Em português, Random Forest significa floresta aleatória. Este nome explica muito bem o funcionamento do algoritmo.
Em resumo, o Random Forest irá criar muitas árvores de decisão, de maneira aleatória, formando o que podemos enxergar como uma floresta, onde cada árvore será utilizada na escolha do resultado final, em uma espécie de votação.

Métodos Ensemble
Para entender o algoritmo RandomForest, precisamos primeiramente conhecer os métodos ensemble, dos quais ele faz parte.
Estes métodos são construídos da mesma forma que algoritmos mais básicos, como regressão linear, árvore de decisão ou knn, por exemplo, mas possuem uma característica principal que os diferenciam, a combinação de diferentes modelos para se obter um único resultado.
Essa característica torna esses algoritmos mais robustos e complexos, levando a um maior custo computacional que costuma ser acompanhando de melhores resultados.
Normalmente na criação de um modelo, escolhemos o algoritmo que apresenta o melhor desempenho para os dados em questão. Podemos testar diferentes configurações deste algoritmo escolhido, gerando assim diferentes modelos, mas no fim do processo de machine learning, escolhemos apenas um.
Com um método ensemble serão criados vários modelos diferentes a partir de um algoritmo, mas não escolheremos apenas um para utilização final, e sim todos.
Com esta me todologia, poderemos ter um resultado para cada modelo criado. Se criarmos 100 modelos, teremos 100 resultados, que serão agregados em apenas um.
todologia, poderemos ter um resultado para cada modelo criado. Se criarmos 100 modelos, teremos 100 resultados, que serão agregados em apenas um.
Em problemas de regressão poderá ser utilizada a média dos valores para obtenção do resultado final, e em problemas de classificação o resultado que mais se repete será o escolhido.
Há casos onde o resultado de um modelo será utilizado na criação do próximo, criando uma dependência entre os modelos, e levando a um único resultado final, gerado a partir de vários resultados intermediários.
Muitos métodos ensemble dependem do conceito de árvore de decisão, sendo de grande valia o conhecimento deste conceito no aprendizado dos métodos. Inclusive, quem já conhece árvores de decisão aprenderá os métodos ensemble com muita facilidade e rapidez.
Como funciona o algoritmo RandomForest
Como já mencionamos, no algoritmo RandomForest serão criadas várias árvores de decisão, sendo este conhecimento fundamental para o entendimento do algoritmo.
Árvores de Decisão (Decision Trees)
As Árvores de Decisão, ou Decision Trees, estabelecem regras para tomada de decisão. O algoritmo criará uma estrutura similar a um fluxograma, com “nós” onde uma condição é verificada, e se atendida o fluxo segue por um ramo, caso contrário, por outro, sempre levando ao próximo nó, até a finalização da árvore.
Com os dados de treino, o algoritmo busca as melhores condições, e onde inserir cada uma dentro do fluxo. Para conhecer todos os detalhes deste processo, confira o vídeo abaixo:
Seleção de amostras
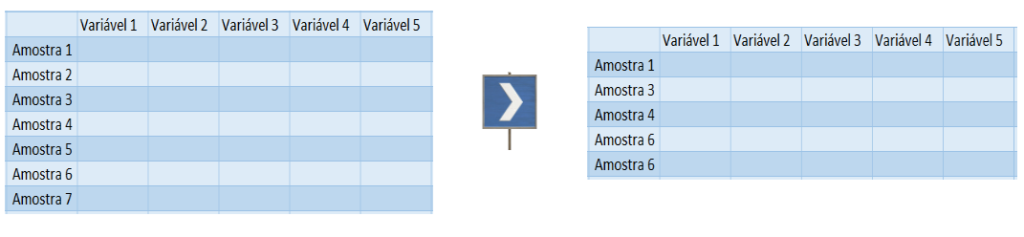
Diferentemente do que acontece na criação de uma árvore de decisão simples, ao utilizar o RandomForest, o primeiro passo executado pelo algoritmo será selecionar aleatoriamente algumas amostras dos dados de treino, e não a sua totalidade.
Nesta etapa é utilizado o bootstrap, que é um método de reamostragem onde as amostras selecionadas podem ser repetidas na seleção. Com esta primeira seleção de amostras será construída a primeira árvore de decisão.
Seleção das variáveis para cada nó
Conforme vimos nos detalhes sobre a construção de uma árvore de decisão, para começar é preciso definir o primeiro nó da árvore (nó raiz), que será a primeira condição verificada, dando origem aos dois primeiros ramos.
Utilizando o algoritmo de entropia ou o índice Gini, será escolhida a melhor variável para compor o nó raiz, variando de acordo com o método utilizado.
No RandomForest a definição desta variável não acontece com base em todas as variáveis disponíveis. O algoritmo irá escolher de maneira aleatória (random) duas ou mais variáveis, e então realizar os cálculos com base nas amostras selecionadas, para definir qual dessas variáveis será utilizada no primeiro nó.
Para escolha da variável do próximo nó, novamente serão escolhidas duas (ou mais) variáveis, excluindo as já selecionadas anteriormente, e o processo de escolha se repetirá. Desta forma a árvore será construída até o último nó. A quantidade de variáveis a serem escolhidas pode ser definida na criação do modelo.
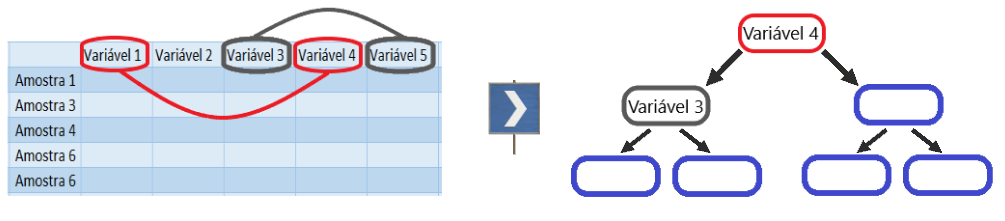
É evidente que este não é o melhor método para construção de uma árvore de decisão. O algoritmo pode, sem querer, selecionar as duas piores variáveis na primeira seleção, escolhendo uma variável péssima para o primeiro nó. Mas como serão construídas muitas árvores, essa estratégia se torna poderosa, e costuma evitar o overfitting.
Construção das próximas árvores
Na construção da próxima árvore, os dois processos anteriores se repetirão, levando a criação de uma nova árvore. Provavelmente essa árvore será diferente da primeira, pois tanto na seleção das amostras, quanto na seleção das variáveis, o processo acontece de maneira aleatória.
Podemos construir quantas árvores quisermos, sendo que quanto mais árvores criadas, melhor serão os resultados do modelo, até determinado ponto, onde uma nova árvore não conseguirá levar a uma melhora significativa no desempenho do modelo.
É importante lembrarmos que quanto mais árvores forem criadas, maior será o tempo de criação do modelo.
Prevendo novos valores
Com o modelo de machine learning devidamente criado, podemos apresentar novos dados e obter o resultado da previsão. Cada árvore criada irá apresentar o seu resultado, sendo que em problemas de regressão será realizada a média dos valores previstos, e esta média informada como resultado final, e em problemas de classificação o resultado que mais vezes foi apresentado será o escolhido.
Como aprender mais?
Para aprofundar seus conhecimentos em machine learning e análise de dados, confira aqui todos os nossos cursos, com explicações detalhadas sobre cada algoritmo utilizado, além de aulas práticas totalmente didáticas.
Você irá perceber que temos 4 módulos de cursos de machine learning, do básico ao avançado. No módulo II, utilizamos o random forest para resolver problemas reais.
Leia também:
