O KNN (K-nearest neighbors, ou “K-vizinhos mais próximos”) costuma ser um dos primeiros algoritmos aprendidos por iniciantes no mundo do aprendizado de máquina.
O KNN é muito utilizado em problemas de classificação, e felizmente é um dos algoritmos de machine learning mais fáceis de se compreender.
Em resumo, o KNN tenta classificar cada amostra de um conjunto de dados avaliando sua distância em relação aos vizinhos mais próximos. Se os vizinhos mais próximos forem majoritariamente de uma classe, a amostra em questão será classificada nesta categoria.
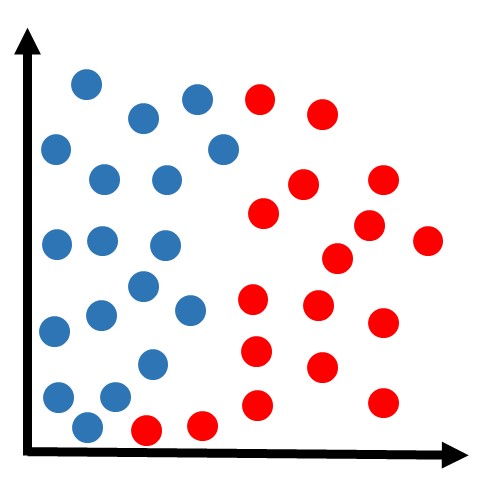
Para entender como o KNN funciona detalhadamente, primeiro considere que temos um conjunto de dados dividido em duas classes: azul e vermelho, conforme a figura abaixo.
Agora recebemos uma amostra que ainda não está classificada, e gostaríamos de definir se ela pertence à classe azul ou à classe vermelha. Digamos que essa nova amostra (cor verde na figura abaixo) esteja localizada nessa região:
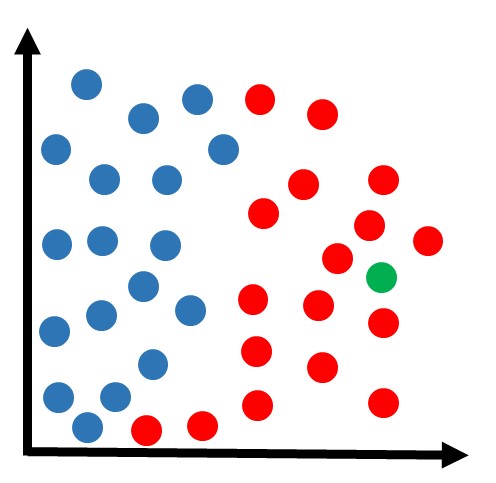
Intuitivamente, podemos observar que faz mais sentido classificar essa amostra como pertencendo à classe vermelha. Mas o algoritmo não possui “intuição”, ele precisa de um cálculo matemático para poder definir a solução.
No caso do KNN, a lógica é a seguinte:
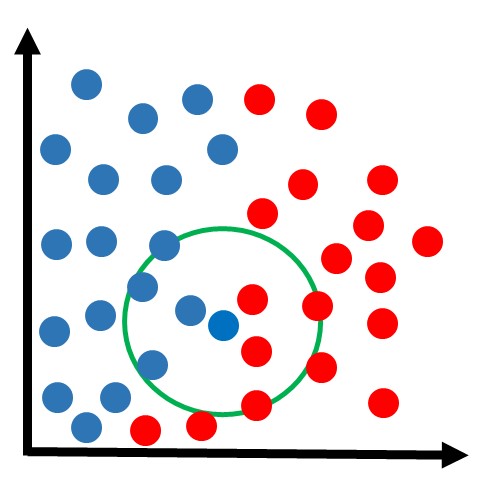
Observa-se a classe dos vizinhos mais próximos, em uma votação onde a maioria vence. Por exemplo, vamos supor que estamos analisando os 3 vizinhos mais próximos. Obs: mais próximo significa com a menor distância em relação à amostra:
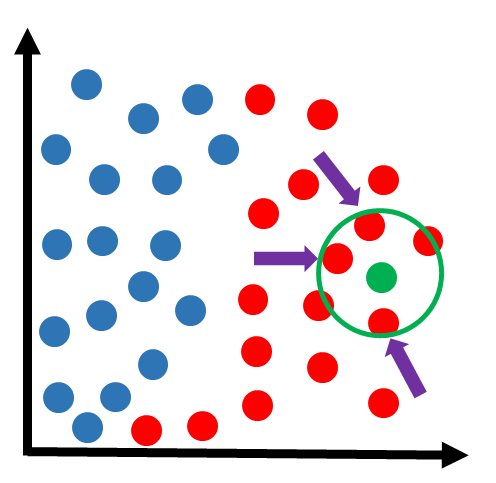
Na figura acima, podemos ver que os 3 vizinhos mais próximos pertencem à classe vermelha. Então como houve 3 votos a zero para a classe vermelha, essa amostra fica sendo classificada nessa classe:
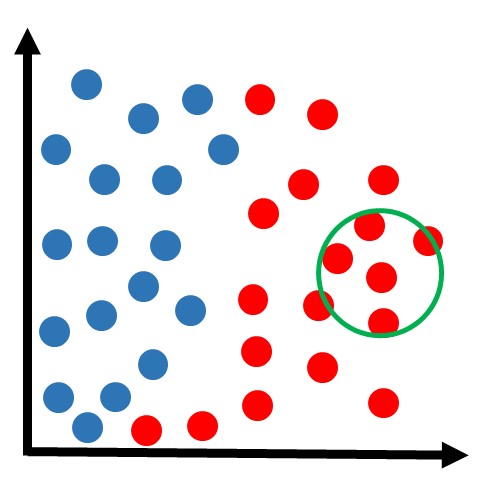
Obs: talvez agora esteja mais claro o significado do nome “KNN”, que refere-se a “k-vizinhos mais próximos”, onde k é um número que podemos determinar. Nesse exemplo, estamos usando k=3.
Agora recebemos outra amostra que queremos classificar:
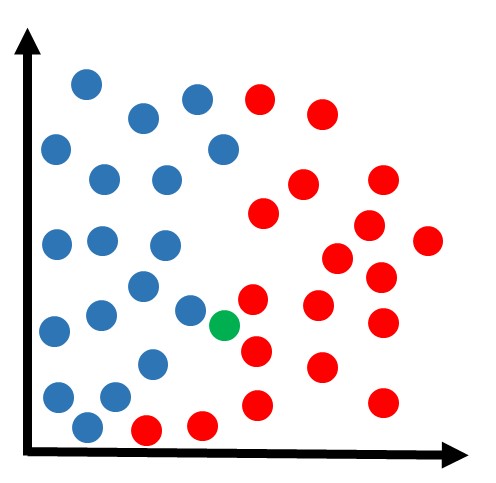
Utilizando o mesmo método KNN com k=3:
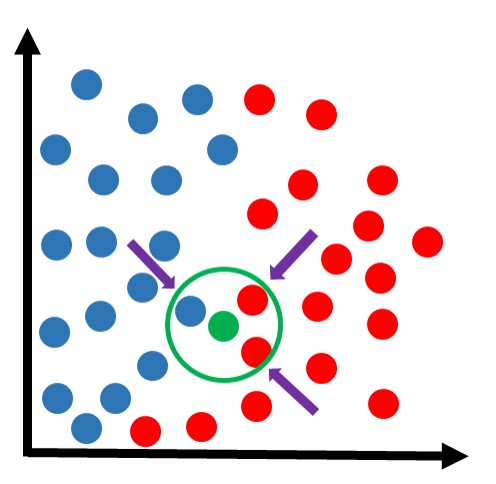
Encontramos os 3 vizinhos mais próximos dessa amostra. Dessa vez, há duas amostras da classe vermelha e uma da classe azul. Como a votação ficou 2×1 para a classe vermelha, essa amostra ficaria sendo classificada nessa classe:
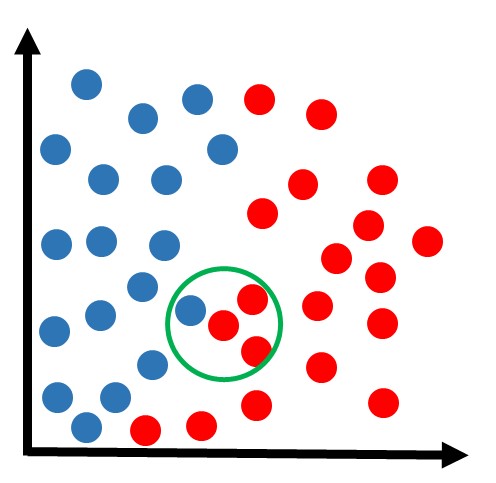
Essa metodologia poderia ser aplicada para qualquer nova amostra e estaríamos aptos a definir sua devida classificação. Porém até agora utilizamos apenas o exemplo de k=3. Na prática, podemos escolher outro valor de k.
Vamos supor que a mesma amostra anterior estivesse sendo analisada com o algoritmo de KNN com k=5:
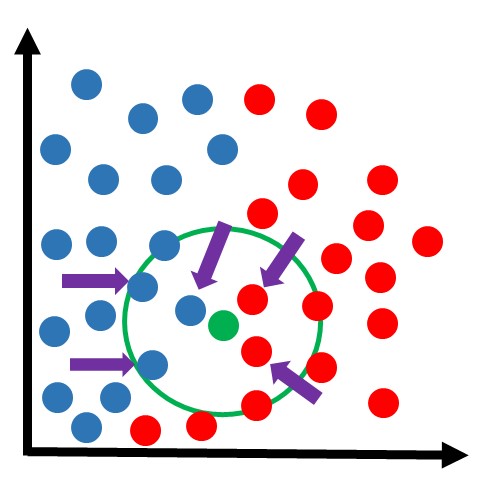
Dessa vez, dos 5 vizinhos mais próximos, 3 são azuis e 2 são vermelhos. Portanto a classe vencedora foi a azul. Essa amostra seria classificada nessa classe:
Nota-se que, dependendo do valor de k, poderemos ter resultados diferentes para cada situação.
Quando o k é pequeno, a classificação fica mais sensível a regiões bem próximas (podendo ocorrer o problema de overfitting). Com k grande, a classificação fica menos sujeita a ruídos pode ser considerada mais robusta, porém se k for grande demais, pode ser que haja o problema de underfitting.
Obs: nos exemplos desse artigo, tentamos mostrar visualmente quais eram os vizinhos mais próximos em cada situação. Porém não podemos esquecer que a forma como o algoritmo faz essa seleção é calculando a distância de cada um dos pontos já classificados em relação à nova amostra que queremos classificar. Ou seja, como nos exemplos havia cerca de 30 amostras já classificadas, o algoritmo KNN teria que fazer o cálculo da distância de cada um desses pontos em relação à nova amostra, e ordenar depois do menor ao maior, selecionando assim as amostras mais próximas.
Resumo do processo realizado pelo algoritmo KNN:
1 ) Receba um dado não classificado e meça distância do novo dado em relação a cada um dos outros dados que já estão classificados;
2 ) Selecione as K menores distâncias;
3 ) Verifique a(s) classe(s) dos dados que tiveram as K menores distâncias e contabilize a quantidade de vezes que cada classe que apareceu;
4 ) Classifique esse novo dado como pertencente à classe que mais apareceu.
Se você gostou da didática deste artigo, saiba que esse é o padrão da equipe Didática Tech, ensinar machine learning passo-a-passo, sem mistérios e com muita clareza. Confira nossos cursos completos para aprofundar seus conhecimentos!
Você vai ver que temos 4 módulos de cursos de machine learning. Utilizamos e resolvemos problemas práticos com KNN no módulo 1.
Leia também:
