


Neste artigo, você verá que é possível criar uma inteligência artificial que aprenda a jogar videogame. A técnica utilizada aqui será a mesma criada pela empresa DeepMind para dominar jogos do Atari com aprendizado por reforço.
Essa técnica consiste em utilizar somente os pixels da tela para fazer uma inteligência artificial aprender. Ou seja, não informaremos onde o agente está – sua posição em relação a outros personagens – nem diremos se uma ação que ele tomou foi boa ou ruim.
Todas essas coisas o agente aprenderá com base nos pixels que estão sendo informados na tela e na recompensa que está sendo obtida – essa recompensa pode ser a pontuação recebida em cada jogo, por exemplo.
Essa “ausência de informações”, por assim dizer, faz com que o algoritmo seja muito versátil e possa ser aplicado nos mais diversos games.
Um desafio para a inteligência artificial
Para treinar a nossa inteligência artificial, escolhemos o jogo Street Fighter. Foi um grande desafio utilizar esse jogo específico, pois treinamos o nosso modelo para que ele conseguisse jogar contra todos os personagens zerando o jogo no nível “hard”, que é o nível mais difícil. Grande parte desse desafio vem dos diferentes cenários que o jogo utiliza em cada uma das lutas.


Para cada um dos personagens que enfrentamos, estamos em um cenário diferente. Em alguns desses lugares, vemos bicicletas atravessando; em outros, vemos pessoas se movimentando e, em alguns momentos, até animais aparecem na tela.
Muitos desses cenários têm tantos detalhes que a identificação dos personagens que estão lutando é difícil.
Em vista disso, nosso agente deverá entender que essas movimentações na “plateia” não fazem parte do jogo. Além disso, cada personagem tem seu jeito diferente de lutar. Todas essas informações serão lidas pela rede neural apenas por meio dos pixels da tela e, a partir deles, o modelo aprenderá a jogar diferenciando por conta própria o que faz parte da luta e o que faz parte do cenário.

Como o treinamento irá funcionar?
Basicamente, cada frame – ou instante de tempo – do vídeo, composto por milhares de pixels, será transformado em uma entrada para a nossa rede neural.
A partir da entrada desses pixels, o modelo irá aprender o que deve fazer e decidir qual ação tomar. Para utilizar um algoritmo de aprendizado por reforço é importante que estejamos trabalhando com um sistema de Markov.
Ou seja, precisamos que um estado contenha em si toda a informação necessária para que o agente tome a sua decisão.


Analisando o frame acima, você verá que, apenas com essa imagem, não é possível saber se o “Ryu” está se movimentando para cima ou para baixo. Não sabemos se o “Blanka” está indo para a esquerda ou para a direita.
No entanto, se olharmos alguns frames em sequência, podemos ver mais claramente o que está acontecendo. Ao olharmos os frames abaixo, podemos perceber que a primeira imagem representava o “Blanka” se movimentando na diagonal para cima e o “Ryu” descendo de um pulo que ele já havia dado.


Se juntarmos as informação de mais frames, conseguiremos ter uma melhor noção da movimentação que os agentes estão tendo na tela, bem como a velocidade e aceleração deles.
Essas informações serão um ótimo input para representar, de fato, um estado dentro de um sistema de Markov. Em suma, é isso que faremos no nosso treinamento: agruparemos os frames de quatro em quatro, o que servirá de entrada para a nossa rede neural.
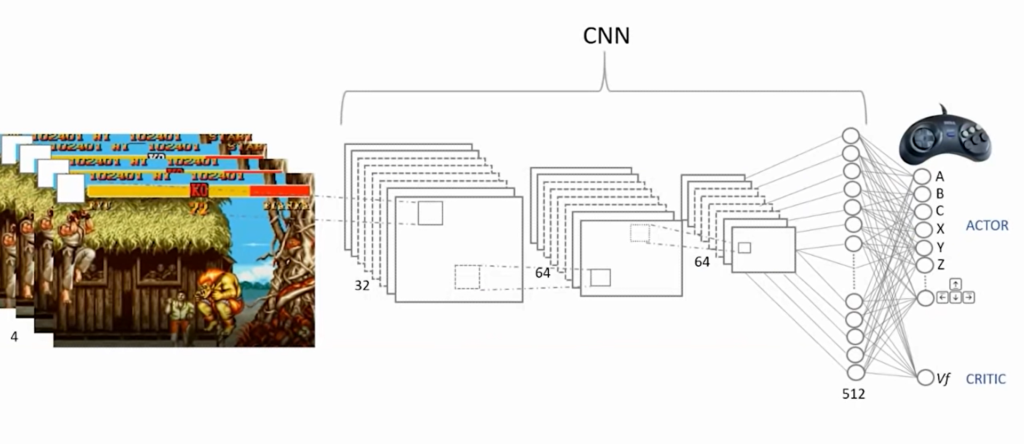

Utilizaremos, no nosso treinamento, a arquitetura da rede neural mostrada acima.
Será uma uma rede neural convolucional (CNN) que terá três camadas: a primeira conterá 32 filtros; a segunda, 64; e a terceira, também 64 filtros. Após essas três camadas de filtros, ainda temos uma camada totalmente conectada com 512 neurônios.
Observe que na figura não estão demonstrados todos os neurônios; a imagem é uma representação simplificada. Finalmente, na camada de saída, teremos dois grupos: um respectivo ao “actor” e o outro respectivo ao “critic”; ou seja, utilizaremos um algoritmo de “actor-critic”, que é um aprendizado por reforço.
Algoritmo de “actor-critic”
Esse algoritmo funciona como se fosse dois problemas diferentes: um de classificação e um de regressão. Tais problemas serão previstos ao mesmo tempo com a mesma rede neural. Além disso, os mesmos pesos e biases, da rede neural inteira, deverão ser calibrados para jogarmos contra todos os personagens.
A parte “actor” é o problema de classificação em que será calibrado quais são os neurônios que devem ser ativados. Para cada entrada que a rede receber – cada grupo de quatro frames –, ela deverá prever quais são os botões que devem ser pressionados no joystick.
A parte “critic” consiste em um problema de regressão no qual será estimado o valor de cada estado. Cada entrada representa um estado, que seria o estado atual.
O neurônio “critic” tentará prever quais os valores dos estados para identificar quais são os estados mais promissores e quais são os menos promissores. Alguns estados trazem mais recompensa que outros.
Com base nisso, o agente tomará uma decisão que maximize a recompensa no estado atual mas também que o leve para um estado posterior mais promissor; o algoritmo pensará na recompensa acumulada a longo prazo.
Em suma, um algoritmo de “actor-critic” consiste em prever simultaneamente as melhores ações a serem tomadas e o valor de cada estado. Esse foi, então, o algoritmo que usamos para treinar o jogo do Street Fighter.
Resultados do treinamento
A rede foi treinada por cerca de 60 horas. Após esse período de treinamento, os resultados são os seguintes:
É interessante observar que, como a rede neural tem que lutar contra diferentes personagens, ela desenvolveu uma estratégia para cada um. O personagem escolhido para a nossa inteligência artificial foi o “Ryu”.
A estratégia utilizada, na luta contra o “Honda”, foi ficar posicionado na esquerda da tela esperando o ataque do oponente. Apenas quando o “Honda” vinha de encontro à nossa inteligência artificial, ela desferia algum golpe.

Contra a “Chun Li”, algo muito interessante aconteceu. O algoritmo percebeu que existe um ponto no qual a oponente dá um salto para tentar atingi-lo. Dessa forma, o “Ryu” aguarda com paciência no canto até o momento desse salto para dar um soco para cima.


Uma das lutas mais interessantes, na nossa opinião, foi contra o “Sagat”. Primeiramente, o “Ryu” fica apenas se defendendo das bolas de fogo lançadas pelo oponente; ele apenas ataca quando o “Sagat” vem em sua direção.
Além disso, a inteligência artificial percebeu que não precisa vencer por nocaute, tendo vencido, nessa partida, pelo tempo do jogo sem levar nenhum golpe.


O “Zangief” foi o personagem dominado mais rapidamente. A inteligência artificial utilizou a estratégia de pular e dar chutes para o alto. Não importa o que o oponente fizesse, o “Ryu” utilizava sempre essa mesma técnica em todos os rounds.
Inclusive, na próxima vez que você jogar Street Fighter contra o “Zangief”, você pode tentar reproduzir essa estratégia.

Mas nem tudo são flores. Contra alguns personagens, a inteligência artificial demorou muito mais para aprender a jogar. Esse foi o caso do “Vega” e do “Dhalsin”.
A dificuldade do “Vega” foi que ele dá saltos diferentes, se agarrando na grade e até saindo do cenário. O “Dhalsin”, por sua vez, consegue atingir o “Ryu” de longe pois estica muitos suas pernas e braços. Ainda assim, o algoritmo foi capaz de vencer esses personagens após praticar o suficiente.


Modificando a recompensa no treinamento da IA
Após algumas partidas, resolvemos fazer algo diferente. Em vez de dar uma pontuação positiva cada vez que a inteligência artificial atingisse o oponente, demos uma recompensa negativa cada vez que ela batesse em alguém ou levasse um golpe. Ou seja, o “Ryu” deveria apenas se defender. Nesse caso, foi isso mesmo que ela fez, apenas se defendeu de todos os golpes.


Nessa partida, o “Ryu” não venceu, entretanto, ele aprendeu a fazer o que foi pedido dele. Isso é interessante pois mostra que podemos treinar o algoritmo para fazer aquilo que quisermos que ele faça. Ou seja, nós podemos personalizar a nossa função de recompensa.
Vídeo completo mostrando a Inteligência Artificial jogando

Aprofunde seus conhecimentos
Esse foi nosso treinamento de uma inteligência artificial para jogar Street Fighter.
Se você gostou dos tópicos tratados nesse artigo e quer aprender a colocar tudo isso em prática, não deixe de conferir o nosso curso completo onde ensinamos essa técnica de aprendizado por reforço e Deep Learning.
Você aprenderá não só teoria, mas também como aplicar os algoritmos de forma simples e com muita didática:
Além disso, temos diversas outras opções, tanto pagas como gratuitas, de cursos sobre machine learning, inteligência artificial, linguagens de programação etc. Clique aqui e confira!
Leia também outros artigos: