Algoritmos genéticos – nome inspirado na teoria da evolução das espécies, de Charles Darwin – é um tipo de sequência de ações muito utilizado em machine learning.
Devido a sua grande importância para o assunto, aqui daremos um panorama geral de como esse método funciona, bem como alguns exemplos práticos.
Como funciona? Seleção natural na programação!
O que, afinal, é a teoria da evolução e como ela pode ser associada ao aprendizado de máquina?
Explicando de forma superficial, a teoria da evolução consiste no seguinte: diferentes raças de animas cruzam entre si e deixam uma descendência; tal descendência, eventualmente, poderá sofrer alguma mutação genética e passar pelo processo de seleção natural; a partir dessa seleção, os indivíduos com maior probabilidade de sobrevivência passarão seus genes para uma próxima descendência que, por sua vez, também poderá sofrer alguma mutação.
A seleção natural definirá se essa mutação é boa ou ruim. Dessa maneira, mutações ruins – ou aqueles indivíduos que tiverem uma genética desfavorável – têm mais chances de morrer e assim por diante.

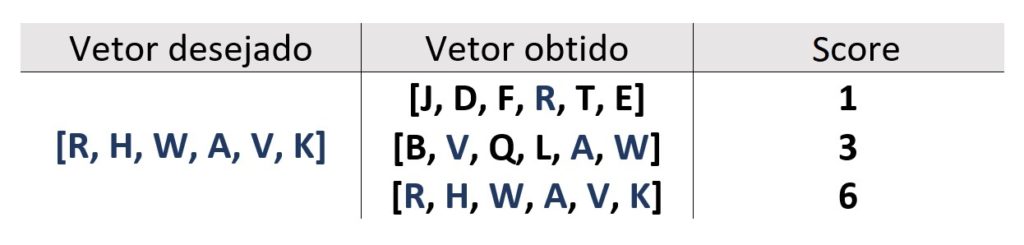
Como, então, seria a lógica de aplicação prática pensando na programação? Primeiro falaremos de um exemplo bem simples: teremos como objetivo criar um vetor que possui, especificamente, seis letras: [R, H, W, A, V, K], independente da ordem.
Começaremos o processo de forma aleatória, com quaisquer letras do alfabeto. Dessa forma, imagine que o vetor criado foi este: [J, D, F, R, T, E]. Se analisarmos quais letras há em comum entre os dois vetores, perceberemos que a letra R está presente em ambos.
Podemos dizer, então, que o score do primeiro vetor obtido [J, D, F, R, T, E] é 1. Em vez de utilizarmos o nome score, também podemos dizer “fitness score”, a palavra fitness se refere a quão acurado está aquele indivíduo em particular.

Podemos imaginar que esse vetor é um indivíduo, e que a nossa fitness function – função de fitness – que queremos maximizar confere a pontuação máxima de 6. Essa função dará uma pontuação de 6 caso o indivíduo possua exatamente as letras do primeiro vetor – [R, H, W, A, V, K]. Ou seja, o fitness score de nosso primeiro indivíduo é de 1, pois ele tem apenas uma das seis letras.
Ao analisarmos o indivíduo [B, V, Q, L, A, W], por exemplo, notamos que ele tem um score de 3, porque as letras V, A e W também estão presentes no vetor que desejamos obter.
Como o fitness score desse último vetor seria 3, ele é um indivíduo com fitness score superior ao indivíduo que analisamos anteriormente. Dessa forma, poderíamos criar vários indivíduos aleatoriamente, atribuir fitness score para cada um deles e escolher o melhor.
Obviamente, esse processo pode ser bastante lento dependendo do problema, afinal estaríamos apenas tentando resolver com o método de “força bruta”, contando com a sorte, gerando valores ao acaso na esperança de, em algum momento, obter a solução desejada. Existem formas mais eficientes de se trabalhar, como aplicar crossover e mutação.
Aprofundando a seleção natural: crossover e mutação
Depois de uma primeira criação aleatória de indivíduos, podemos seguir com dois importantes passos no método de algoritmos genéticos: crossover e mutação.
O crossover está diretamente ligado à ideia da hereditariedade; a mutação está ligada ao surgimento de novas características nos indivíduos.
Ou seja, os pais – o macho e a fêmea – se cruzam e têm descendentes; nós escolheremos os indivíduos pais que gerarão os seus filhos e, depois, aplicamos uma mutação em toda essa nova geração.
Como funciona a Mutação
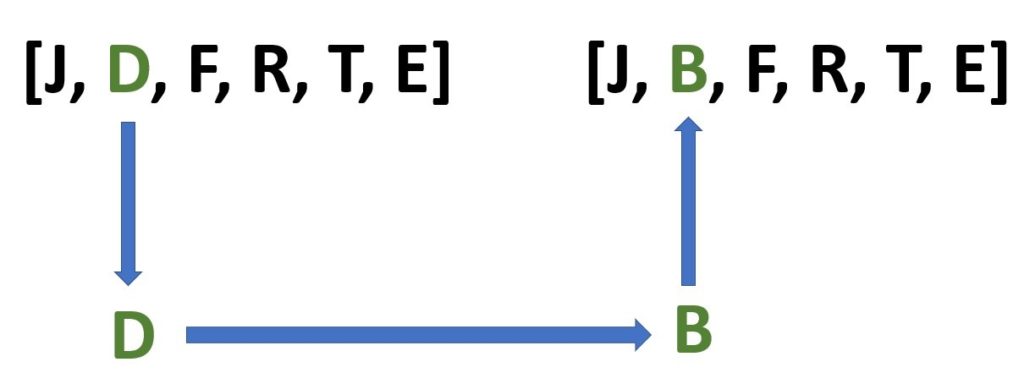
A mutação, nesse caso específico que estamos analisando, poderia ser uma alteração de uma letra aleatoriamente. Tomemos por exemplo novamente o vetor [J, D, F, R, T, E].
Uma mutação nesse vetor poderia ser tomar uma letra sorteada aleatoriamente e escolher uma nova letra, randomicamente, para substituí-la.
Digamos que a letra D foi sorteada e substituída pela letra B. Nesse caso, houve uma mutação: uma letra foi substituída por outra. Assim teremos um novo vetor: [J, B, F, R, T, E].
Como funciona o Crossover
O crossover, por sua vez, poderia ser da seguinte forma: tomemos os vetores [J, D, F, R, T, E] e [B, V, Q, L, A, W]; agora, escolheríamos aleatoriamente duas letras – duas posições no vetor – que seriam trocadas entre si.
Vamos imaginar que as duas posições sorteadas foram a terceira e a última posição. Neste caso, as letras trocarão de lugar entre os vetores, ou seja, na terceira posição o Q irá para o lugar do F e vice-versa; e na última, as letras E e W também irão uma para o lugar da outra.
Assim, teremos dois novos vetores: [J, D, Q, R, T, W] e [B, V, F, R, A, E].
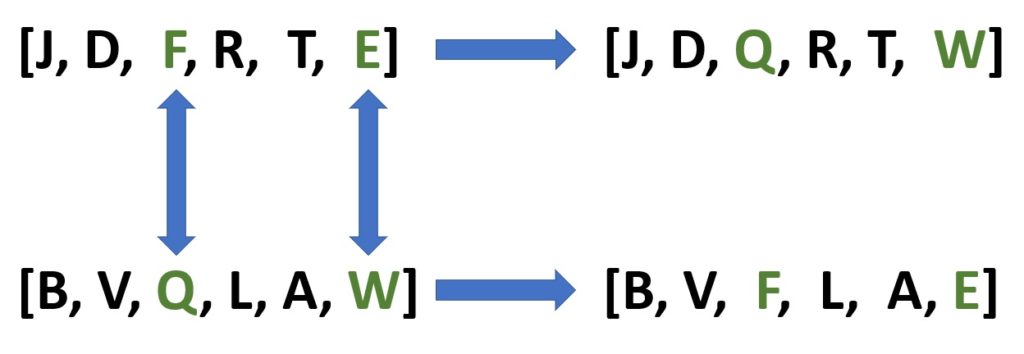
Basicamente, o crossover é uma mistura das informações entre dois vetores. Ou seja, os vetores resultantes são “pais” que geram “filhos”. O pai [J, D, F, R, T, E] gera um filho [J, D, Q, R, T, W] com sua estrutura – as letras J, D, R e T, mas também com características do outro vetor, as letras Q e W.
Da mesma forma, o vetor pai [B, V, Q, L, A, W] gera um filho [B, V, F, L, A, E] com sua estrutura, as letras B, V, L, A, mas também com características do outro vetor, as letras F e E.
No exemplo anterior, utilizamos apenas 2 indivíduos; imaginemos, entretanto, a seguinte situação: temos uma população de 100 indivíduos (vetores), cada um com 6 letras.
A tais vetores, aplicaríamos a fitness score, em cada um, para saber quais são seus scores. Tendo sido determinados todos os scores, nós eliminaríamos os scores mais fracos e ficaríamos apenas com os “sobreviventes”. Vamos supor que tenhamos ficado com trinta vetores sobreviventes, os mais fortes, com os maiores fitness score.
Na metade desses indivíduos, nós aplicaríamos crossover para gerarmos uma nova descendência. Após isso, aleatoriamente, escolheríamos 10% dessa população para aplicarmos uma mutação. Tudo isso seria um exemplo de crossover e mutação sendo aplicados nessa população inicial.
Depois de se fazer esse crossover e essa mutação, podemos, agora, aplicar uma nova seleção natural que vai escolher quais são os indivíduos melhores – aqueles com maiores fitness score. Após essa seleção, fazemos novamente o processo de aplicar o crossover e a mutação.
Passos de um processo de algoritmo genético
Os seguintes passos esclarecem melhor o processo de um algoritmo genético:
-
- Criar uma população de N indivíduos;
- Avaliar os fitness scores de cada indivíduo;
- Eliminar os mais fracos (realiza-se uma “competição”, uma seleção que imitará uma seleção natural);
- Fazer reprodução (crossover) e/ou mutação, e retornar ao passo 2.
Da forma destacada acima, podemos repetir iterativamente esse processo até que um critério de parada seja atingido.
Como estabelecer um Critério de parada

O que seria um critério de parada? Poderia ser quando pelo menos um indivíduo tenha um determinado fitness score. No exemplo dos vetores, utilizado anteriormente, o sistema só pararia depois que encontrasse um indivíduo que tenha um fitness score de 6, ou seja, o máximo.
Outro critério de parada poderia ser quando chegarmos a um número máximo de gerações.
Após uma reprodução ou uma mutação (passo 4), avaliamos os novos fitness scores, nesse momento temos uma nova geração; a próxima geração será quando aplicarmos novamente a reprodução, a mutação, a seleção natural e assim por diante.
Cada vez que esse processo é repetido e iterado, temos uma nova geração. Então, o critério de parada pode ser este: o máximo de iterações – por exemplo, 1.000 gerações. Ao final, avaliaremos qual é o indivíduo que tem o maior fitness score depois de mil gerações.
Ou seja, o critério de parada é uma característica que determinará ao meu sistema que é o momento de parar as ações; literalmente um sinal de pare.
O fato é que vamos iniciar com uma população randômica de indivíduos e depois aplicaremos o conceito de algoritmo genético até que cheguemos em um indivíduo que possua um score aceitável, que consideremos que já esteja relevante e bom o bastante.
Variação, hereditariedade e seleção
O processo, como um todo, é constituído de três pontos-chave: variação, hereditariedade e seleção. A variação é o fato de os indivíduos serem diferentes; a hereditariedade é a possibilidade de eles gerarem filhos (cruzar, misturar os seus genes, suas características); a seleção é a própria seleção natural que vai eliminar os mais fracos e ficar com os indivíduos com melhor fitness score.
O conceito de crossover – cruzamento de vetores – pode ter diversas aplicações práticas e dependerá muito de cada problema. No exemplo de letras, como já comentamos, o crossover poderia ser a troca das características – como se cada indivíduo fosse um gene, fazendo uma comparação com o conceito biológico de seleção natural.
Entretanto, se estamos com um problema de uma rede neural, por exemplo, em que nossos indivíduos possuem dados numéricos que sejam valores não inteiros (0,25 por exemplo), trocar os números de lugar pode não fazer tanto sentido.
Nesse caso, talvez, o melhor seria fazer uma média dos vetores: um dos filhos de dois vetores pode ser a média de alguns genes específicos desses dois vetores. Outro exemplo seria a multiplicação por uma constante e a subtração por outra de outro vetor.
Ou seja, fazer uma mistura (blending) entre esses indivíduos. Percebe-se, então, que o modo como faremos esse crossover dependerá muito dos dados com que estamos trabalhando; há inúmeras formas diferentes de se fazer crossover.
O que não mudará em nenhum tipo de crossover, entretanto, é a característica de garantir que o nosso sistema produzirá indivíduos mais fortes: os indivíduos que sobrevivem a várias gerações – várias competições e torneios (seleções naturais) – são indivíduos que têm características melhores; são indivíduos com scores altos.
Portanto, faz sentido querermos preservar as boas características de indivíduos e tentarmos mudá-los um pouco (realizar mutações) para ver se conseguimos que eles melhorem ainda ainda mais. A hereditariedade proporciona que o sistema preserve boas características entre os indivíduos, o que permite que tais características não sejam totalmente esquecidas de uma geração para outra.

Ao cruzarmos vários indivíduos que têm características positivas, pode ser que em algum desses cruzamentos um indivíduo se saia melhor do que o esperado. Isso se dá pois ele pode ter adquirido características boas de um pai e eliminado características ruins de outro.
Dessa forma, o filho ficaria mais forte que o pai. Em outros casos, é possível que alguns filhos fiquem piores do que os pais. O que solucionará o problema será a seleção natural: a sobrevivência do mais forte.
A mutação, por sua vez, está diretamente ligada com a ideia de variabilidade. É importante que haja mutações, pois, se a nossa criação inicial randômica não tiver uma variabilidade suficiente, o crossover ocorrerá com indivíduos que cruzarão os mesmos dados entre si.
Desse modo, é possível que alguma característica muito importante – que daria um score alto para os indivíduos – não tenha aparecido em nenhum indivíduo inicial. Por consequência, essa característica nunca será gerada depois.
Isso ocorre porque o crossover só mistura os dados, ele não gera informações novas. Quem é capaz de gerar novas informações é a mutação: ela pode gerar dados totalmente novos de forma randômica, a partir do acaso.
A mutação, por um lado, pode piorar os indivíduos, no sentido de que ela pode “bagunçar” uma característica boa e gerar nova característica que não seja útil. Ao final, o que provará se tais características são boas ou não será a seleção natural que ocorrerá posteriormente.
Por isso, sempre ao realizarmos a técnica de algoritmos genéticos, temos que experimentar tanto a mutação como o crossover. É importante que sejam estabelecidos parâmetros para cada um desses processos: qual a probabilidade de indivíduos executarem o crossover, por exemplo; ou qual a probabilidade de eles sofrerem de mutação.
Dependendo do tipo de problema, é possível, ainda, calibrar ou fazer ajustes finos no sistema, pois ele pode requerer variabilidades ou mutações muito altas para conseguir chegar ao objetivo. Isso tudo poderemos fazer da mesma forma que calibramos os dados de qualquer algoritmo de machine learning.
Em suma, podemos ver que o conceito de algoritmos genéticos é de simples compreensão. Começa-se com uma população que, geralmente, é representada como um vetor de características – uma lista de letras ou números, por exemplo.
Podemos, assim, estabelecer uma população inicial de características, com vários indivíduos; depois essa quantidade de indivíduos passará por vários processos de seleção natural que avaliarão os seus fitness scores, passará por crossover e mutação, e assim seguirá iterativamente. Ao final do processo, basta avaliar os indivíduos e selecionar aqueles que tenham o maior fitness score calculado.
Aplicação prática
Entendidos esses conceitos básicos, podemos avançar para as suas aplicações em casos práticos, o que é um dos nossos principais interesses no mundo da inteligência artificial.
Um exemplo disso seria a calibração de redes neurais. Ou seja, como poderíamos utilizar o conceito de algoritmos genéticos e aplicá-lo para fazer o ajuste fino dos pesos e bias de uma rede neural.
Em nosso curso Aprendizado por Reforço, Algoritmos Genéticos, NLP e GANs vemos esses e outros assuntos em detalhes, com aplicações práticas através da linguagem Python.
Além disso, também temos diversas opções de cursos – do básico ao avançado – sempre focados no aprendizado e na didática. Confira aqui!
Leia também:
