 O dplyr é um pacote da linguagem R desenvolvido especificamente para manipulação de dados, muito utilizado em tarefas de pré-processamento para machine learning.
O dplyr é um pacote da linguagem R desenvolvido especificamente para manipulação de dados, muito utilizado em tarefas de pré-processamento para machine learning.
Ele faz parte da coleção de pacotes Tidyverse, que tem como principal desenvolvedor Hadley Wickam, cientista chefe do RStudio e professor de estatística na Universidade de Auckland, Stanford University, e Rice University.
A base do dplyr
Grande parte dos problemas que envolvem manipulação de dados podem ser resolvidos através de cinco funções chave do dplyr. Essas funções, quando devidamente utilizadas, contribuem para uma execução veloz e simples, além de tornar o código claro e de fácil entendimento.
- select(): seleciona variáveis com base em seus nomes.
- filter(): seleciona observações com base em seus valores.
- arrange(): muda a ordem das linhas.
- summarise(): reduz muitos valores em um único resumido.
- mutate(): cria novas variáveis em função das variáveis existentes.
Muitas das operações de manipulação nos dados acontecem em grupos definidos pelas variáveis existentes, sendo necessário que o código contemple estes agrupamentos.
Estas funções trabalham muito bem em conjunto com a função group_by(), que possibilita os agrupamentos mencionados de maneira simples e objetiva.
O operador pipe – %>%
Poucas vezes estas funções aparecerão de maneira independente em um script, pois para utilizarmos todo o potencial do pacote, precisamos criar uma sequência com múltiplas operações.
O operador %>% atua com esta finalidade. Ele faz parte do pacote magrittr, também da coleção Tidyverse, mas o operador normalmente já é carregado com os demais pacotes da coleção, para que não precisemos nos preocupar com isso.
O principal objetivo do operador é possibilitar que a sequência de operações seja realizada com um código simples, de fácil leitura e entendimento. O operador irá aplicar as instruções da esquerda para direita, utilizando o conteúdo existente a esquerda dele na função a direita, até que não existam mais operadores. No exemplo abaixo o funcionamento ficará mais claro.
Exemplo de utilização das funções
Vamos criar uma tabela com informações de alguns carros, de maneira bem simples, apenas para mostrar como utilizar as funções. Para inserir o operador %>% no RStudio é possível utilizar o atalho “Shift” + “Ctrl” + “m”.
Marca <- c("Fiat", "Fiat", "Fiat", "Ford", "Ford", "Honda")
Carro <- c("Argo", "Argo", "Cronos", "Fiesta", "Ecosport", "Civic")
Ano <- c(2018, 2019, 2019, 2020, 2019, 2019)
Preço <- c(44000, 48000, 56000, 52000, 75000, 99000)
Tabela <- data.frame(Marca, Carro, Ano, Preço)
Tabela
#> Marca Carro Ano Preço
#> 1 Fiat Argo 2018 44000
#> 2 Fiat Argo 2019 48000
#> 3 Fiat Cronos 2019 56000
#> 4 Ford Fiesta 2020 52000
#> 5 Ford Ecosport 2019 75000
#> 6 Honda Civic 2019 99000
Apresentaremos as funções de maneira independente, para simplificar o entendimento, e então concluiremos com um exemplo onde algumas serão utilizadas em sequência.
select()
Tabela %>% select(Carro)
#> Carro
#> 1 Argo
#> 2 Argo
#> 3 Cronos
#> 4 Fiesta
#> 5 Ecosport
#> 6 Civic
No código “Tabela %>% select(Carro)” todo conteúdo da variável “Tabela” é apresentado a função select() através do operador %>%. A função então é executada, selecionando as variáveis passadas entre os parênteses.
Caso quiséssemos selecionar mais variáveis, bastaria inserir os nomes de todas as variáveis desejadas, separados por vírgula. Por exemplo, Tabela %>% select(Carro, Ano) traria como retorno o conteúdo das variáveis “Carro” e “Ano”.
filter()
Tabela %>% filter(Ano == 2019)
#> Marca Carro Ano Preço
#> 1 Fiat Argo 2019 48000
#> 2 Fiat Cronos 2019 56000
#> 3 Ford Ecosport 2019 75000
#> 4 Honda Civic 2019 99000
Neste exemplo, continuamos realizando apenas uma operação, com o código “Tabela %>% filter(Ano == 2019)“. Desta vez, mantemos todas as variáveis, pois a função filter() atua nas linhas, filtrando os dados com base na condição que passamos.
Podemos ainda utilizar mais de uma condição. Por exemplo, Tabela %>% filter(Ano == 2019, Marca == “Fiat”) retornando apenas carros do ano de 2019 e da marca Fiat.
arrange()
Tabela %>% arrange(Preço)
#> Marca Carro Ano Preço
#> 1 Fiat Argo 2018 44000
#> 2 Fiat Argo 2019 48000
#> 3 Ford Fiesta 2020 52000
#> 4 Fiat Cronos 2019 56000
#> 5 Ford Ecosport 2019 75000
#> 6 Honda Civic 2019 99000
Com a função arrange() todos os dados são mantidos, porém a organização será alterada conforme o critério informado. “Tabela %>% arrange(Preço)” faz com que as linhas sejam reordenadas com base na variável “Preço”, ficando o menor preço na primeira posição e o maior na última.
Utilizando o código Tabela %>% arrange(Ano, Preço) as linhas primeiramente serão ordenadas com base no ano do carro, e nos casos de anos iguais, o menor preço definirá quem virá primeiro.
summarise()
Tabela %>% summarise(mean(Preço))
#> mean(Preço)
#> 1 62333.33
Com a função summarise() precisamos indicar nos parênteses outra função para definir como os valores em questão devem ser resumidos. Utilizando a função mean(), indicando a variável “Preço”, é apresentada a média dos preços existentes. No exemplo completo, utilizaremos a função group_by() que traz mais utilidade para função summarise().
mutate()
Tabela %>% mutate(Razão = Preço / Ano)
#> Marca Carro Ano Preço Razão
#> 1 Fiat Argo 2018 44000 21.80377
#> 2 Fiat Argo 2019 48000 23.77415
#> 3 Fiat Cronos 2019 56000 27.73650
#> 4 Ford Fiesta 2020 52000 25.74257
#> 5 Ford Ecosport 2019 75000 37.14710
#> 6 Honda Civic 2019 99000 49.03418
Através da função mutate() realizamos a criação de uma nova variável. “Tabela %>% mutate(Razão = Preço / Ano)” cria a variável “Razão” dividindo o conteúdo da variável “Preço” pelo conteúdo da variável “Ano”, linha a linha.
Podemos criar mais variáveis, de diferentes formas, separando cada uma com uma vírgula dentro dos parênteses.
%>%
Até agora o operador %>% não demonstrou seu real poder, uma vez que utilizamos as funções de maneira independente, podendo simplesmente passar o dadaset com as informações dentro dos parênteses da função. Por exemplo, “select(Tabela, Carro)” nos traria o mesmo resultado que “Tabela %>% select(Carro)”. Vamos então utilizar as funções de maneira conjunta e ainda realizando um agrupamento com a função group_by().
Se simplesmente utilizarmos a instrução “group_by(Marca)” os dados serão agrupados utilizando como critério a variável “Marca“. O número de marcas distintas existentes na variável será igual ao número de grupos que serão criados. Abaixo visualizamos a aplicação:
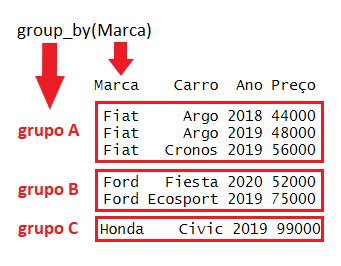
Sequência de instruções
Tabela %>%
filter(Ano == 2019) %>%
group_by(Marca) %>%
summarise(Média = mean(Preço)) %>%
arrange(desc(Média))
#> A tibble: 3 x 2
#> Marca Média
#> <fct> <dbl>
#> 1 Honda 99000
#> 2 Ford 75000
#> 3 Fiat 52000
Com a instrução acima, primeiramente acessamos a variável “Tabela” e realizamos o mesmo filtro já apresentado. Assim o conteúdo passado para a função “group_by(Marca)” será composto por todas as variáveis originais e todas as linhas onde a variável “Ano” é igual a 2019.
A função “group_by(Marca)” irá realizar o agrupamento das informações, tomando como base os dados existentes na variável “Marca“. Os dados, devidamente agrupados, são entregues a função “summarise(Média = mean(Preço))“, que irá resumir os valores da variável “Preço” a apenas um.
Acontece que, neste momento, diferentemente de quando utilizamos a função pela primeira vez, os dados possuem um agrupamento, possibilitando que sejam resumidos por grupo. Desta forma, cada grupo receberá o valor médio de seus preços, e como existem três marcas, serão criados três grupos, sendo apresentados três valores finais.
A variável de retorno não é mais a “Preço“, e sim a média dos preços de cada grupo, por isso nomeamos esta nova variável de “Média“. Se não passássemos nome algum, o nome seria apenas “mean(preço)“.
Esses dados são entregues à função “arrange(desc(Média))” que irá reorganizá-los com base na nova variável “Média“, colocando o maior valor na primeira posição e o menor na última, pelo fato de ter sido utilizada a função “desc()“.
Após este momento, não há mais instruções a serem realizadas e o resultado é apresentado. Segue novamente apenas o resultado:
#> A tibble: 3 x 2
#> Marca Média
#> <fct> <dbl>
#> 1 Honda 99000
#> 2 Ford 75000
#> 3 Fiat 52000
Podemos verificar que o retorno é apresentado em uma “tibble“, que é uma modernização de um “data.frame“, estrutura de dados complexa, similar as planilhas do Excel e com tipos de dados diferentes. A tibble faz parte do pacote tibble, também pertencente a coleção Tidyverse.
Recebemos também a indicação <fct>, mostrando que a variável “Marca” é do tipo fator, e a indicação <dbl>, mostrando que a variável “Média” é do tipo numérica.
Como aprender mais sobre dplyr e machine learning
Pensando nas aplicações da linguagem R necessárias nas etapas de pré-processamento para machine learning, bem como a utilização de algoritmos, desenvolvemos o curso de machine learning com R.
É um curso para iniciantes onde mostramos na prática a utilização dos pacotes dplyr, tidyr, stringr e muito mais, além de aplicar algoritmos de machine learning na prática resolvendo problemas reais. É imperdível.
Você poderá ainda evoluir seus conhecimento em R e Machine Learning de maneira completa no Combo – Módulos I e II de machine learning com R!
Outros artigos relacionados:
