
Neste artigo, falaremos um pouco sobre dados missing: os dados faltantes. Antes de você partir para a prática e aprender a substituir dados faltantes, por exemplo, é importante conhecer um pouco sobre esse conceito, pois ele é muito importante na área de inteligência artificial.
Leia até o final e você verá que é muito simples de entender.
Explicando o conceito
É muito comum que um conjunto de dados não esteja totalmente preenchido. Dessa forma, ele terá, em algumas colunas ou linhas, valores chamados “NaN” (do inglês “Not a Number”), que são os valores faltantes.
Isso ocorre, pois, muitas vezes, quem estava coletando o conjunto de dados não encontrou a informação necessária; ou ainda, no momento de se transferir os dados de um lugar para outro, a informação foi perdida; enfim, há vários motivos que podem fazer com que um dado falte em uma base de dados.
Além disso, é possível que um dado esteja faltando apenas em uma variável. Por exemplo, vamos imaginar que estamos tentando prever preços de casas. Para isso, temos um banco de dados com as variáveis (representadas pelas colunas): número de quartos, número de banheiros, área da casa, número de andares e preço. Entretanto, na variável “andares”, algumas informações estão ausentes.
Ou seja, não sabemos a quantidade de andares de algumas casas: esses são dados faltantes. Confira a tabela abaixo:
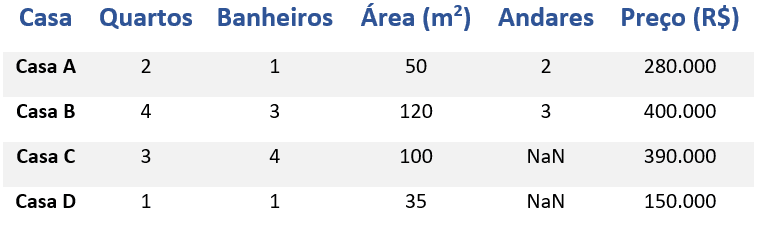
Repare que temos apenas um dado faltante por linha; todos os outros dados estão presentes. Além disso, o algoritmo conseguiu prever o preço das casas mesmo sem essas informações. O que se faz em um caso como esse? Vale a pena deletar essa linha por causa dessa única informação que está faltando? Vale a pena substituir essa informação por outra coisa?
Em suma, o que se faz com os NaN? Essa é uma grande questão no mundo do machine learning. Existem vários estudos e pesquisas acadêmicas a respeito disso para se definir qual seria o melhor procedimento para essas situações.
O nosso objetivo aqui não é dar uma resposta definitiva para o problema. No entanto, a partir de agora, vamos analisar algumas das melhores práticas que os profissionais utilizam nesses momentos.
Lidando com dados faltantes
Para entendermos melhor como se lida com dados missing, vamos considerar alguns cenários. Geralmente, tomaremos nossa decisão analisando os dados faltantes por coluna. Existem algumas colunas, no nosso conjunto de dados, que estarão totalmente preenchidas (sem nenhum dado faltando); outras colunas, porém, não terão todos os dados (teremos dados missing).
Em alguns dos casos, pode ser que poucos dados estejam faltando – apenas dois por cento, por exemplo; já, em outros casos, a ausência de dados pode ser de quarenta ou oitenta por cento. Existem inúmeras possibilidades. Assim, teremos de olhar para cada coluna (cada variável) e decidir caso a caso o que fazer com ela.
Na maioria das vezes, quando há menos de cinco por cento de dados faltando, não precisamos nos preocupar, porque a abordagem que vamos utilizar não fará muita diferença – essa porcentagem de NaN não irá alterar nosso modelo de forma significativa.
Assim, podemos substituir os dados pela média, pela mediana, ou por outra coisa.
Agora, acima de 30% de dados faltantes em uma variável, nós consideramos que essa é uma quantidade alta. Dessa forma, a atitude que tomarmos deve ser considerada com cuidado, pois, nesse caso, podemos ter mudanças relevantes em nosso modelo dependendo da nossa ação. Acima de 60% já é considerado uma anomalia: há muitos dados faltantes.
Em um caso assim, é necessário considerar remover essa variável. Note que esses valores não são exatos: pode haver variações que são aceitáveis. Por isso, é necessário avaliar cada situação para fazer a escolha mais acertada.
O bom senso sempre é válido, pois não existe uma regra que determine exatamente qual a porcentagem de dados missing que invalida uma variável. Você não encontrará nenhuma literatura que afirme, por exemplo: acima de 60%, delete a variável; abaixo de 5%, substitua-a pela média.

Uma das coisas mais relevantes para se levar em consideração é o peso da variável para o problema específico: devemos determinar se a variável é relevante para o modelo ou para o conjunto de dados.
E como sabemos isso? Você pode utilizar algumas técnicas de feature extraction que utilizam algoritmos para determinar quais são as variáveis mais relevantes para determinado modelo.
Por exemplo, se estamos querendo ver o preço de casas, as variáveis mais importantes são o número de quartos e a localização; já a cor da casa é praticamente irrelevante para o resultado final do preço da casa.
Então, ao realizarmos esta etapa (que faz parte do pré-processamento), em que identificamos quais as variáveis mais relevantes, se identificamos uma variável que não é muito relevante e tem uma quantidade grande de dados faltantes, deletamos ela e não iremos nos preocupar muito.
No entanto, se uma variável está com uma quantidade grande de dados faltantes, mas é muito relevante, não podemos simplesmente deletá-la, pois estaríamos tirando fora um dado muito importante que teria um impacto grande no nosso modelo final. Há alguns analistas de dados que preferem nunca deletar nada, porque eles consideram que com isso perderíamos informações; e informação é riqueza. Dessa forma, eles consideram que o modelo estaria perdendo riqueza.

Porém, é tudo uma questão de trade off (ou equilíbrio): por um lado se deletamos coisas importante, estamos perdendo riqueza; por outro lado, se não excluímos informações desnecessárias, estamos acrescentando um pouco de sujeira ao nosso modelo.
Quando nós optamos por não excluir um dado e substituímos ele, nós iremos trocá-lo por algo artificial: a média ou a mediana não são dados que foram, de fato, coletados.
Assim, as informações utilizadas para substituir dados faltantes podem poluir o modelo e fazer com que cheguemos a uma conclusão que não seja verídica: estaremos manipulando artificialmente o resultado.
Em suma, o que vimos até aqui foi:
- Quanto temos pouca quantidade de dados faltantes, não precisamos nos preocupar muito com a abordagem de substituição de dados que estamos utilizando, principalmente em variáveis não muito relevantes.
- Quando temos uma quantidade maior de dados faltantes em variável que é relevante, devemos prestar muita atenção. esse é um dos maiores problemas. Nesses casos, podemos testar a substituição com a média ou com a mediana e analisar os resultados; ou ainda, podemos usar algumas técnicas avançadas de substituição dos dados, como modelos de machine learning específicos para isso.
Além dessas situações que analisamos, existe a uma outra possibilidade: quando temos uma quantidade imensa de dados – como um milhão de linhas, por exemplo.
Nessas linhas, os dados missing podem ser aleatórios (não pertencem a uma característica ou categoria específicas) e a sua quantidade pode não ser relevante a ponto de afetar a qualidade do modelo. Em cenários como esse, não há necessidade de preocupação: é possível que a melhor atitude seja excluir essas linhas que têm dados faltantes.
Para finalizarmos, lembre-se de algo muito importante: estas dicas que demos, são gerais. Em machine learning é muito importante analisarmos cada caso para tomarmos uma decisão, pois o que é melhor em uma situação, pode não funcionar muito bem em outra. Assim sendo, analise seu modelo, pesquise e aprofunde seus conhecimentos: esse é o caminho para obtemos bons resultados.
Continue estudando
Não pare por aqui. Ainda há diversos conceitos para aprender, e existe uma forma muito simples de fazer isso: com nosso curso de Machine Learning com Python. Nele, você irá aprofundar seus conhecimentos de maneira didática, com exemplos e exercícios práticos.
Além dessa opção, temos diversos outros cursos – tanto pagos quanto gratuitos. Todos com foco no aprendizado do aluno. Clique aqui e confira.
Leia também outros artigos:
- Substituindo dados missing com Machine Learning
- Visualização de dados para machine learning
- Dados de Treino e Teste
- Seu primeiro código de Machine Learning com Python
- Como criar seu primeiro dashboard no Power BI
- Entenda o básico de probabilidade
- Sistemas de Recomendação
