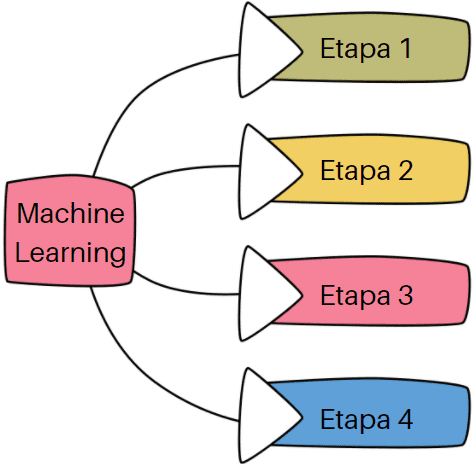
Este artigo será excelente para quem está começando a aprender sobre machine learning e quer entender como funciona o processo geral.
Nós veremos um mapa geral de como resolvemos um problema de machine learning desde o princípio com cada uma das etapas a serem seguidas.
Conhecimento de dados
A primeira etapa é o conhecimento dos dados, o entendimento de qual é o problema que você está tentando resolver. Nós recebemos um conjunto de dados, geralmente em uma tabela cheia de valores.
Mas o que eles significam? O que são cada uma das variáveis? O que estamos tentando prever no problema? É uma previsão de um preço, de uma medida?

Essas perguntas podem fazer parte de uma primeira análise do conhecimento do nosso conjunto de dados, que é essencial para podermos avançar. Não adianta ficar apressado e querer aplicar o modelo de machine learning em uma tabela cheia de valores se não sabemos o que eles significam na prática.
Então, antes de mais nada, é importante entender qual é o problema que estamos tentando resolver.
Pré-processamento e seleção de variáveis
Logo em seguida, vem a etapa de pré-processamento e seleção das variáveis. O que seria essa etapa? Essa etapa abrange várias micro etapas que, apesar do nome micro, são trabalhosas. Nesse momento, ainda não estamos aplicando o machine learning propriamente dito.
Uma das etapas é adequar e formatar os dados. Vamos imaginar que recebemos uma tabela e queremos analisá-la (fazer uma predição e rodar um modelo de machine learning, por exemplo).
No entanto, essa tabela está com dados não formatados; esses dados estão em formato de texto e queremos passá-los para formato numérico. Além disso, há alguns caracteres especiais que queremos remover.
Essa etapa será muito importante, pois usaremos um modelo específico que exigem dados normalizados.
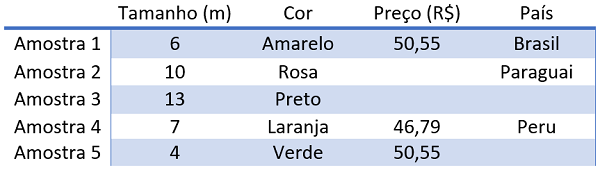
Além disso, pode ser preciso tratar dados faltantes. Algumas dessas amostras podem não apresentar pontos em algumas colunas. Aqui teremos que fazer certas perguntas. O que fazemos com esses dados faltantes?
Vamos eliminar a amostra inteira? Vamos substituir os pontos faltantes por outra coisa? Também há o tratamento dos outliers, que são os pontos fora da curva. Imagine que há uma coluna de alguma variável e alguns valores são muito distantes uns dos outros. Será que vale a pena remover esses valores, ou deixá-los?
Uma outra etapa que também faz parte do pré-processamento é a seleção das variáveis. Ou seja, iremos escolher quais variáveis são as mais relevantes para o problema.
É possível que algumas das colunas não sejam relevantes no nosso conjunto de dados; nesse caso, talvez removê-las seja a melhor escolha. Será necessário avaliar quais das variáveis irão impactar nosso modelo.
Dessa forma, teremos que fazer testes: rodar alguns modelos para decidir quais variáveis são melhores. Em um caso onde existem muitas variáveis e não iremos excluir nenhuma, é possível que seja necessário reduzir dimensionalidades, que é basicamente juntar diversas variáveis em uma só ou em agrupamentos de variáveis. Essa também é uma técnica que faz parte do pré-processamento.
Note que é possível que nosso conjunto de dados já tenha vindo pronto e trabalhado. Nesse caso, melhor ainda, podemos pular as etapas anteriores. Geralmente, entretanto, vamos receber um conjunto de dados que precisa ser tratado.
Então, há toda essa etapa de pré-processamento e seleção das variáveis que precisa ser executada antes de podermos rodar o nosso modelo. É importante destacar que essa etapa exigirá certos conhecimentos de programação, ou a utilização de ferramentas como o Power BI.
Machine learning
 Agora que passamos pelas etapas de conhecimento de dados e pré-processamento, podemos entrar no machine learning propriamente dito. Tudo o que falamos até o momento era apenas o tratamento necessário dos dados para a aplicação dos modelos de machine learning.
Agora que passamos pelas etapas de conhecimento de dados e pré-processamento, podemos entrar no machine learning propriamente dito. Tudo o que falamos até o momento era apenas o tratamento necessário dos dados para a aplicação dos modelos de machine learning.
Com os dados prontos, finalmente podemos escolher o modelo que iremos aplicar em nossos dados. É aqui que a mágica começa.
A boa notícia é que, em termos de programação, essa etapa aqui é muito mais simples que o pré-processamento dos dados. Quem está iniciando na área geralmente fica com medo e acha que é preciso ser especialista em programação para conseguir rodar um modelo de machine learning.
No entanto, não teremos que escrever todo o código de um modelo. O algoritmo já está praticamente pronto, então é só “puxar” o código e executá-lo. Nessa etapa, será necessário conhecer os modelos para escolher qual é o melhor para cada situação.
Medição dos resultados
Com o modelo de machine learning aplicado, iremos para a etapa de medir os resultados. Além disso, iremos escolher qual a forma de medição que será utilizada. Iremos separar os dados em um conjunto de treino e teste? Iremos fazer testes de validação cruzada? Faremos reamostragem?
Essa etapa é muito importante pois, dependendo da performance de nosso modelo no conjunto de dados, saberemos se devemos aperfeiçoar alguma coisa.

Aperfeiçoamento
Caso identifiquemos que seja necessário aperfeiçoar nosso modelo, podemos retornar para a etapa de “escolha e aplicação do modelo de machine learning”. Com isso, podemos testar um modelo novo para ver se conseguimos resultados melhores; ou ainda podemos escolher reutilizar o mesmo modelo com parâmetros diferentes.
Se estivermos usando redes neurais, por exemplo, podemos escolher quantas camadas de neurônios vamos ter; quantos neurônios em cada camada; qual o valor da taxa de aprendizado; qual a quantidade de amostras em cada minilote que entrará para a aplicação do gradiente estocástico. Enfim, os modelos têm diversos parâmetros que podem ser alterados de várias formas que dão resultados diferentes.
Nós podemos ainda, além de voltar para a etapa do machine learning, retornar para a fase de pré-processamento e seleção de variáveis. Assim, podemos tomar decisões diferentes: em vez de excluir os dados faltantes, podemos substituí-los pela média ou pela mediana, por exemplo; se antes tínhamos excluído alguma variável, agora talvez decidamos deixá-las na base de dados; ou, ainda, podemos tratar de forma diferente os outliers.
Nessa lógica, ao darmos tratamentos diferentes para as variáveis, os dados faltantes ou os outliers, nós teremos resultados diferentes.
Em suma, nessa etapa de aperfeiçoamento podemos tanto trabalhar nos modelos de machine learning como também na etapa de pré-processamento de dados. Nós faremos isso até quando percebemos que estamos obtendo resultados satisfatórios.
Nesse processo, iremos nos guiar por uma curva de esforço em relação ao valor que obtivemos. Haverá bastante esforço em tentar melhorar os modelos de machine learning, em voltar para pré-processar os dados, selecionar as variáveis etc.
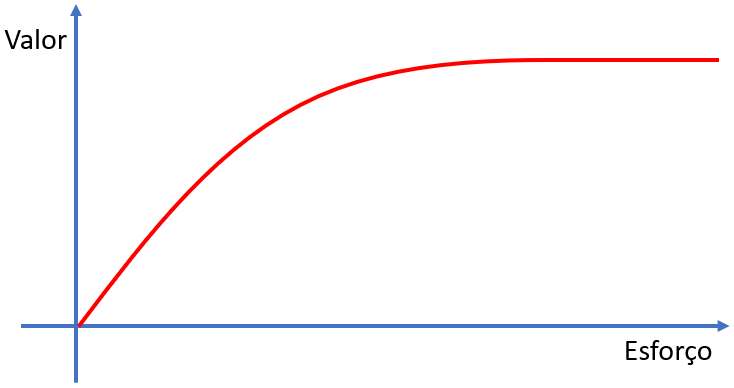
No início, esse esforço irá agregar muito valor; chagará um momento, entretanto, em que atingiremos um limite e, apesar do esforço aplicado, o valor agregado continuará praticamente o mesmo. Ao chegarmos nesse limite, esse é o momento de escolher o modelo final para o conjunto de dados. Assim, podemos parar de retornas às outras etapas e ficaremos com os resultados obtidos.
Uma dica importante
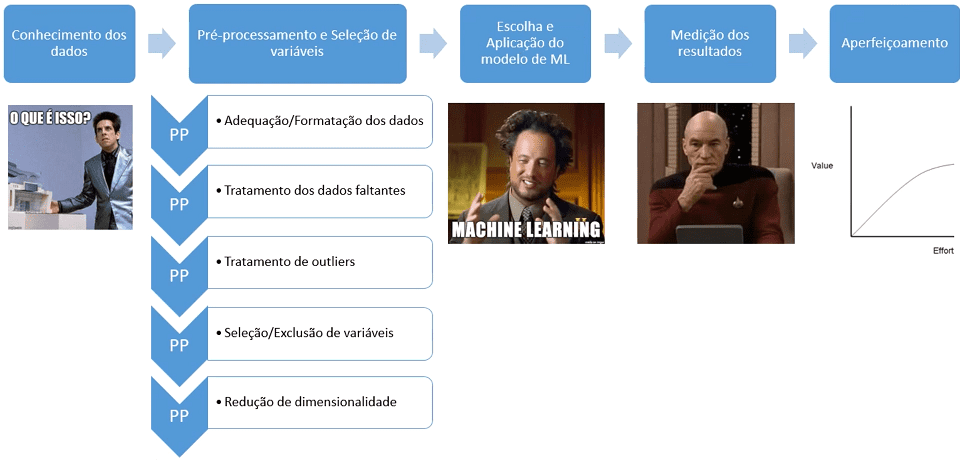
Em resumo, esse é o processo geral do machine learning. Uma dica que damos para quando você estive aplicando o processo é ter esse mapa sempre presente de alguma forma. Tire um print, faça um resumo, um mapa mental ou qualquer outra coisa que preferir.
Isso é muito importante pois, quando você estiver estudando mais a fundo esses conceitos, o ideal é poder se situar e saber em qual etapa do processo você está. Muitas vezes você verá que os conceitos não são necessariamente associados uns aos outros diretamente.
Entretanto, cada assunto específico se liga ao todo neste mapa completo:
Você também pode conferir este assunto no vídeo abaixo. Esta aula faz parte de um minicurso introdutório ao machine learning, então nós recomendamos que você acompanhe todas as outras aulas, pois elas serão essenciais na base de seu aprendizado:
Continue estudando
Aqui, nós te apresentamos um panorama geral. Porém, se você quiser ampliar seu conhecimento, é essencial que se aprofunde em cada uma das etapas sobre as quais falamos nesse artigo. Para isso, nós temos alguns cursos que irão te ajudar muito nesse processo.
Neles, tratamos sobre linguagens de programação, algoritmos de machine learning, redes neurais, e diversos outros assuntos essenciais para um aprendizado completo. O melhor de tudo é que as aulas têm exemplos simples, com muita didática e são focadas no aprendizado do aluno. Confira abaixo:
- Curso de Machine Learning com Python
- Curso de Machine Learning com Linguagem R
- Curso de machine learning com Power BI
Leia também outros artigos:
