e frameworks prontos para utilizar os algoritmos de aprendizado de máquina, então a programação será bastante facilitada. Não é preciso ter medo.
Como estudar machine learning?
Muitas pessoas possuem interesse em machine learning, mas não sabem a melhor forma de aprender. Alguns recomendam dedicar meses de estudo de matemática primeiro, depois meses de estudo de programação, para então iniciar o aprendizado de máquina.
Essa abordagem não é eficiente. Ao estudar assuntos de matemática desconexos das aplicações, a compreensão fica debilitada, bem como a motivação.
Outro ponto negativo de separar esse estudo por blocos independentes é que, quando finalmente você estiver iniciando no aprendizado de máquina, os tópicos de matemática e programação já estarão nublados, por ter passado muito tempo desde que você estudou aqueles assuntos.
Portanto a melhor forma de aprender machine learning é focar em um algoritmo de cada vez. Para cada algoritmo, estude a matemática e a teoria por trás do algoritmo, e logo em seguida estude a programação da implementação desse algoritmo.
Dessa forma, é possível aprender machine learning rapidamente, unindo teoria e prática.
Essa é a abordagem que utilizamos em nossos cursos. Se você é iniciante e gostaria de começar do zero, a melhor sugestão é iniciar com o curso de machine learning com python – módulo I.
Se por acaso você tem mais interesse na linguagem R, pode iniciar com este curso.
É preciso saber muita matemática para dominar o machine learning?
Existem diferentes abordagens no estudo de machine learning. Não é necessário ser um especialista em matemática para entrar nesse ramo. Inclusive, é possível ter apenas noções básicas gerais sobre o funcionamento dos algoritmos sem precisar mergulhar em cálculo e estatística.
A etapa prática do machine learning, que envolve programação, é bem simples e não requer matemática.
Um bom resumo sobre o que é machine learning pode ser aprendido também nesse vídeo:
Como aprender mais
Focando principalmente na simplicidade e didática, montamos o curso Introdução a Machine Learning, totalmente gratuito, que irá fornecer os primeiros passos para realmente compreender e dominar esta fascinante tecnologia.
Criamos aqui alguns tutoriais gratuitos super práticos e didáticos para você dominar os conceitos essenciais de programação para machine learning, começando do zero:
- Python para Iniciantes
- Python para Machine Learning e Análise de Dados
- Linguagem R para iniciantes
- Linguagem R para Machine Learning e Análise de Dados
Você pode conhecer todos os nossos cursos nessa página. Aproveite, pois dificilmente você irá encontrar um material tão detalhado e explicativo.
Qualquer pessoa pode aprender machine learning, não é algo de outro mundo. Iremos mostrar todos os detalhes para você aprender se divertindo!
Leia também:
