
Séries temporais possuem uma diferença significativa na aplicação de redes neurais, sendo necessário uma arquitetura diferente das já conhecidas Redes Neurais Densas, Convolucionais ou mesmo as GAN’s.


Ao aplicarmos machine learning com algoritmos de regressão, árvores de decisão, métodos ensemble, ou mesmo ao avançarmos em muitos algoritmos de deep learning, normalmente trabalhamos com dados que não têm uma relação temporal.
Se formos pensar no modelo das redes neurais totalmente conectadas – as redes densas – ou, ainda, as redes convolucionais, vamos reparar que quando fazemos o gradiente descendente estocástico com lotes de treinamento, esses lotes coletam parte da informação, parte dos dados de entrada para treinar a rede; depois, um novo lote entra para treinar a rede, depois outro, e outro.
Esses lotes de dados não estão relacionados diretamente com o lote anterior.
Na realidade, por padrão, as funções que utilizamos do Keras ou TensorFlow, até fazem shuffle (embaralhamento nos dados de entrada) antes de escolher um lote de treinamento para garantir que não haverá nenhum viés nesse treinamento. Isso faz sentido, porque os dados utilizados não têm uma ligação temporal.
Por exemplo, uma imagem: se queremos que uma rede neural aprenda o que é um gato e qual a diferença de um gato para um cachorro, a ordem entre as imagens não faz diferença.
Relações temporais
Agora, o que seria uma relação temporal? Podemos citar alguns exemplos para ficar mais claro, como a ação da Petrobrás na Bolsa de Valores: se pegarmos os últimos 10 anos, ela variou bastante, entre R$ 4,00 e R$ 40,00, aproximadamente.
Para tentar prever quais os preços das ações da Petrobrás em determinando dia (vamos imaginar o dia específico de um mês de um ano específico), faz muito mais sentido e haverá muito mais chance desse preço estar parecido com o preço dos dias anteriores.
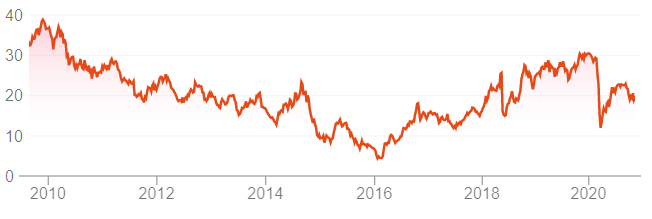

Se o preço dos dias anteriores estava na faixa dos R$ 8,00, R$ 8,47, R$ 8,32 (dias imediatamente anteriores), é pouco provável que no próximo dia o preço esteja R$ 25,00. O preço não oscila tanto de um dia para o outro!
Então, para a previsão do próximo dia, fará mais sentido darmos mais peso aos dias mais recentes e menos peso para os dias muito anteriores.
Outro exemplo: se formos prever quantos gols um time de futebol fará na próxima partida, algumas variáveis podem ser analisadas: quem é o time oponente, se a equipe jogará em casa ou não, etc. Outro dado importante é analisar quantos gols o time fez no seu histórico, mas faz mais sentido pensar num histórico recente do que num histórico muito antigo; afinal, o time pode estar mais entrosado, ou seja, se nos últimos jogos ele fez mais gols, há mais chances do time estar jogando melhor.
Já se nos últimos jogos ele fez poucos gols ou perdeu muitas partidas, talvez o time até estivesse bem no passado, mas, agora, alguma coisa fez com que o time se desajustasse, como a troca do técnico ou algum outro evento. O fato é que os dados mais recentes devem ter um peso maior para se fazer uma previsão daquilo que se está procurando nesse cenário.


Afinal, provavelmente as palavras imediatamente anteriores darão uma previsão e uma assertividade muito melhor para sabermos se temos que colocar um substantivo, um verbo ou um adjetivo.
Poderíamos citar muitos exemplos porque podemos imaginar que há muitos casos de problemas do mundo real em que os dados possuem uma forte conexão e ligação temporal, em que precisamos dar mais peso para os dados mais recentes.
Como já comentamos, muitos modelos conhecidos não são bons para dados temporais porque o próprio método de treinamento não é adequado para trabalhar dessa forma. Pensando nisso, foram construídas arquiteturas de redes neurais específicas para atacar esses tipos de problemas temporais, como as RNNs.
Arquiteturas de Redes neurais recorrentes (RNNs)
A chave para um bom entendimento das RNN’s está na compreensão de sua arquitetura, que pode ser conferida de maneira detalhada aqui.
A principal diferença entre uma RNN e uma rede neural densa está na camada oculta de uma RNN, conforme vemos na imagem abaixo.
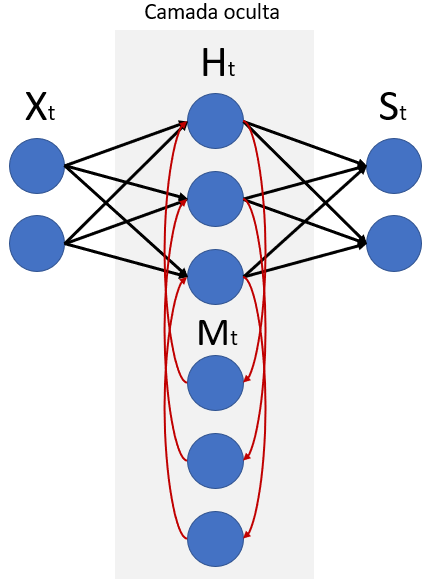

Neste exemplo, além dos 3 neurônios que recebem informação da camada de entrada e enviam para camada de saída, temos também outros 3 neurônios que recebem e enviam informações dentro da própria camada oculta.
Através destes 3 neurônios de baixo, denominados aqui como “Mt” (de memória), a rede estará se realimentando de forma cumulativa a cada iteração, que acontece em um tempo específico, indicado pela letra “t”, por Mt.
Na primeira iteração, com “t” igual a 1, os neurônios “H” receberão informações de “X” e enviarão para “S” e também para “M”. Com isso, na segunda iteração, com “t” igual a 2, os neurônios de “H” receberão as informações de “X” como aconteceu na primeira iteração, mas também receberão informações de “M”, que neste momento são iguais a “H” do tempo anterior, que foi gerado a partir de “X” do tempo anterior, e assim por diante.
Ou seja, a informação que “Ht” passará a “Mt” e “St” no tempo atual está sendo influenciada pelo valor de “Ht-1” do tempo anterior, que por sua vez sofreu influência de todos os valores de “Xt-1” de tempos anteriores.
Como aprender na prática a trabalhar com séries temporais
Todos esses assuntos, desde o início das redes neurais recorrentes até os estudos de processamento de linguagem natural, estarão dentro do macro escopo de séries temporais de dados. Esse assunto é um pouco mais complexo e, por isso, fazemos questão de colocá-lo no módulo 4 de nossos cursos.
Isso poderá fazer com que a compreensão seja um pouco mais difícil ou complexa, mas não é nada “de outro mundo” e, como de costume aqui no Didática Tech, faremos de tudo para explicar da forma mais didática possível para que fique bem claro para todos.
Um cuidado especial precisa ser tomado no estudo prático da programação. Quando trabalhamos com dados temporais, é preciso separar os dados da forma correta: o que são variáveis, o que são features e o que são timesteps.
Nesse momento específico, temos que ter bastante atenção para compreendermos a subdivisão dos dados em termos das dimensões: o que faz menção às variáveis, o que faz menção aos timesteps, etc.
Continue esse artigo lendo o texto: Redes Neurais Recorrentes
Outros artigos relacionados: