O Pandas é um dos pacotes da linguagem Python, largamente utilizado no machine learning e inteligência artificial. Ele fornece ferramentas com grande poder para manipulação e análise de dados, de maneira simples e eficiente, conferindo alta performance aos códigos.
É muito utilizado em conjunto com o pacote Numpy, que tem seu foco em operações matemáticas.
 Com o Pandas podemos, com muita simplicidade e agilidade, carregar em nossa sessão arquivos que estamos acostumados a lidar no dia a dia.
Com o Pandas podemos, com muita simplicidade e agilidade, carregar em nossa sessão arquivos que estamos acostumados a lidar no dia a dia.
Não é necessário nenhum software especial para criar ou transformar estes arquivos, pois é possível a importação de planilhas do Excel, em formato .xls ou .xlsx, ou mesmo arquivos do tipo .csv, que são utilizados em larga escala quando trabalhamos com bases de dados.
Dessa forma, mesmo aqueles que ainda estão começando no aprendizado da linguagem Python, já serão capazes de carregar, analisar e manipular dados externos. Esses arquivos serão carregados como dataframes Pandas, através de uma das funções do pacote.
Como de costume, a melhor forma de se aprender um pacote da linguagem Python é na prática: conhecendo e aplicando suas funções. Seguiremos neste caminho, porém, antes, vamos entender o que é um dataframe criado com o pacote Pandas.
Dataframes do Pandas
Os dataframes do Pandas podem ser criados de diferentes formas, sendo a mais comum através da importação de uma base de dados externa. Não vamos entrar nos detalhes técnicos dos dataframes Pandas, pois, neste momento, isto nos traria mais complicações do que uma efetiva ajuda no entendimento.
Após estes conceitos iniciais, iremos para a prática, de forma simples e objetiva.
A maneira mais eficaz de se entender essa estrutura de dados é através de sua comparação com tabelas. Conforme falamos, será comum a criação dos dataframes através da importação de arquivos externos.
Estes arquivos costumam estar organizados em formato de tabela, organizados em colunas e linhas. O dataframe criado com o Pandas manterá essa organização, sendo que cada coluna poderá conter um tipo de dado específico, e em cada linha, a respectiva observação.
Importando o pacote
Para utilizar um pacote em nossos scripts ele precisa estar instalado, para depois ser carregado. Você pode instalar o Pandas pontualmente, mas caso tenha instalado o Python através do Anaconda, conforme indicamos nesta página, ele já será instalado juntamente com a linguagem, sendo que só nos resta realizar a importação nos scripts onde o pacote for utilizado.
Para importar utilizaremos o código abaixo:
import pandas
Ou
import pandas as pd
Ao utilizarmos a segunda opção, estamos indicando “as pd”, atribuindo assim um apelido para o pacote. Este apelido, ou alias, é muito utilizado na programação, sendo que podemos atribuir o apelido que quisermos para um determinado pacote, com a única finalidade de simplificar o código, facilitando sua escrita e leitura.
Neste exemplo estamos dizendo que ao utilizar o Pandas usaremos a sigla “pd”. Podemos dar o apelido que quisermos, porém alguns pacotes possuem padrões normalmente utilizados, sendo “pd” um alias comum para o pacote Pandas. Desta forma, caso outra pessoa leia nosso código, provavelmente ela entenderá com facilidade nossos comandos.
pandas.read_excel e pandas.read_csv
As funções “read_excel” e “read_csv” são as funções que utilizaremos para importar um arquivo para nossa sessão, de maneira que ele possa ser utilizado. Isto significa que ao carregarmos este arquivo e salvarmos seu conteúdo em um objeto, poderemos analisar e manipular seu conteúdo. Ou seja, na prática acontece uma cópia do arquivo original, de maneira que o arquivo que está em nosso computador permanecerá o mesmo.
Ele só será alterado, se utilizarmos uma outra função que exporte as informações de nossa sessão para um arquivo com o mesmo nome, e na mesma pasta do original, que acabará sendo substituído.
read_excel
Com a função read_excel podemos carregar as planilhas do Excel, que possuem o formato .xlsx. Estes arquivos são comuns no dia a dia de quase todos que trabalham com um computador. Podemos facilmente criar uma simples planilha do Excel e importar estes dados para nosso script Python.
Para realizar a importação, precisamos apenas indicar na função o caminho e nome do arquivo que iremos importar.
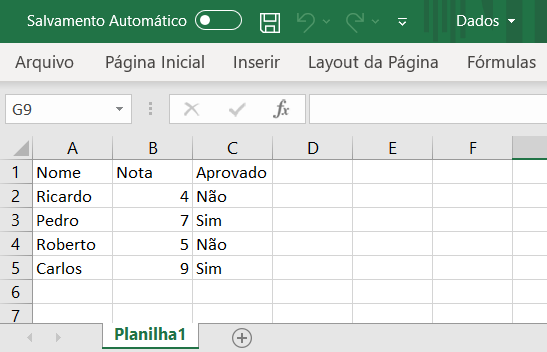
dados_excel = pd.read_excel(“C:/DT/Dados.xlsx”)
Vale ressaltar que na realidade da análise de dados e machine learning são poucas as situações onde utilizamos a função acima. Isto acontece pois planilhas normais do Excel não são ideais para grandes conjuntos de dados. Elas possuem diferentes possibilidades de formatação, que podem complicar nosso código, dentre outros problemas.
read_csv
A função read_csv irá funcionar da mesma maneira, porém para arquivos do tipo .csv. Este é um formato de arquivo de texto separado por vírgulas, excelente para trabalharmos com tabelas. Estes arquivos sempre organizam seus dados em linhas e colunas, sem informações adicionais, como cor de texto, formato, tipo dos dados, entre outras possibilidades comuns em alguns tipos de arquivos.
Na prática um arquivo csv pode possuir um separador diferente da vírgula, como o ponto e vírgula, mas normalmente será uma dessas opções.
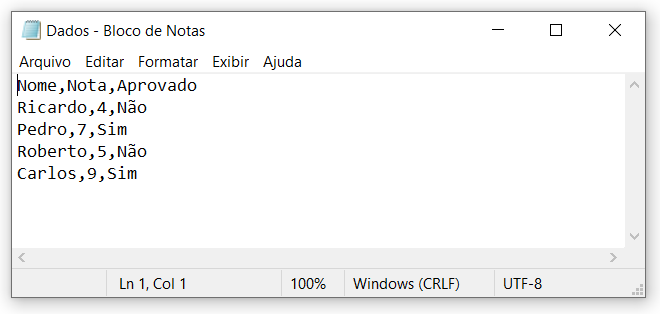
dados_csv = pd.read_csv(“C:/DT/Dados.csv”)
Funções básicas
Após utilizarmos uma das funções acima, teremos nossa tabela devidamente carregada na sessão para ser analisada e manipulada. Para isso o Pandas fornece algumas funções básicas, que possuem grande utilidade nesta tarefa.
Estas funções serão aplicadas no objeto que acabamos de criar, através da indicação do objeto, um ponto, e o nome da função que desejamos utilizar, seguido dos parênteses e algum parâmetro, caso necessário.
