Árvores de Decisão, ou Decision Trees, são algoritmos de machine learning largamente utilizados, com uma estrutura de simples compreensão e que costumam apresentar bons resultados em suas previsões.
Eles também são a base do funcionamento de outros poderosos algoritmos, como o Random Forest, por exemplo.
As decision trees estão entre os primeiros algoritmos aprendidos por iniciantes no mundo do aprendizado de máquina.
Antes de entrarmos nos detalhes deste algoritmo, vamos entender de maneira simplificada o seu funcionamento. Apesar do grande poder de previsão de uma árvore de decisão, conhecer o seu funcionamento básico é algo muito simples e fácil.
Mesmo quem está começando na área já será capaz de obter este entendimento.
Estrutura de uma árvore de decisão
Como o próprio nome sugere, neste algoritmo vários pontos de decisão serão criados. Estes pontos são os “nós” da árvore e em cada um deles o resultado da decisão será seguir por um caminho, ou por outro. Os caminhos existentes são os “ramos”.
Esta é a estrutura básica de uma árvore de decisão. Os nós são responsáveis pelas conferências que irão indicar um ramo ou outro para sequência do fluxo.

Detalhando ainda mais esta lógica, uma pergunta será feita e teremos duas opções de resposta: sim ou não. A opção “sim” levará a uma próxima pergunta, e a opção “não” a outra.
Estas novas perguntas também terão como opções de resposta o sim e não, e desta forma toda a árvore será construída, partindo de um ponto comum, podendo existir várias opções de caminhos diferentes a serem percorridos na árvore, cada um levando a um resultado.
Na imagem abaixo vemos uma árvore de decisão extremamente simples, apenas com dois nós e poucos ramos.
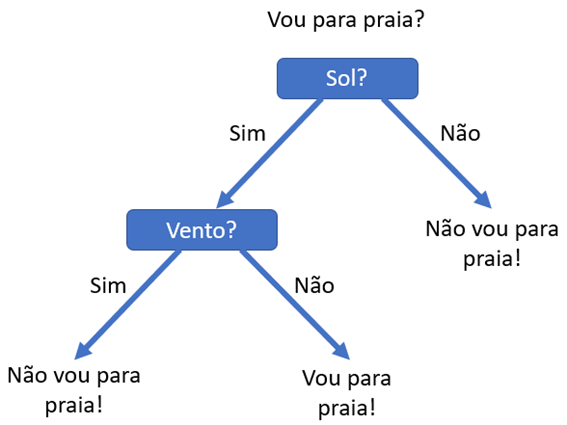
É claro que, em uma situação como esta, não será necessário um algoritmo que nos diga se iremos a praia ou não, mas a ideia é válida para este aprendizado. Entendendo como esta árvore foi criada, você entenderá a lógica de uma árvore de decisão.
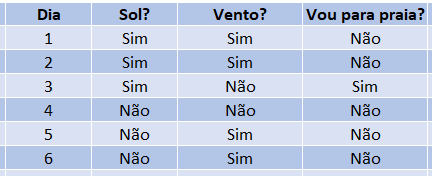
Esta é a tabela que levou à criação da árvore apresentada. Como podemos ver, todas as vezes em que a coluna “Sol?” é igual a “Não”, a pessoa não foi para praia.
Esta coluna foi utilizada na primeira pergunta, ou no primeiro nó de nossa árvore, sendo que sempre que a informação na coluna “Sol?” for “Não”, nossa árvore de decisão responderá que a pessoa não foi para praia.
Porém quando esta resposta for “Sim”, temos casos onde a pessoa foi para praia e outros em que ela não foi.
Ou seja, é necessário fazermos mais uma pergunta para definirmos a resposta, levando assim a segunda pergunta, ou segundo nó de nossa árvore, que irá conferir a informação existente na coluna “Vento?”.
É importante observamos que esta mesma tabela poderia levar a construção de uma árvore diferente. Se primeiramente conferirmos o valor da variável “Vento?” veremos que em todos os dias com vento não fomos para praia.
Em dias sem vento, conferimos também se havia sol, para então definir a resposta final.
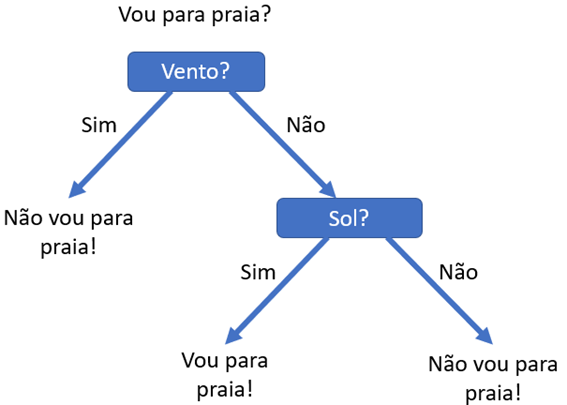
Neste simples exemplo vemos que normalmente não existirá uma única árvore de decisão para um mesmo problema, sendo que com diferentes árvores poderemos chegar a um mesmo resultado.
Definindo os nós e ramos
Assim como podemos ter mais de uma árvore para um mesmo problema, também podemos utilizar diferentes métodos de cálculo na criação de uma árvore de decisão.
Estes métodos são os responsáveis pela definição da estrutura e resultado final da árvore, e tentam buscar a estrutura mais otimizada para o problema em questão.
Imagine que, em nosso exem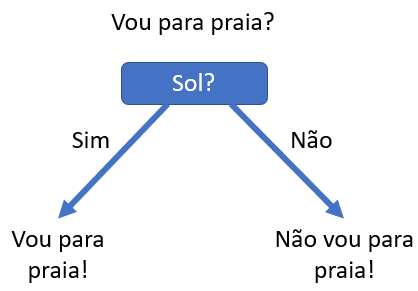 plo anterior, os dados fossem um pouco diferentes, sendo que em todos os dias de sol fomos para a praia, e em dias sem sol, não fomos.
plo anterior, os dados fossem um pouco diferentes, sendo que em todos os dias de sol fomos para a praia, e em dias sem sol, não fomos.
Nesta situação, a árvore não precisaria conferir se existe vento ou não, pois independente desta informação o resultado seria o mesmo. Ou seja, nossa variável target “Vou para praia?” seria totalmente explicada pela variação da variável preditora “Sol?”, resultando em uma árvore com apenas um nó.
Os métodos utilizados pelos algoritmos irão buscar justamente estas variáveis dentre todas as preditoras, identificando aquelas que possuem maior relação com a variável target, e colocando-as no topo da árvore, em seus nós principais.
Estes são alguns dos métodos utilizados para estas definições:
Entropia
Através da entropia o algoritmo verifica como os dados estão distribuídos nas variáveis preditoras de acordo com a variação da variável target. Quanto maior a entropia, maior a desordem dos dados; e quanto menor, maior será a ordem destes dados, quando analisados pela ótica da variável target.
Partindo da entropia, o algoritmo confere o ganho de informação de cada variável. Aquela que apresentar maior ganho de informação será a variável do primeiro nó da árvores.
Podemos entender o ganho de informação como a medida de quão bem relacionados os dados da variável preditora estão com os dados da variável target (ou o quanto a variável target pode ser explicada a partir da variável preditora), sendo que a variável com melhor desempenho será a escolhida para iniciar a árvore.
Índice GINI
Com o cálculo do índice GINI, assim como na Entropia, será verificada a distribuição dos dados nas variáveis preditoras de acordo com a variação da variável target, porém com um método diferente.
A variável preditora com o menor índice Gini será a escolhida para o nó principal da árvore, pois um baixo valor do índice indica maior ordem na distribuição dos dados.
Regressão
Nos problemas de regressão nosso objetivo é prever um valor, e não uma classe. Para isso a árvore utilizará os conceitos de média e desvio padrão, que possibilitarão um resultado final numérico.
Para definir as variáveis preditoras dos nós principais em um problema de regressão, será calculado o desvio padrão dos valores da variável target para cada variável preditora, de acordo com suas variações.
Desta forma, teremos um valor de desvio padrão para cada variável preditora e, comparando-o com o desvio padrão da variável target completa, chegaremos a redução de desvio padrão que a variável preditora em questão aplicou sobre a variável target.
Lembrando que o desvio padrão indica o quão distante os valores estão da média, podemos entender que uma variável com grande redução de desvio padrão indica que através dela a variável target se aproxima da média, mostrando uma grande relação entre a variável preditora e a variável target.
Portanto, a variável preditora com maior redução de desvio padrão será escolhida para o nó principal da árvore.
Evitando Overfitting
Cada novo nó inserido na árvore é um novo critério que deve ser atendido. Ou seja, as amostras são divididas em cada nó, sendo que uma parte segue por um ramo, e a outra por outro. Desta forma é evidente que cada um destes novos nós receberá menos amostras que o anterior, pois o total de amostras que estava no nó anterior foi dividido em dois grupos.
Esta lógica poderá continuar até que não existam mais critérios capazes de dividir as amostras em diferentes grupos. Neste momento teremos uma árvore de decisão completa, capaz de identificar cada amostra com a condição exata que a define.
Podemos utilizar u ma árvore como esta para conhecer os dados em questão e entender seu relacionamento, porém normalmente ao utilizar um modelo de machine learning para prever novos valores a abordagem será diferente, visando garantir a não ocorrência de overfitting.
ma árvore como esta para conhecer os dados em questão e entender seu relacionamento, porém normalmente ao utilizar um modelo de machine learning para prever novos valores a abordagem será diferente, visando garantir a não ocorrência de overfitting.
Um modelo com overfitting é aquele que aprendeu muitos detalhes dos dados históricos que foram utilizados para treinar o modelo.
Na prática, o modelo acabou decorando as condições, de maneira que ao receber novos dados, que costumam possuir relacionamentos similares mas não iguais, estas pequenas diferenças farão o modelo não encontrar as condições exatas que ele decorou, e, por consequência, sua previsão estará errada.
Em uma árvore de decisão, é comum definirmos um número mínimo de amostras para cada novo nó, ou ainda um número máximo de nós para cada ramo. Assim, mesmo que as amostras de um ramo sejam suficientes para criação de um novo nó, caso o número de amostras seja inferior ao que definimos, ou o número máximo de nós do ramo já tenha sido atingido, o nó não será criado, de modo que todas as amostras que estão neste ramo receberão o mesmo resultado.
Com isso, talvez nossos erros aumentem, porém ao apresentar novos dados ao modelo, a probabilidade de uma previsão correta poderá ser maior.
Estas alternativas visam a construção de modelos generalizáveis, que podem ser aplicados em diferentes bases de dados, mantendo bons resultados.
No vídeo abaixo você pode conferir de maneira detalhada a construção de uma árvore de decisão, inclusive com os cálculos envolvidos:
Árvores de decisão na prática
Para entender de maneira completa um conceito, nada melhor do que o aplicar na prática. É isso que buscamos em nossos cursos de Machine Learning.
Através da apresentação detalhada de conceitos teóricos, e com objetividade e clareza na construção de modelos práticos, sempre com muita didática e sem pontas soltas, avançamos do básico ao avançado nos ramos da Ciência de Dados e Inteligência Artificial.
Em nosso curso de machine learning – módulo 1, utilizamos bastante árvores de decisão na prática, resolvendo problemas reais.
Clique aqui e confira todos os nossos cursos completos!
Leia também:
