 Sabemos que o principal objetivo do Machine Learning é prever o que ainda não se sabe. Apesar deste ser um objetivo específico, o seu resultado pode ser apresentado de diferentes formas, e a visualização de dados é responsável por tornar esta resposta ainda mais eficiente.
Sabemos que o principal objetivo do Machine Learning é prever o que ainda não se sabe. Apesar deste ser um objetivo específico, o seu resultado pode ser apresentado de diferentes formas, e a visualização de dados é responsável por tornar esta resposta ainda mais eficiente.
Podemos separar a utilização da visualização de dados para machine learning em três principais momentos, sendo dois deles com participação intensa, e um conforme a necessidade da análise em questão, podendo em alguns casos nem existir este terceiro.
- Análise exploratória dos dados
- Apresentação do resultado final
- Apoio na construção dos modelos de machine learning
É importante também, lembrarmos que a finalidade do machine learning independe das visualizações utilizadas. Com isso, podemos ter cientistas de dados que realizem suas análises, testando diferentes algoritmos, chegando a modelos definitivos e com bons resultados finais, sem a utilização de dashboards ou gráficos.
Não é algo que vemos com frequência, mas há situações que permitem esta abordagem.
Análise exploratória dos dados
 Antes de iniciar o desenvolvimento de um modelo de machine learning, é fundamental o bom conhecimento dos dados em questão, entendendo com clareza como as variáveis se relacionam entre si. Neste momento, o comum é que seja realizada uma exploração nos dados, tanto de maneira macro, observando relações entre as variáveis e seus comportamentos, como de maneira individualizada, em cada variável.
Antes de iniciar o desenvolvimento de um modelo de machine learning, é fundamental o bom conhecimento dos dados em questão, entendendo com clareza como as variáveis se relacionam entre si. Neste momento, o comum é que seja realizada uma exploração nos dados, tanto de maneira macro, observando relações entre as variáveis e seus comportamentos, como de maneira individualizada, em cada variável.
Uma das grandes ferramentas, se não a melhor, para esta etapa é a visualização de dados. Com gráficos, e até mesmo dashboards, ficará evidente o significado dos dados, e a leitura dos mesmos será simplificada, conferindo agilidade e objetividade ao processo.
Por exemplo, é comum nesta etapa observarmos a correlação entre as variáveis, variando entre – 1 e + 1 os valores observados, sendo – 1 as correlações perfeitamente inversas (se uma variável diminui, a outra também), e + 1 as perfeitamente diretas (se uma aumenta, a outra também). Não sabe o que é correlação? Sem problema, vamos resumir de maneira simples e objetiva nos dois parágrafos abaixo. Caso você já conheça o conceito, pode pular essas linhas.
Imagine que você ganha 5 mil reais mensais de salário, e tem um carro no valor de 50 mil reais. Caso a correlação entre essas duas variáveis, salário e carro, seja perfeita e direta, poderíamos concluir que alguém que tem ganha 10 mil reais mensais, terá um carro no valor de 100 mil reais.
Isto acontece pois na correlação perfeita e direta as variáveis se movimentam na mesma direção e proporção. Se uma dobra de valor, a outra também; se uma cai pela metade, a outra fará mesmo. Na prática sabemos que existe uma relação direta entre essas variáveis, mas não perfeita, pois, na média, as pessoas que ganham mais acabam tendo um carro de maior valor, mas nem sempre na mesma proporção, e em alguns casos apesar do salário maior, o carro poderá ser de menor valor.
Imagine agora que você tem 10 anos de trabalho, e com mais 20 anos se aposentará. Outra pessoa, do mesmo ramo que o seu, tem 15 anos de trabalho, ou seja, faltam 15 anos para ela se aposentar. Se essa correlação fosse direta como no exemplo anterior, ao aumentar o tempo trabalhado, o tempo restante de trabalho também deveria aumentar, porém isso não acontece.
Logo, trata-se de uma correlação inversa. Novamente sabemos que na prática essa correlação não será perfeita, pois as pessoas se aposentam com tempos totais de trabalho diferentes.
Abaixo temos o resultado da correlação existente entre 11 variáveis em um determinado dataset. Com um olhar rápido, tente identificar as correlações altas, sendo diretas ou inversas.
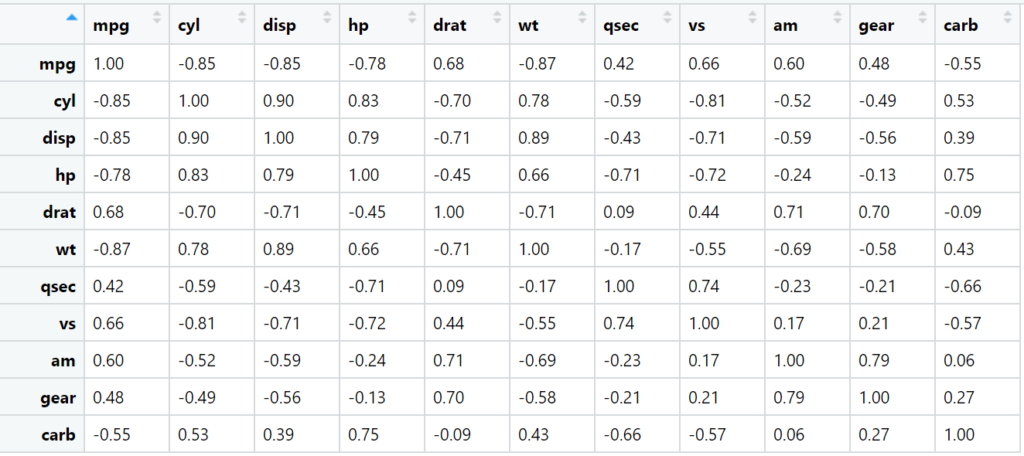
Complicado, não? São muitos números para analisar, e após localizar o que buscamos, se não anotarmos, facilmente esqueceremos. Agora faça o mesmo através do mapa de calor abaixo:
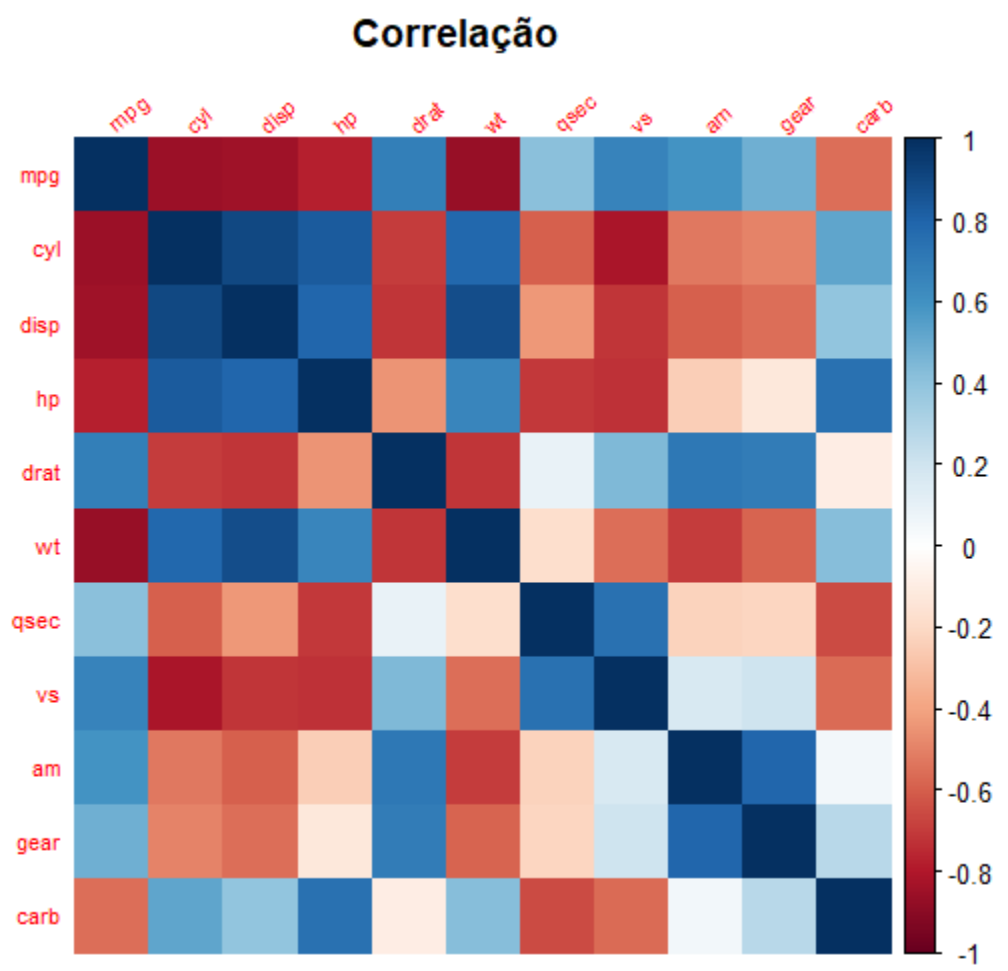
Neste exemplo fica evidente a grande vantagem em utilizarmos as visualizações, principalmente para análises de grandes conjuntos de dados.
Facilmente identificamos as variáveis com alta correlação direta, que estão em azul forte, as com alta correlação indireta, em vermelho forte, e as com baixa correlação, que aparecem em tons claros.
Apresentação do resultado final
Conforme mencionamos, o principal objetivo de um modelo de machine learning são as previsões que ele irá realizar. Este resultado pode ser entregue de muitas formas. Desde um simples arquivo com cada previsão, até mesmo uma aplicação capaz de responder as previsões a cada nova entrada recebida, em tempo real.
Uma alternativa muito interessante é utilizar a visualização de dados nesta entrega. Com ela, além de apenas enviar uma relação de valores ao término da análise, também poderemos indicar, de maneira visual e objetiva, o que as previsões revelam.
Este visual poderá ainda conter informações sobre os dados já registrados, indicando relações entre o que se sabe e o que se busca saber, dentre outras possibilidades.
Existem casos onde tal estratégia pode não ser a melhor, porém, certamente, em grande parte das situações uma entrega como esta valorizará, e muito, a análise realizada.
Uma das principais ideias, é fazer com que quem analisa os resultados das previsões, possa ter total entendimento delas de maneira simples e rápida, respondendo as possíveis perguntas que possam existir sobre a relação dos dados passados e futuros.
Apoio na construção dos modelos de machine learning
 Em grande parte das situações, a avaliação do desempenho do modelo de machine learning utilizado pode ser complexa, não sendo suficiente apenas um valor absoluto, como por exemplo a quantidade de acertos registrada, para definir se um modelo é melhor que o outro.
Em grande parte das situações, a avaliação do desempenho do modelo de machine learning utilizado pode ser complexa, não sendo suficiente apenas um valor absoluto, como por exemplo a quantidade de acertos registrada, para definir se um modelo é melhor que o outro.
Considerando esta realidade, a visualização de dados pode ser de grande utilidade neste contexto. Com ela podemos cruzar informações de maneira rápida, com objetividade e clareza, facilitando a análise para uma melhor conclusão sobre o desempenho do modelo, e comparação com outros.
Vale destacar que, conforme o título deste tópico, neste momento a visualização de dados é utilizada como apoio, não recebendo destaque, e podendo nem ser necessária.
Ou seja, com a exceção de casos específicos, os gráficos gerados serão utilizados para conclusões rápidas, e não para serem utilizados em uma apresentação final.
Com isso, não há necessidade de belos visuais, com legendas para leigos e o que mais se possa imaginar. Basta que o próprio analista seja capaz de interpretar o que está criando, de forma rápida e eficaz, para que a visualização de dados cumpra seu papel com excelência.
Aprenda machine learning do zero
Para que tudo isso que falamos faça sentido, é indispensável um bom conhecimento no ramo do machine learning e da inteligência artificial. Apesar de envolver conceitos complexos, este pode ser um aprendizado simples e prazeroso, e este é nosso objetivo. Com muita didática, e focando no aprendizado dos alunos, montamos nossos cursos, com opções gratuitas e completas, indo do zero até temas complexos e atuais. Clique aqui e confira!
Leia também:
