![]() O caret é um pacote da linguagem R desenvolvido para treinamento de modelos de classificação e regressão. Dificilmente você irá trabalhar com machine learning no R sem utilizar este pacote em algum momento.
O caret é um pacote da linguagem R desenvolvido para treinamento de modelos de classificação e regressão. Dificilmente você irá trabalhar com machine learning no R sem utilizar este pacote em algum momento.
Ele não possui os algoritmos de machine learning em suas funções, mas faz uso de outros pacotes para essa finalidade, permitindo assim que sejam utilizados muitos algoritmos a partir da mesma função, apenas alterando seus parâmetros.
Função train(): criando o modelo
Uma das principais funções do pacote é a train(), que possibilita a criação dos modelos de machine learning. Ao utilizar a função, o algoritmo escolhido será aplicado aos dados, gerando como resultado um modelo devidamente treinado, pronto para teste, e posterior utilização na previsão de novos valores.
Normalmente as funções que executam algoritmos de machine learning esperam receber os dados formatados de maneiras diferentes. Essa realidade faz com que precisemos adequar o pré-processamento dos dados ao algoritmo que iremos utilizar, realizando os ajustes e conversões necessárias.
A função train() nos livra desse problema e facilita o processo. Com ela o dataset poderá ser uma matriz, um dataframe, ou ainda possuir outro formato, desde que as colunas sejam nomeadas, e este mesmo dataset poderá ser utilizado com diferentes algoritmos, sem necessidade de ajustes.
Parâmetro method: definindo o algoritmo
Para definir o algoritmo a ser utilizado no treinamento, precisamos passar a informação no parâmetro method da função. Neste link encontramos todos os algoritmos que podem ser utilizados. Hoje são exatas 238 possibilidades diferentes, deixando evidente o quão poderoso é o pacote caret.
Este não é o número de algoritmos que podem ser utilizados, pois um mesmo algoritmo pode aparecer mais de uma vez na lista, sendo aplicado por um pacote diferente, e com configurações diferentes, mas dificilmente você precisará de um algoritmo que não esteja disponível.
Validação cruzada kfold
A técnica de validação cruzada determina como os dados serão separados para criação do modelo.
Normalmente dividimos os dados entre treino e teste, para que o modelo possa ser devidamente treinado, e posteriormente testado, porém existem outras alternativas para criação de um modelo de machine learning. Umas delas é a validação cruzada kfold (k-fold cross validation).
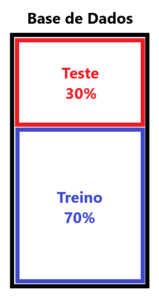 Ao separar os dados em treino e teste, estamos separando os dados em dois grupos. No grupo de dados de treino estão os dados que serão apresentados ao modelo para sua criação.
Ao separar os dados em treino e teste, estamos separando os dados em dois grupos. No grupo de dados de treino estão os dados que serão apresentados ao modelo para sua criação.
Ou seja, o modelo não terá nenhuma influência dos dados que ficaram no grupo de teste. Quando o modelo passar para etapa de teste, sabemos que os dados apresentados nunca foram vistos pelo modelo, como se fossem dados novos, até então não inexistentes. Na imagem ao lado vemos a representação dessa separação.
Na validação cruzada kfold, continuamos com o mesmo objetivo, treinando o modelo através de um grupo de dados, e testando com outro que não fez parte do treinamento.
Mas a separação dos dados acontece de forma diferente. O dadaset será dividido em k grupos (folds), com o mesmo número de dados em cada um, e essas divisões serão agrupadas de maneira que os dados de treino serão compostos por k-1 grupos, pois o grupo que não faz parte dos dados de treino será utilizado para teste do modelo.
E qual a razão de separarmos os dados em mais de dois grupos, para depois os agruparmos novamente? A ideia aqui é que o modelo não será criado apenas uma vez, mas sim o número de vezes necessários para que cada grupo seja utilizado como grupo de teste em uma rodada de criação. Desta forma, o número de modelos criados será igual ao valor de k, que indica o número de grupos formados. A imagem abaixo representa essa separação.
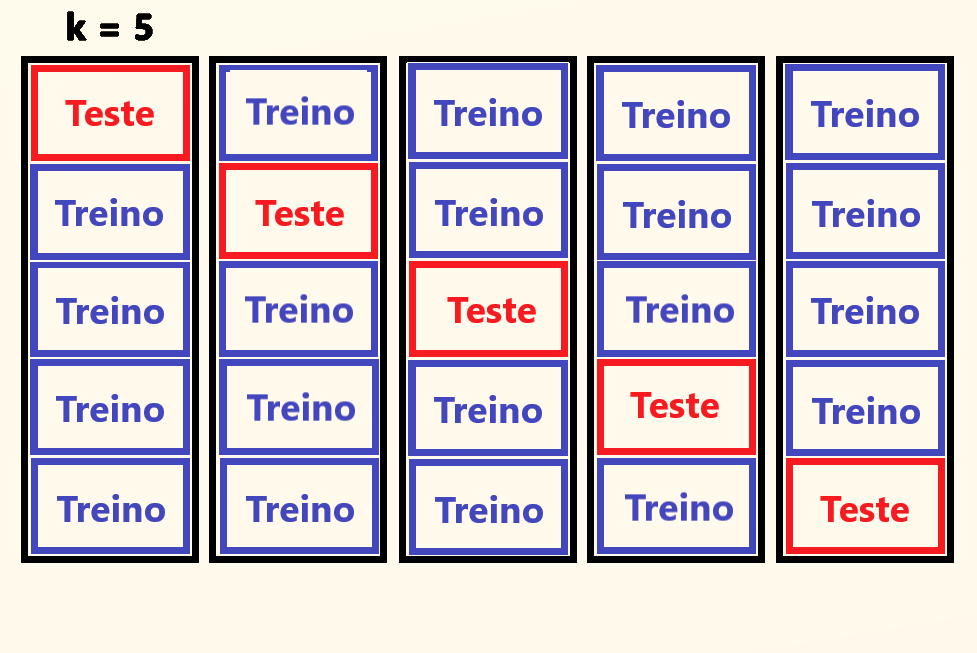
Com este método garantimos que todos os dados sejam utilizados tanto para treino, quanto para teste, sendo que para teste apenas uma vez, e para treino k-1 vezes, tendo como ponto negativo o custo computacional, por conta da criação de vários modelos, ainda que precisemos de apenas um.
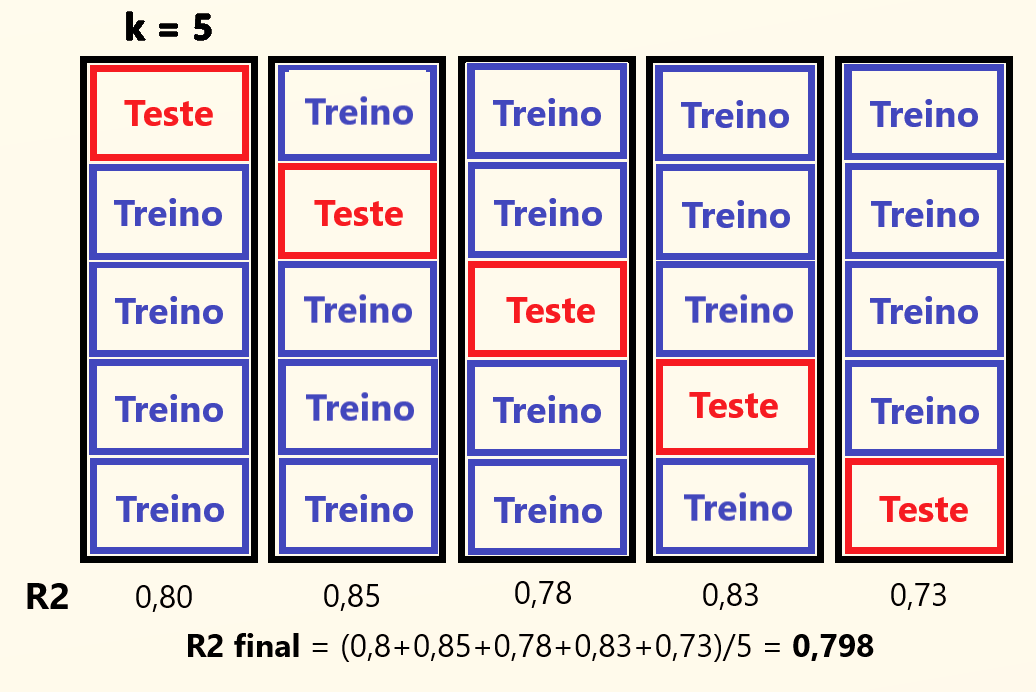
Criando mais de um modelo, teremos mais de um resultado. Portanto se tivermos um k igual a 5, teremos 5 resultados, com k igual a 10, 10 resultados, e assim por diante.
Porém é importante observar que todos estes modelos foram criados da mesma forma, com os mesmos parâmetros, e com o mesmo algoritmo, permitindo que um modelo com essas características receba uma avaliação média com base em todos os resultados. Assim temos que calculando a média dos resultados obtidos, chegamos a um valor final único, que reflete a avaliação final do modelo.
Parâmetro trControl: utilizando a validação cruzada kfold
No parâmetro trControl podemos passar a função trainControl(), que possibilita uma série de configurações para o treinamento, além daquelas disponíveis originalmente na função train().
Uma dessas configurações diz respeito a forma como os dados serão separados, sendo possível a validação cruzada kfold. Para isso basta indicarmos o parâmetro method como “cv” (cross validation), e o parâmetro number com o número de grupos (folds) que deverão ser criados.
Parâmetro tuneGrid: configurando o algoritmo
Cada algoritmo de machine learning possui seus próprios parâmetros de ajuste, que permitem diferentes formas para criação de um modelo. Quando criamos um modelo utilizando uma função de um algoritmo em específico, nessa mesma função configuramos seus parâmetros, de maneira a obter a melhor performance possível do algoritmo.
Com o parâmetro tuneGrid temos essa possibilidade. Na tabela que contém os 238 métodos disponíveis na função train(), temos também a indicação dos parâmetros de ajuste de cada algoritmo.
Informando um dataframe ao parâmetro tuneGrid, definimos cada coluna com o nome do parâmetro de ajuste que queremos utilizar, podendo assim informar diferentes valores, testando o número de combinações que quisermos.
Cada combinação levará a criação de um modelo diferente, gerando também um resultado diferente. Porém neste momento não faz sentido calcular a média desses resultados, uma vez que são gerados a partir de parâmetros únicos. A combinação que apresentar melhor resultado será utilizada.
Parâmetro tuneLength: testando diferentes configurações
Com o parâmetro tuneGrid, nós definimos os valores de ajuste do algoritmo, sendo que serão testados apenas esses valores. Em muitas situações, pode ser mais interessante permitir que a função teste valores definidos por ela própria, para então visualizarmos o desempenho do algoritmo com os diferentes ajustes, podendo ainda passar valores específicos, caso necessário.
Para essa finalidade, temos o parâmetro tuneLength, que recebe apenas um número. Este número indicará a quantidade máxima de combinações que a função irá testar, limitando assim o tempo de execução.
Normalmente quanto mais combinações testadas, maior a chance de encontrarmos o melhor ajuste para o modelo, mas não podemos esquecer que cada combinação levará a criação de um novo modelo, exigindo muito poder computacional, e na maioria dos casos o tempo de execução pode se tornar significativo, ou mesmo inviável.
Assim como na função trainControl(), na função train() ainda existem muitos parâmetros, com diferentes possibilidades. Neste link você pode verificar toda a documentação relativa a função.
Outras funções do pacote
O caret também pode ser usado em outras tarefas, não se restringindo apenas ao treinamento e criação do modelo. Neste link podemos conferir a documentação completa do pacote, organizada em capítulos, contendo inclusive uma breve introdução. Abaixo vemos todas as finalidades do pacote, conforme descrito na introdução:
- Divisão dos dados
- Pré-processamento
- Seleção de variáveis
- Ajuste do modelo
- Definição de importância de variáveis
Existem muitas funções que possibilitam o alcance destes objetivos, sendo as mais comuns a createDataPartition() e a confusionMatrix().
- createDataPartition(): muito utilizada na separação dos dados em treino e teste, garantindo aleatoriedade a separação.
- confusionMatrix(): utilizada na avaliação do modelo, gera uma confusion matrix (matriz de confusão) com as previsões realizadas, e vários cálculos relativos a matriz.
Caret na prática
Em nosso curso de machine learning com R criamos muitos modelos através do pacote caret, além de passar toda base de machine learning necessária para total entendimento dos conceitos, de maneira prática e teórica, sempre focando na didática. Imperdível!
Leia também:
