


Utilizar Python para essa finalidade é muito simples, mas antes vamos entender um pouco sobre o que é o processamento para que você tenha um panorama geral.
Pegamos aqui aleatoriamente as especificações de um processador Intel® Core™ i7 8550U apenas para mostrar como parâmetro.
O que é um processador?
Basicamente, um processador é uma CPU (Unidade Central de Processamento). Algumas das especificações importantes para sabermos o quão poderosa é uma CPU são o número de núcleos (cores) e a velocidade (clock).
Toda CPU tem um clock base e um clock turbo. O clock base é a velocidade em gigahertz (GHz) na qual a CPU consegue normalmente fazer várias operações por segundo. Há também a velocidade turbo, que é a velocidade máxima de operação da CPU. Essa velocidade será utilizada em momentos em que a demanda seja maior e que processador precise trabalhar mais rápido.
No caso deste processador Intel Core i7 que estamos analisando, o clock base é de 1,8GHz (frequência baseada em processador); o clock turbo é de 4,00GHz (frequência turbo máx).
Obviamente, a CPU não está sempre utilizando sua velocidade máxima. Dependendo da exigência que for feita sobre a máquina, ela usará uma ou outra frequência. Outra coisa importante que determina a velocidade de operação será a temperatura do processador; se ele chega a uma temperatura que excede um certo limite, ele não vai operar nessa velocidade máxima e vai voltar à velocidade mínima de base para preservar a CPU.


Aqui, podemos ver que a máquina tem 4 núcleos. Mas o que são esses núcleos? Os núcleos são quantas operações em paralelo o processador consegue fazer. Uma CPU popular possui, em geral, quatro núcleos – notebooks e desktops comuns na faixa de R$ 3.000,00 até R$ 5.000,00 (preços considerados no ano de 2022).
Geralmente, esses computadores possuem processadores de quatro núcleos somente. Para computadores de uso doméstico, esse é um bom número de núcleos para ser utilizado.


Por isso, é muito importante verificar a qual geração o processador pertence. A geração é geralmente escrita junto ao número do processador. Nesse caso, estamos analisando um processador Intel® Core™ i7 de geração 8550U.

Voltando à questão dos núcleos. Quanto mais núcleos um computador tiver, mais atividades em paralelo ele conseguirá realizar.
Entretanto, temos que considerar o seguinte: há algumas operações que não podem ser paralelizáveis. Imagine que estamos fazendo uma conta em que cada etapa depende do resultado anterior; a CPU não irá poder seguir para a próxima etapa se a anterior ainda não ocorreu. Dizemos que esse processamento é em série (ou serial). Nesse caso, o número de núcleos não fará tanta diferença.
A maioria dos programas e softwares que utilizamos no computador permitem paralelização. Em vários momentos em que estamos utilizando um programa no computador, estamos usando outro ao mesmo tempo.
Podemos estar com o navegador aberto juntamente com o Word e uma planilha do Excel, por exemplo. Nesse casos, haverá uma diferença de performance com diferentes números de núcleos; uma CPU com mais núcleos trabalhará mais rápido. Além disso, dentro de cada núcleo, o processador consegue fazer outras paralelizações, às quais damos o nome de Threads (ou tarefas). Em geral, o número de Threads será o dobro do número de núcleos.
Código em Python
Agora, sabendo um pouco mais sobre processadores e núcleos, podemos ir para o nosso código em Python. É possível que essa parte pareça mais complicada, mas siga até o fim, você verá como é simples.
Você pode utilizar o código mesmo que não conheça todos os termos ou conceitos, e caso queira entender em detalhes, confira este artigo. Comece baixando o seguinte arquivo: Admission_Predict. Esses dados irão mostrar a probabilidade de admissão de estudantes com base em algumas notas. Abra o Python e escreva o código abaixo fazendo as alterações necessárias (lembre se que as informações após o “#” são comentários e não fazem parte do código):
import pandas as pd
#entre parênteses coloque o caminho do arquivo no seu computador, o caminho abaixo é apenas um exemplo
arquivo = pd.read_csv('C:/Users/Didatica/Downloads/Admission_Predict.csv')
arquivo.drop('Serial No.', axis=1, inplace=True)Obs: para rodar os códigos que iremos informar, será necessário ter instalado o Pandas e o scikit-learn.
Para ver se o arquivo foi selecionado corretamente, escreva em uma nova célula arquivo.head(). Isso selecionará as primeiras linhas do arquivo e as mostrará na tela da seguinte forma:


Após, digite e rode o código abaixo. Isso irá separar as variáveis em preditoras e target.
y = arquivo['Chance of Admit ']
x = arquivo.drop('Chance of Admit ', axis = 1)Agora, entramos na parte da aceleração do processador, no momento da criação de nosso modelo de machine learning. É com o código abaixo que faremos isso:
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import ElasticNet
#Definindo os valores que serão testados:
valores = {'alpha':[0.1,0.5,1,2,5,10,25,50,100], 'l1_ratio':[0.02,0.05,0.1,0.2,0.3,0.4,0.5,0.8]}
#Criando diferentes modelos
modelo = ElasticNet()
procura = GridSearchCV(estimator = modelo, param_grid=valores, cv=5, n_jobs=None)
procura.fit(x,y)
#Imprimindo o resultado
print('Melhor score:', procura.best_score_)
print('Melhor alpha:', procura.best_estimator_.alpha)
print('Melhor l1_ratio:', procura.best_estimator_.l1_ratio)Essa função “GridSearchCV”, que foi utilizada no código acima, irá procurar diferentes combinações de parâmetros, criando vários modelos de machine learning diferentes, um para cada combinação de parâmetros testada.
Nesse caso, os parâmetros comparados serão alpha=0.1 e l1_ratio=0.02, alpha=0.5 e l1_ratio=0.05 e assim por diante.
Serão testadas todas as combinações; ou seja, cada valor de um parâmetro será testado com todos os valores do outro. Essas combinações serão testadas com o nosso modelo de machine learning, que nesse caso é o “ElasticNet()”. Após todos os cálculos, o teremos o melhor modelo, aquele que apresentou o melhor resultado, como podemos ver abaixo.
![]()

Ou seja, dizemos que essas operações são paralelizáveis. Assim, podemos acelerar o processamento do nossos modelos pedindo para que esse script rode com a maior quantidade de núcleos possível no nosso processador. Isso será feito com o parâmetro n_jobs (clique aqui e leia um pouca mais sobre ele), que dirá quantas operações iremos rodar em paralelo.
Para isso, após o símbolo de “=” iremos escrever o número de processadores que queremos utilizar.
No caso do código que você pode ver acima, podemos ler a palavra None na utilização do parâmetro n_jobs, que significa que o processador está rodando com apenas 1 núcleo. Você pode alterar esse valor.
No caso do processador que estamos utilizando, que tem quatro núcleos, podemos colocar qualquer valor de 1 a 4. Se você tiver um processador de 8 núcleos, pode colocar o número 8. E assim por diante. Lembre-se de que quanto mais núcleos são utilizados mas rápido será o processamento.
É possível que você não saiba que processador você tem, então será difícil saber quantos núcleos podem ser utilizados. Nesse caso, coloque o parâmetro como -1. Dessa maneira, você usará o máximo de núcleos que o processador permite.
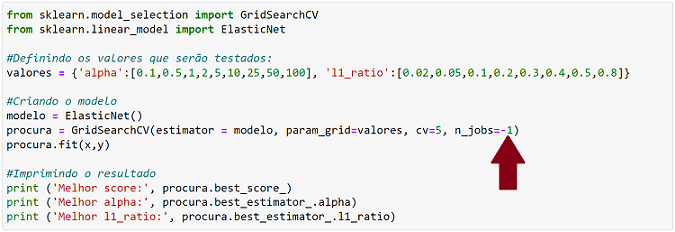

Utilizando esse código, o sistema sempre deixará um dos núcleos de reserva para que se possa fazer outras operações no computador. Ou seja, ele usará todos os núcleos menos um para fazer as operações, que ficarão mais rápidas.
Isso não significa que usando 3 núcleos em vez de 1 o computador ficará três vezes mais rápido. Por quê? Porque essa paralelização não dá um ganho de velocidade de 1 para 1. A cada núcleo que adicionamos, a velocidade vai aumentando em numa taxa cada vez menor. Esse é o efeito da paralelização.
A porcentagem de aceleração dependerá muito da qualidade do nosso processador, da sua marca, da sua geração e das suas especificações. Quanto melhor o processador mais ele conseguirá manter uma performance cada vez mais alta durante as paralelizações.
Entretanto, em geral, quando utilizamos três núcleos em vez de um, a performance será dobrada. Se tivermos quatro núcleos, que é o caso da maior parte dos processadores de uso doméstico atuais, utilizando o “n_jobs=-1”, provavelmente seu computador levará a metade do tempo que ele demoraria usando somente um núcleo.
Com códigos menores, é muito provável que essa aceleração não faça diferença. No entanto, na medida em que você for aprofundando seus conhecimentos na área de machine learning e na programação, começando a utilizar algoritmos mais complexos, você perceberá que isso faz diferença na velocidade de processamento de operações.
Continue aprendendo
Nesse artigo, você leu sobre alguns conceitos específicos que são muito utilizados no machine learning. Para continuar seu aprendizado, conferindo estes e outros assuntos em detalhes, confira nosso Curso de Machine Learning com Python. Você verá que pode aprender sobre programação e aprendizado de máquina de modo didático e com exemplos aplicáveis na prática.
Agora, se você já tem certo conhecimento sobre o assunto, confira nossos módulos avançados de Deep Learning. Além disso, temos diversos outros cursos, tanto pagos quanto gratuitos, todos focados no aprendizado do aluno. Clique aqui e confira.