
Underfitting e Overfitting são dois termos extremamente importantes no ramo do machine learning. No artigo sobre dados de treino e teste vimos que parte dos dados são usados para treinar o modelo, e parte para testar o modelo, verificando assim se ele está bom ou não.
Um bom modelo não pode sofrer de Underfitting nem de Overfitting, por isso precisamos entender estes conceitos, e saber identificar suas ocorrências.

Overfitting
Um cenário de overfitting ocorre quando, nos dados de treino, o modelo tem um desempenho excelente, porém quando utilizamos os dados de teste o resultado é ruim.
Podemos entender que, neste caso, o modelo aprendeu tão bem as relações existentes no treino, que acabou apenas decorando o que deveria ser feito, e ao receber as informações das variáveis preditoras nos dados de teste, o modelo tenta aplicar as mesmas regras decoradas, porém com dados diferentes esta regra não tem validade, e o desempenho é afetado. É comum ouvirmos que neste cenário o modelo treinado não tem capacidade de generalização.
Underfitting
Neste cenário o desempenho do modelo já é ruim no próprio treinamento. O modelo não consegue encontrar relações entre as variáveis e o teste nem precisa acontecer. Este modelo já pode ser descartado, pois não terá utilidade.
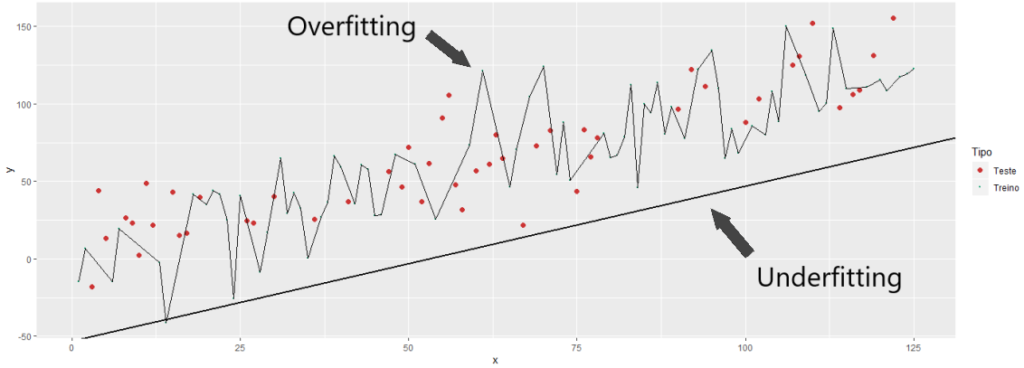
Vamos entender estes conceitos com exemplos práticos e visuais. Na figura abaixo vemos uma distribuição de dados entre as variáveis x e y. Consideremos que estes são os dados que temos a nossa disposição para treinar e testar o modelo.
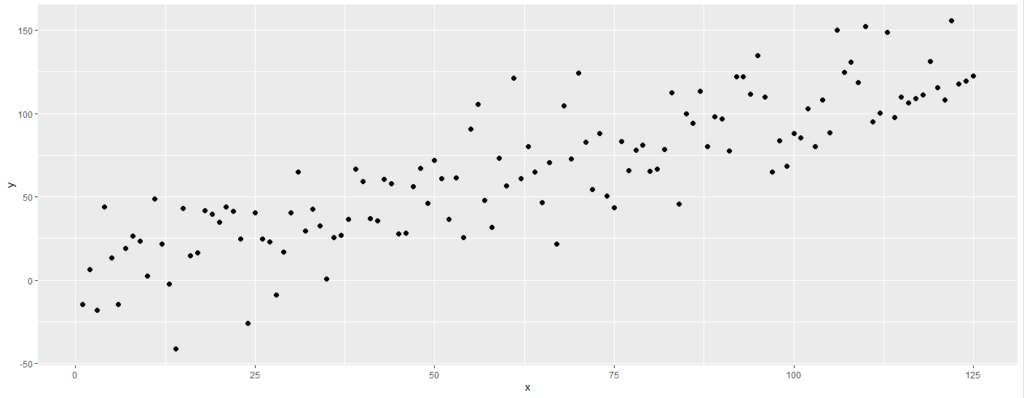

Nosso objetivo é traçar uma linha por estes pontos, de maneira que se recebermos um novo valor de x, por exemplo, possamos prever o valor de y. Poderíamos utilizar alguns algoritmos de manchine learning para traçar esta reta ou curva, utilizando como base todos estes pontos, porém sabemos que precisamos de dados de teste para medir o desempenho dos modelos criados.
Com esta finalidade, separamos os dados em treino e teste, conforme vemos na imagem abaixo:
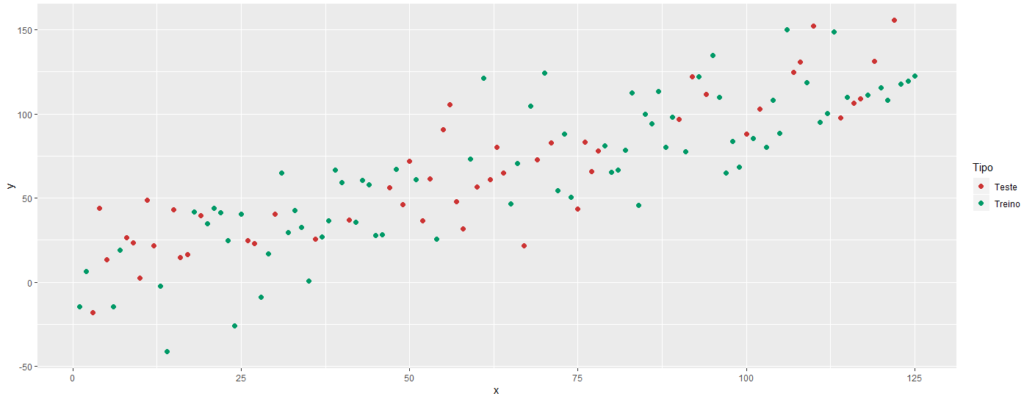

Podemos então utilizar os dados de treino, que estão em verde na imagem, para treinar nosso modelo, e obtermos algumas linhas que expliquem o relacionamento destes dados.
Na imagem abaixo vemos uma primeira tentativa, onde o modelo nos retorna uma reta distante dos dados de treino:
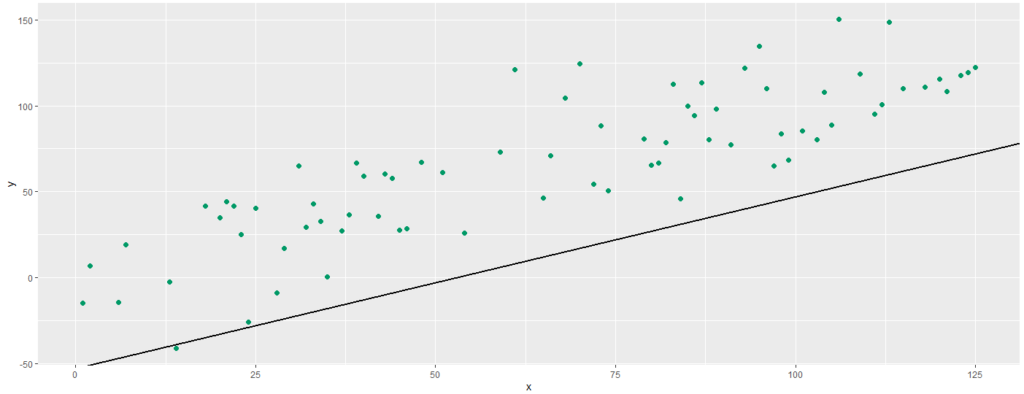

Este é um típico caso de Underfitting, onde o algoritmo não encontra uma boa relação entre os dados, e com isso o resultado apresentado nos dados de treino é ruim. Esta reta não precisa nem mesmo ser aplicada aos dados de teste, devido a seu fraco desempenho.
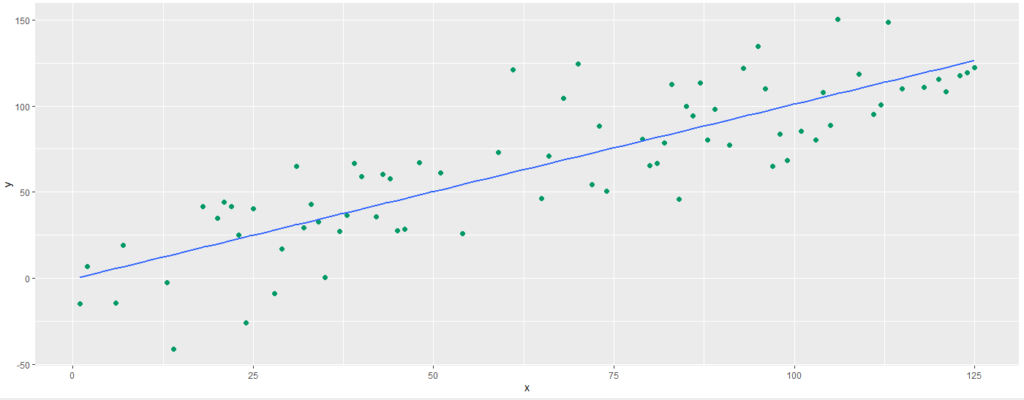
Na próxima tentativa temos como resultado a reta abaixo, que está bem ajustada aos dados, acertando com precisão alguns poucos pontos, porém obtendo constantemente um baixo erro na previsão.
A reta em questão foi gerada através de uma regressão linear, e, portanto, é a reta que melhor se adequa a estes dados:

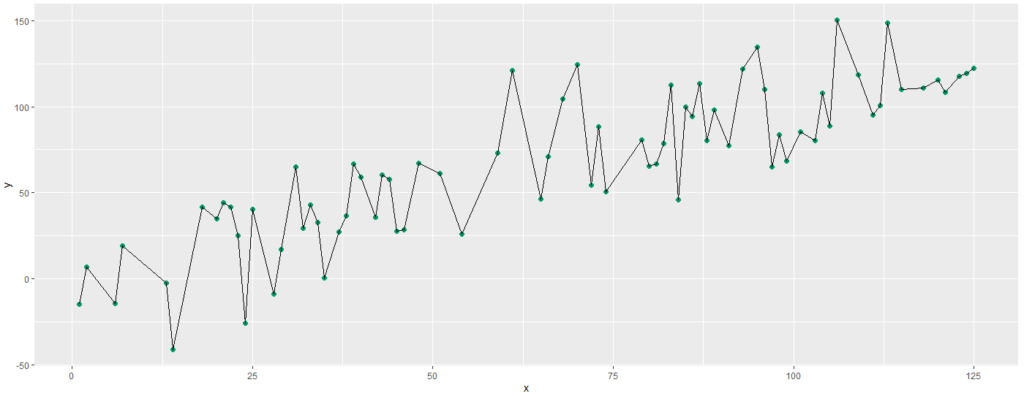
Realizamos ainda mais uma tentativa, tendo como resultado a imagem abaixo. Agora nossas previsões estão perfeitas, sendo que a linha traçada passa por todos os pontos do gráfico, não havendo assim erro algum.
Porém não podemos esquecer que ainda estamos apenas treinando nosso modelo, e ele pode estar sofrendo de Overfitting. Precisamos testá-lo em dados desconhecidos, que são os dados de teste que foram separados inicialmente.

Abaixo vemos a aplicação dos três modelos nos dados de teste:
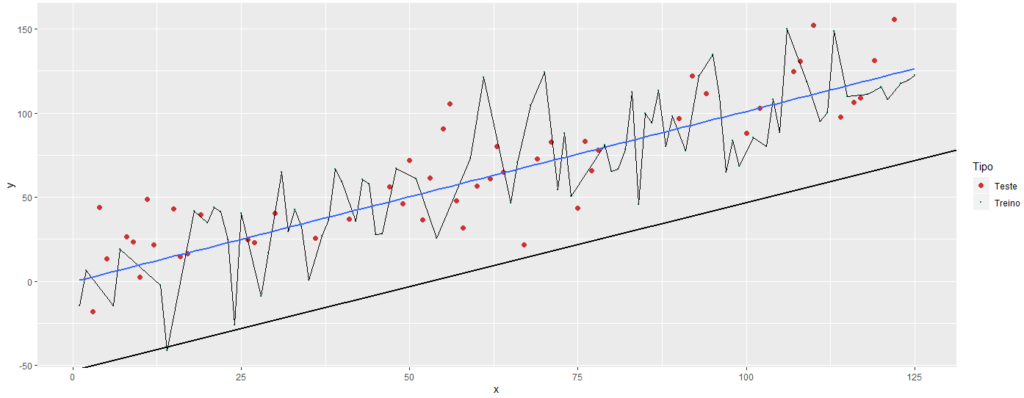
Com este gráfico fica evidente que a reta inicial não pode ser utilizada, conforme já havíamos concluído. Porém agora percebemos que as previsões perfeitas que tínhamos antes, não existem mais.
Nosso último modelo estava sim sofrendo de Overfitting, pois quando ele é aplicado aos dados de treino, seu desempenho é drasticamente afetado, passando a ter muitos erros, e ainda erros grosseiros.
É provável que calculando o coeficiente de determinação R2 dos dois modelos finais, encontremos um melhor resultado nos dados de teste do modelo intermediário, pois ele continua posicionando sua reta em uma posição relativa aos dados de teste muito parecida com a que tinha nos dados de treino, mantendo seus erros em valores baixos, diferentemente do que acontece com o modelo que sofre de Overfitting.
Continue seu aprendizado
Entender os conceitos abordados neste artigo é fundamental para um sólido conhecimento de machine learning e inteligência artificial. Porém existem muitos assuntos que precisam ser analisados.
Para isso, montamos o curso de machine learning com Python – módulo I (também temos esse mesmo curso na versão com linguagem R), onde ensinamos os principais conceitos do machine learning e utilizamos algoritmos na prática resolvendo problemas reais.
Esse curso foi feito para iniciantes, começando do zero, com foco no aprendizado do aluno, utilizando uma didática que você dificilmente encontrará em outro lugar.
Ali você vai praticar bastante os conceitos de underfitting e overfitting, procurando sempre por modelos que consigam ser generalistas o bastante para apresentar bons resultados com dados novos.
Também temos opções de cursos mais avançados, você pode conferir todos os nossos cursos aqui.
Leia também outros artigos: