 HTML é uma linguagem de marcação utilizada nas páginas web. O navegador de internet que você está utilizando agora interpreta o código html existente na página, e o transforma em algo compreensível para nós, de maneira que visualizamos os textos, imagens, botões e o que mais existir nesta página, conforme sua codificação.
HTML é uma linguagem de marcação utilizada nas páginas web. O navegador de internet que você está utilizando agora interpreta o código html existente na página, e o transforma em algo compreensível para nós, de maneira que visualizamos os textos, imagens, botões e o que mais existir nesta página, conforme sua codificação.
Este processo acontece através das tags da linguagem.
Editor HTML Gratuito
Para baixar o HTML Editor 12 gratuito, faça o download aqui.
Como editar HTML com Python
Com a linguagem Python podemos criar, editar e ainda ler páginas html já existentes. Uma das maneiras mais práticas e poderosas para isso é através do Beautiful Soup, uma biblioteca do Python muito utilizada para extração de dados html e xml.
Web scraping
Na ciência de dados é comum analisarmos grandes quantidades de dados, normalmente através de arquivos csv, conexões diretas com bancos de dados, ou mesmo a partir de páginas da web.
Quando precisamos destes dados de páginas, podemos acessar uma a uma e extraí-los, salvando em um arquivo para depois importá-lo em nossa ferramenta de análise.
Esta solução funciona, porém em muitas situações será inviável. Imagine que você precise acessar milhares de páginas para isso, copiando e salvando os conteúdos. Uma das opções que temos para resolver este problema é através do Web scraping (coleta ou raspagem de dados web).
Através do Web scraping, nosso script irá acessar os sites indicados, extrair suas informações e convertê-las em uma estrutura que possibilite a análise, permitindo que esta aconteça em massa.
Precisamos lembrar que nem todos os sites permitem a extração de seus dados, ou mesmo o acesso de maneira automatizada. Neste sentido, é importante que se verifique as permissões necessárias em casa situação.
Beautiful Soup – Web scraping com Python
No início desta conversa mencionamos que o navegador transforma o código html de maneira que possamos visualizá-lo corretamente. Portanto, existem informações neste código que não queremos, fazendo parte apenas da estrutura da linguagem.
Quando utilizamos uma linguagem de programação para acessar um site, todo este código será extraído, e precisamos encontrar as informações relevantes em meio as muitas configurações de estrutura existentes no código. O Beautiful Soup facilita, e muito, este processo.

Utilizando a biblioteca, ela entenderá o código html apresentado, organizando em uma estrutura que nos permitirá acessar suas informações de maneira independente.
Sem ela, teríamos uma grande quantidade de texto em um documento, onde procuraríamos por informações palavra por palavra. Com o Beautiul Soup este texto já estará com uma organização prévia, e poderemos buscar por informações específicas, como títulos e parágrafos.
Carregando e editando uma página web
Para que fique claro este entendimento, vamos carregar uma página html e realizar uma pequena edição, salvando seu conteúdo.
No código abaixo iremos importar as bibliotecas. Com a requests, iremos utilizar a função get para conectar em uma página na internet, e salvar seu conteúdo html em um objeto. Lembrando que podemos nomear os objetos conforme acharmos melhor.
import requests
from bs4 import BeautifulSoup
url = 'http://example.com/'
pagina = requests.get(url)

Após conectarmos no site em questão e salvarmos o conteúdo da página no objeto “pagina”, precisamos transformá-lo em um objeto beautiful soup. Para isso utilizamos a função BeautifulSoup, indicando o conteúdo existente no objeto, através de “pagina.text”. Após criar o objeto “pag_bs” estamos apenas conferindo em seu conteúdo as tags “h1” existentes.
pag_bs = BeautifulSoup(pagina.text)
print(pag_bs.find_all('h1'))

Vamos agora alterar o conteúdo desta página, inserindo texto nela. Para isso, acrescentaremos a tag h1 encontrada acima a frase “ TESTE DIDATICA”. Com o comando “pag_bs.h1.append”, estamos selecionando a tag h1 do objeto, e adicionando a ela o texto indicado.
pag_bs.h1.append(" TESTE DIDATICA")
print(pag_bs.find_all('h1'))

Como podemos visualizar, nenhum conteúdo da tag foi excluído, sendo apenas acrescentado o que indicamos. Para conferir na prática estes ajustes, vamos salvar em um arquivo html e executá-lo através do navegador.
with open("pag_didatica.html", "w") as out:
out.write(str(pag_bs))

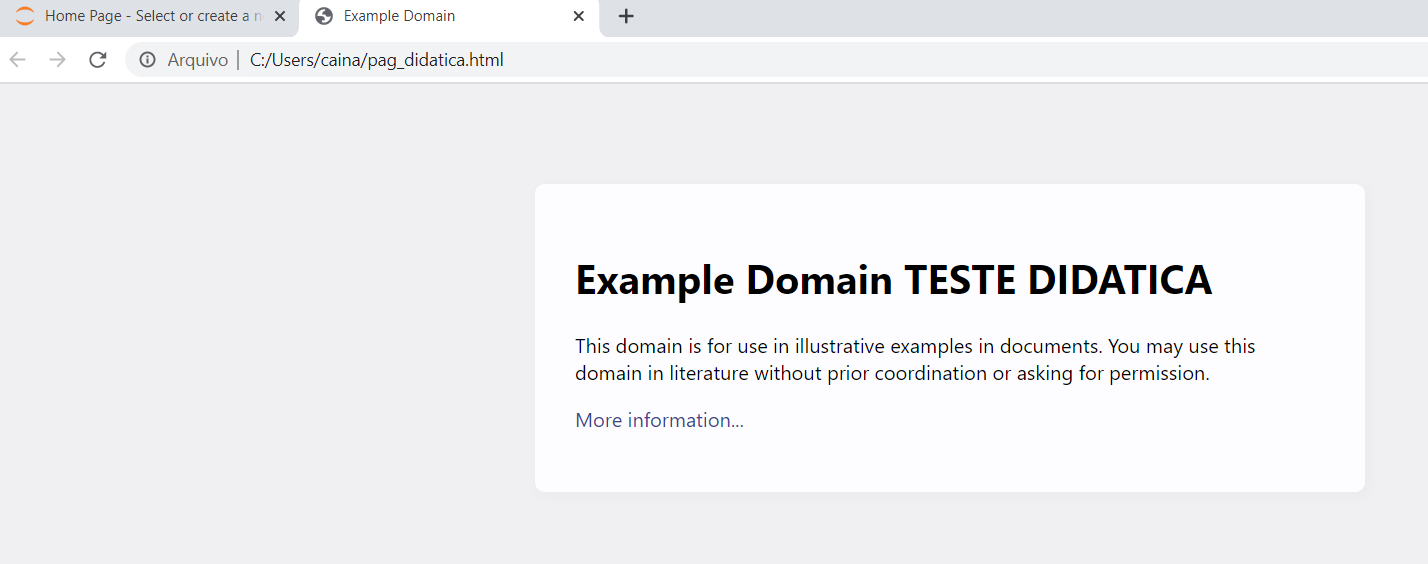
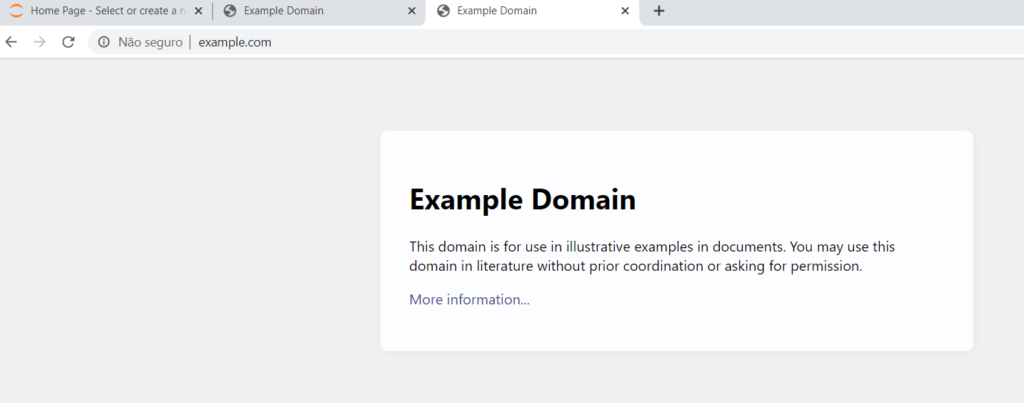
Comparando as telas podemos ver que a única alteração existente é a frase a mais que inserirmos. Nenhum conteúdo foi perdido ou alterado.
Como aprender mais sobre Python
Se você gostaria de explorar todas as áreas de aplicação Python, conheça nosso curso completo Programador com Python. Você vai aprender com muita didática e simplicidade, com exercícios focados e eficiência máxima.
Leia também:
- O que é Python
- Curso de python para iniciantes
- Como acelerar o processamento da sua CPU para Machine Learning com Python
- O pacote Numpy – Python para Machine Learning
- O pacote Pandas – Python para Machine Learning
- A biblioteca scikit-learn – Python para Machine Learning
- Seu primeiro código de Machine Learning com Python