- head() – utilizada para retornar as primeiras n linhas do dataframe em questão. Caso não indiquemos nos parênteses um valor, n será igual a 5, e serão exibidas as 5 primeiras linhas
dados_csv.head()

- shape – retorna a dimensão do dataframe. Ou seja, quantas colunas e linhas ele possui. Apesar de listarmos aqui, esta não é uma função, mas sim uma propriedade do objeto, razão pela qual não indicamos os parênteses.
dados_csv.shape

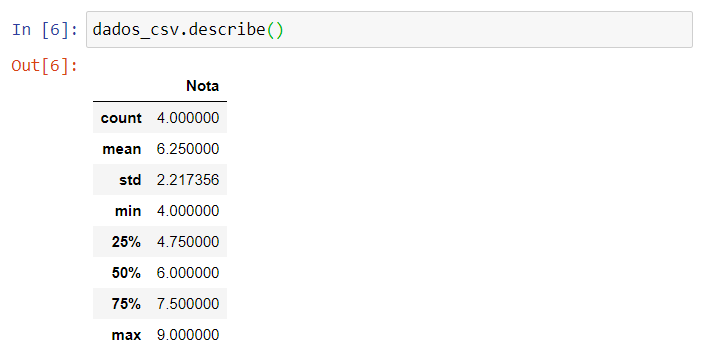
- describe() – retorna estatísticas descritivas de cada coluna numérica do dataframe.
dados_csv.describe()
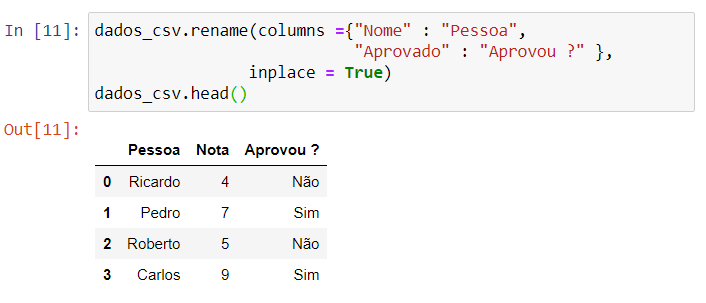
- rename() – renomeia as colunas ou linhas do dataframe. Indicando nos parênteses “columns ={}”, as colunas serão renomeadas de acordo com os dados passados nas chaves, sendo que deveremos indicar o nome atual e o novo. Para alterar os nomes das linhas faremos o mesmo, indicando “index={}”. Indicando apenas estes parâmetros, teremos como resultado um novo dataframe com os novos nomes, sendo que o original continuará o mesmo.
Para alterar o dataframe original precisamos indicar o parâmetro “inplace = True”.
dados_csv.rename(columns ={"Nome" : "Pessoa",
"Aprovado" : "Aprovou ?" },
inplace = True)
dados_csv.head()
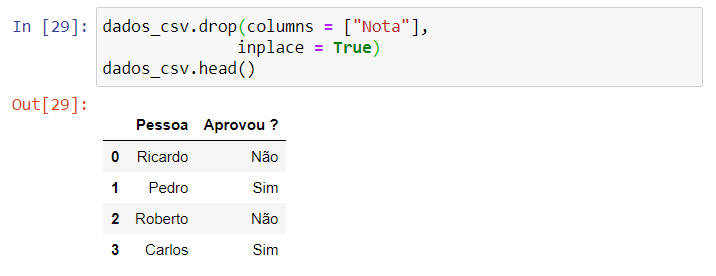
- drop() – remove colunas ou linhas do dataframe. Indicando nos parênteses “columns =[]”, as colunas indicadas serão removidas, indicando “index =[]”, as linhas.
dados_csv.drop(columns = ["Nota"],
inplace = True)
dados_csv.head()
Como aprender mais sobre Pandas
Estes são os primeiros passos para que você possa iniciar análises e manipulações de dados externos com Python, de maneira simples e eficaz. O Pandas possui ainda muitas outras ferramentas, que utilizadas em conjunto com outros pacotes fornece soluções para a grande maioria dos problemas de análise.
Caso queira aprender o Pandas em detalhes, e, também, machine learning usando Python, confira este curso de machine learning com Python.
Neste curso nós realizamos diversas manipulações em datasets utilizando pandas, para depois poder aplicar uma inteligência com algoritmos.
O vídeo abaixo também resume várias das funções apresentadas nesse artigo:
Leia também:
