
Um dos maiores objetivos de quem trabalha com machine learning é ter um modelo que faça boas previsões sobre os dados coletados; obtendo, assim, uma melhor performance ao utilizar os seus algoritmos.
Então, para tanto, falaremos nesse artigo sobre as funções RandomizedSearchCV e GridSearchCV, ambas integrantes da biblioteca scikit-learn, largamente utilizada para machine learning com Python.


A GridSearchCV faz todas as combinações possíveis dos parâmetros que lhes foram passados na hora de fazer o ajuste fino do modelo; enquanto a RandomizedSearchCV faz apenas uma quantidade específica e limitada de combinações aleatórias, e nós é que determinamos quantas iterações queremos que sejam feitas: se determinamos que o algoritmo faça vinte combinações, por exemplo, ele fará apenas vinte.
Ou seja, ele escolherá vinte combinações aleatórias, e não fará nada além disso.
Qual é a melhor?
A pergunta que devemos fazer é: “Qual dessas duas funções é a melhor para fazer o ajuste fino dos parâmetros?”. Talvez a nossa tendência seja olhar e dizer: “É a GridSearchCV, afinal ela testará todas as combinações possíveis; enquanto a RandomizedSearchCV não testará todas: poderia ser que houvesse uma ou outra configuração de parâmetros que fosse a ideal, mas a RandomizedSearchCV simplesmente não as verificou porque nós limitamos as iterações que ela faria!”.
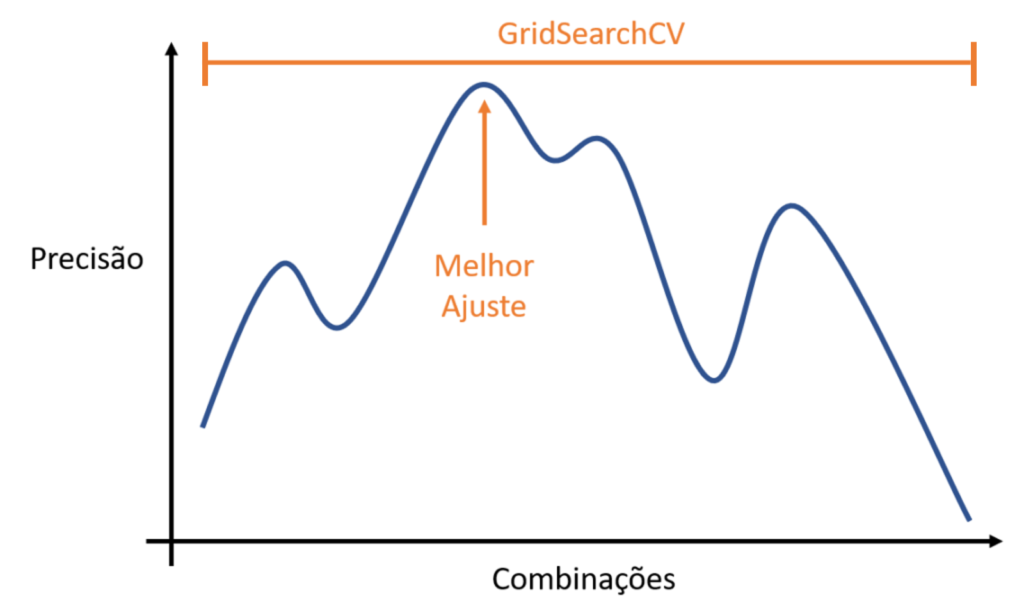

Mas esta não seria uma comparação justa, porque o correto seria fazer a seguinte pergunta: “Qual dessas duas funções é melhor, considerando o mesmo custo computacional?”.
Agora, sim, se está fazendo justiça, porque é evidente que a GridSearchCV fará mais combinações, mas, no entanto, ela terá um custo computacional maior. Se passarmos os mesmos parâmetros para uma função e para outra, e definirmos uma quantidade de iterações menores na RandomizedSearchCV, é evidente que ela acabará mostrando um resultado um pouco inferior, pois talvez não faça a melhor combinação.
Mas, por outro lado, ela também terá um custo computacional menor; o que será uma vantagem, sendo que quanto menor o custo computacional, menos energia se gasta e o resultado é obtido mais rapidamente.
A RandomizedSearchCV tem essa vantagem do tempo. Existem muitas discussões e vários estudos para se tentar definir qual é a melhor, e boa parte dos pesquisadores defende que uma função como a RandomizedSearchCV é, muitas vezes, a melhor opção.
Aplicando o mesmo número de iterações
Para entendermos o porquê, faremos uma comparação simples: vamos imaginar que temos três parâmetros com valores diferentes para informar ao algoritmo, os quais queremos variar.
Vamos informar quatro valores diferentes para o primeiro parâmetro, quatro valores para o segundo e quatro para o terceiro. Então, usaremos a função GridSearchCV, que combinará cada um dos quatro valores para cada um desses três parâmetros. Ao todo, nós teremos quatro vezes quatro, vezes quatro (4 x 4 x 4); ou seja, sessenta e quatro (64) combinações diferentes de parâmetros para esse algoritmo que será rodado.
Já, para a RandomizedSearchCV , usando os mesmos três parâmetros do exemplo acima, poderíamos passar, por exemplo, sete valores para o primeiro, sete para o segundo e sete para o terceiro. Assim, teríamos mais de trezentas (300) combinações possíveis sendo feitas.
No entanto, podemos limitar o RandomizedSearchCV para fazer, no máximo, sessenta e quatro (64) iterações. Assim, ambos os algoritmos farão sessenta e quatro (64) iterações – o GridSearchCV fará sessenta e quatro (64), e o RandomizedSearchCV também.
Dessa forma, eles terão o mesmo custo computacional, mas com uma diferença: o GridSearchCV vai variar todas as combinações possíveis – aqueles quatro valores para cada um dos três parâmetros –, enquanto o RandomizedSearchCV escolherá sessenta e quatro (64) iterações dentro de um espectro total, de mais de trezentas (300) combinações possíveis.
Observe abaixo uma ilustração do RandomizedSearchCV:
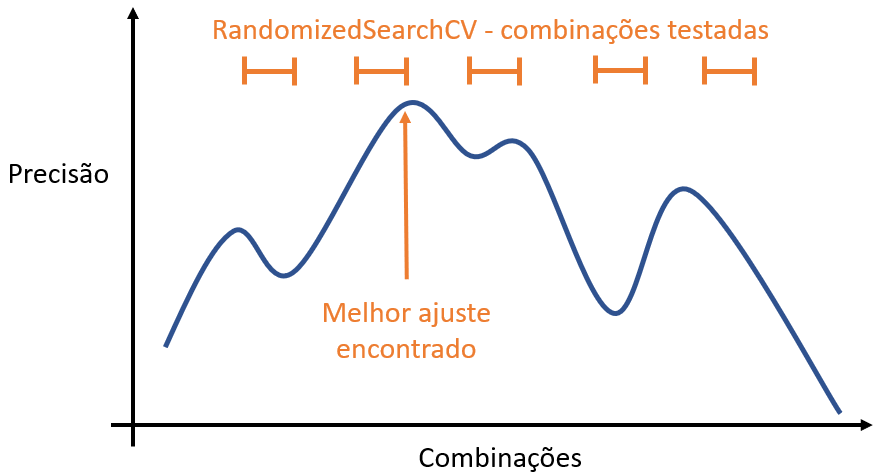

Mesmo que o GridSearchCV seja mais detalhado nas combinações, ele olhará para um espectro bem mais restrito também. Vamos imaginar que nós temos duas variáveis – um eixo x e y –, sendo que as combinações dessas duas variáveis fazem uma curva no plano xy.
Então, essa curva tem alguns fundos e alguns topos, e queremos descobrir os pontos que tenham uma performance mais alta – os topos. Quando pegamos o GridSearchCV, delimitamos um espaço menor e vemos todas as combinações possíveis nesse espaço; assim, talvez estejamos em alguns dos topos, mas não no maior topo possível.
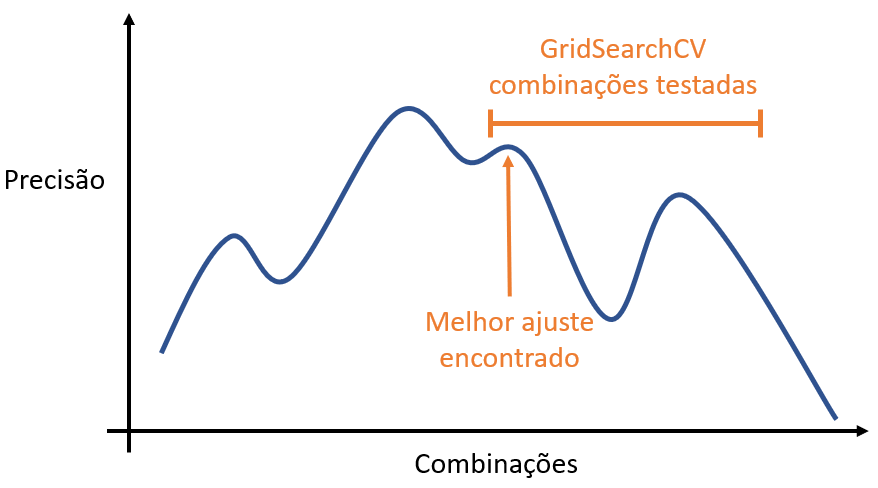

Nessa tentativa de ver qual a melhor combinação nesse espectro pequeno, numa largura bem restrita, estamos vendo qual o ponto mais alto naquele pequeno espectro; ou seja, enquanto o RandomizedSearchCV pegou um espectro bem mais largo de variações, o GridSearchCV pegou um espaço menor e, assim, viu bem mais pontos, mais combinações; já o RandomizedSearchCV pegou um espaço maior, escolhendo alguns pontos ali.
No caso de haver vários topos, o RandomizedSearchCV que pegou vários pontos de um espectro maior acabou conseguindo capturar o maior topo. Isto porque ele foi pegando alguns pontos aleatórios nesse grande espectro e, assim foi marcando pontos altos e pontos baixos, definindo, assim, qual o topo máximo de todas as combinações possíveis para esse algoritmo.
Comparando essa primeira rodada ao GridSearchCV, percebe-se que ele viu corretamente qual o melhor ponto, mas se limitou ao espetro menor ao qual ele foi restringido, enquanto, no outro lado, em parâmetros bem diferentes que não lhe foram informados, houvesse um topo mais alto não visto por ele pelo fato dele ter sido restringido a verificar esse espetro menor.
Como começar?
Por isso há essa variação entre os dois; e é importante termos isso em mente ao compará-los: um pode receber uma quantidade maior de parâmetros e, devido a isso, iterações limitadas para não ter um custo computacional muito elevado.
Com isso ele poderá fazer combinações maiores, podendo capturar pontos de vales ou de topos na função. Então, uma dica importante para se definir qual deles usar é começar usando o RandomizedSearchCV, passando o maior número de parâmetros e informações possíveis a ele, fixando quantas iterações queremos – que serão menores que a quantidade total –, até porque se quisermos fazer todas as variações usaremos o GridSearchCV! Para fazer um número limitado de iterações, variando muitos parâmetros, podemos passar vários valores para cada um deles, limitando a quantidade de iterações usando o RandomizedSearchCV.
A partir disso podemos verificar qual foi a melhor combinação de parâmetros de tudo o que foi escolhido.
Agora, então, podemos pegar o GridSearchCV para uma nova rodada que vai variar valores mais próximos. Vamos imaginar que estamos usando o algoritmo Adaboost, por exemplo, para saber qual o melhor learning rate para uma quantidade específica de estimadores do Adaboost, e não sabemos como começar; então passamos vários valores de learning rate possíveis: 0.95, 0.9, 0.85, 0.8, 0.75, 0.7, etc., usando o RandomizedSearchCV, limitando o total de interações.
Com isso, ele escolheu o valor de 0.4, por exemplo, e nós pegamos o GridSearchCV para variar mais em torno do 0.4: pegamos o 0.39, 0.38, 0.37, 0.41, 0.42, 0.43, valores bem mais próximos do 0.4, tanto para cima como para baixo. Isto porque pode ser que ele tenha usado esse espectro maior para achar um ponto bem mais próximo de um topo e, agora, com o GridSearchCV, vamos fechar a janela próxima desse topo, e fazer todas as combinações para tentar achar o seu melhor ponto.
Assim maximizamos a chance de, realmente, achar um ponto máximo do ajuste fino dos parâmetros.
Como saber quando parar?
Esse é um trabalho exaustivo pelo fato de termos que fazer várias combinações, experimentando variações: uma, duas, três, e quanto mais tempo for gasto em frente ao computador testando combinações, mais chance haverá de se achar o melhor ponto para otimizarmos nossa performance. E aqui estamos falando de um algoritmo só: fazendo tudo isso e testando todos esses valores, com apenas um algoritmo!


Agora, devemos considerar que o ideal é que seja feito tudo isso para todos os algoritmos que conhecemos. Por exemplo, no caso de um problema de classificação ou de regressão, temos que verificar quais são todos os algoritmos que podemos trabalhar.
Em nossos cursos abordamos os principais algoritmos de machine learning. Deveríamos, então, pegar cada um deles e fazer essa variação de parâmetros para, daí sim, selecionar qual foi a melhor performance; ou seja, qual foi o algoritmo que, variando esses parâmetros, conseguiu se ajustar a esse conjunto de dados específico.
O ideal seria pegar algoritmo por algoritmo, variar os seus parâmetros e, só depois disso, comparar um com o outro.
É evidente que se quisermos fazer algo mais detalhado, temos que pegar não apenas os valores padrão em cada algoritmo. Mas temos que variar esses valores de cada algoritmo, até, porque, muitas vezes os valores padrão nos dão resultados muito ruins, mas depois que fazemos o ajuste fino obtemos resultados bons.
As vezes isso acontece: começamos com resultados muito ruins com valores padrão, por estarem muito distantes do ponto ótimo e, depois, ao ajustarmos os parâmetros, vemos que para aquela combinação e para aquele conjunto de dados fica bem melhor.
Uma rodada com cada algoritmo
É interessante fazer uma primeira rodada para cada um dos algoritmos, já variando os parâmetros para ter uma noção se, de fato, aquele algoritmo vai conseguir performar um pouco melhor.
E isto vai depender do tempo que cada um tem para conseguir rodar, bem como da disposição em fazer ajustes cada vez mais finos e calibrados para cada um dos algoritmos. Mas é evidente que nem sempre temos todo o tempo necessário para fazer todas as combinações possíveis, e nem sempre dispomos de um computador veloz e adequadamente eficiente para uma resposta precisa num curto espaço de tempo.
Por isso pode ser interessante começar com alguns algoritmos que já sabemos que são um pouco mais poderosos, fazendo algumas variações em todos eles e, dentro dessas variações iniciais, o algoritmo que performar melhor poderá ser um pouco mais estressado.
Ou seja, podemos tentar encurtar um pouco o trabalho para não gastarmos tanto tempo ou, mesmo, não sobrecarregarmos nosso computador.
Às vezes, se tivermos a sorte de escolher o algoritmo certo – mesmo não sendo tão poderoso – ou selecionamos os parâmetros corretos, podemos obter, de primeira, o melhor resultado possível, sem precisar ficar variando e testando vários algoritmos por muito tempo para chegar aos mesmos resultados.
Por isso a importância de estarmos cientes de que nesse trabalho de achar a melhor performance vai muito do nosso conhecimento dos algoritmos: como variar e trabalhar os parâmetros no tempo devido e disponível, sendo que alguns são mais rápidos e outros são mais lentos.


Em nosso exercício final do Módulo 2 de Machine Learning com Python, trabalhamos bastante essa lógica de variar parâmetros e vários algoritmos diferentes.
Vamos imaginar que temos um problema e pegamos um conjunto de dados para tentarmos conseguir o melhor score possível para esse conjunto: tomamos vários algoritmos para variar parâmetros – um por um – e, embora seja um pouco cansativo e nosso computador possa levar um certo tempo na tarefa, a ideia é exercitar a habilidade de conhecer e escolher diferentes algoritmos, selecionando os que se comportarem melhor para os “estressarmos” mais, deixando de lado os menos performáticos.
Esse é um exercício interessante para nos passar a essência de que, quando nos depararmos com outros problemas, tenhamos isso em mente: se queremos uma melhor performance, temos que baixar a cabeça e testar várias combinações, separar algoritmo por algoritmo, de repente deixar o computador rodando à noite para, no dia seguinte, ver o melhor score; isso pode ser feito, se não temos uma máquina tão poderosa, ou muito dinheiro para investir num computador melhor.
Dependendo do algoritmo que for usado, o tempo usado num computador comum será maior, e temos que aprender a lidar com essas coisas e, na medida em que se trabalha mais com isso, investir num computador melhor, com um processador que tenha mais núcleos, com uma placa gráfica (GPU).
No Módulo 3 do curso de machine learning com Python, onde falamos de Deep Learning e Redes Neurais, abordamos bastante a questão do computador, aprendendo como analisar e escolher os seus componentes e configurações ideias para a ciência de dados.
Colocando em prática
Para colocar em prática todas as ideias que discutimos, confira aqui nossos cursos, totalmente voltados ao aprendizado do aluno. Você pode começar do zero, ou mesmo já partir para etapas mais avançadas. Temos opções gratuitas e completas, com muita didática e objetividade.
Leia também: