Com o Power BI, podemos utilizar algumas opções de scripts externos, que simplificam ou mesmo possibilitam determinadas tarefas. Para execuções com machine learning, dois grandes aliados são a Linguagem R e a Linguagem Python.
Neste artigo, falaremos sobre a utilização de Scripts Python no Power BI. Você irá descobrir como é simples e útil aliar essas duas ferramentas.

Antes de começar
Caso você queira aplicar nosso tutorial, será necessário carregar uma planilha de Excel no Power BI. Se ainda não sabe fazer isso, recomendamos a leitura do artigo abaixo:
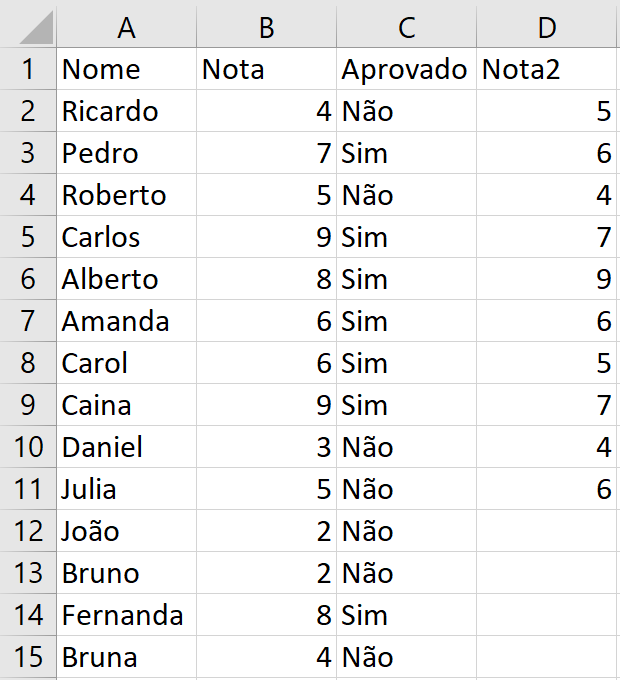
Nesse modelo com a linguagem Python no Power BI, utilizaremos a tabela seguir. Você pode criar uma planilha igual a esta, ou confeccionar uma com os dados que desejar.
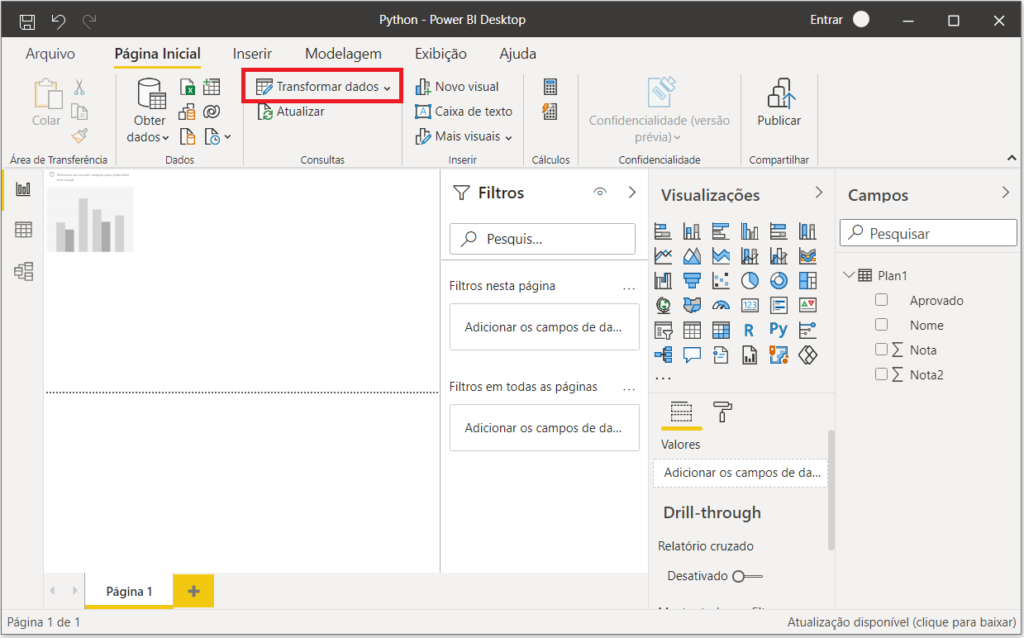
Após carregar a planilha, abra o Power Query. Para isso, clique na opção “Transformar dados” e a janela do Power Query aparecerá.
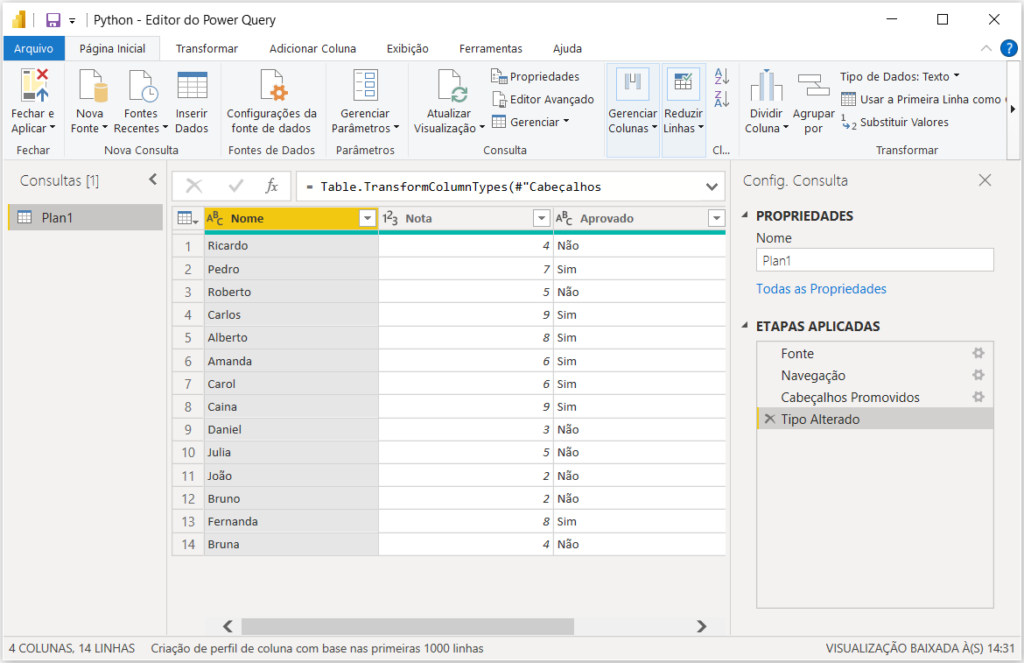
Configurando o Script Python
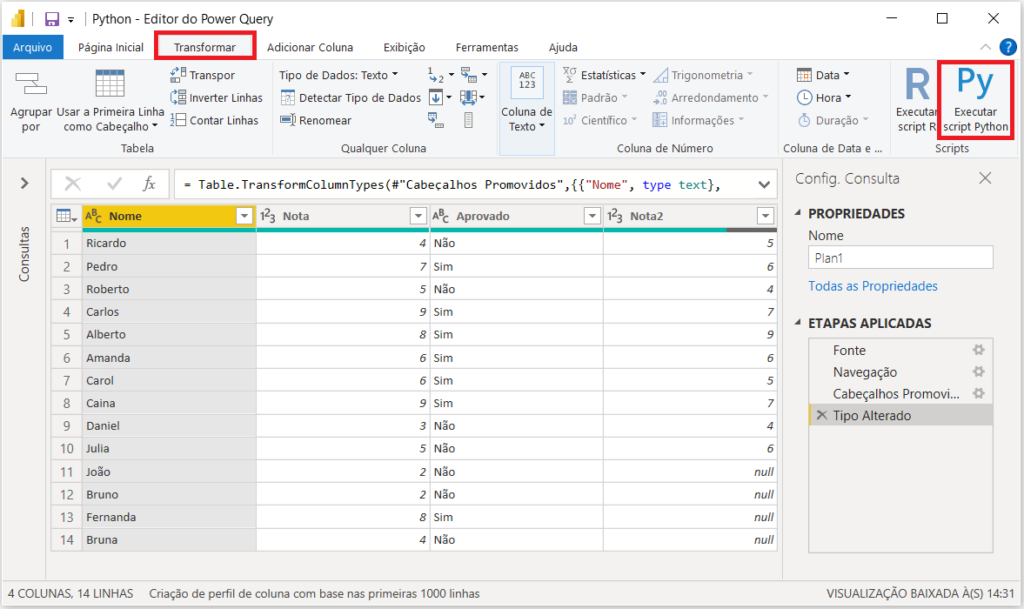
Se você já conhece a utilização do Script R no Power BI, verá que o funcionamento com a linguagem Python é muito semelhante. Para começar, mude, na barra superior, a opção para “Transformar”. Após, clique em “Executar script Python”.
Uma janela como esta automaticamente abrirá:
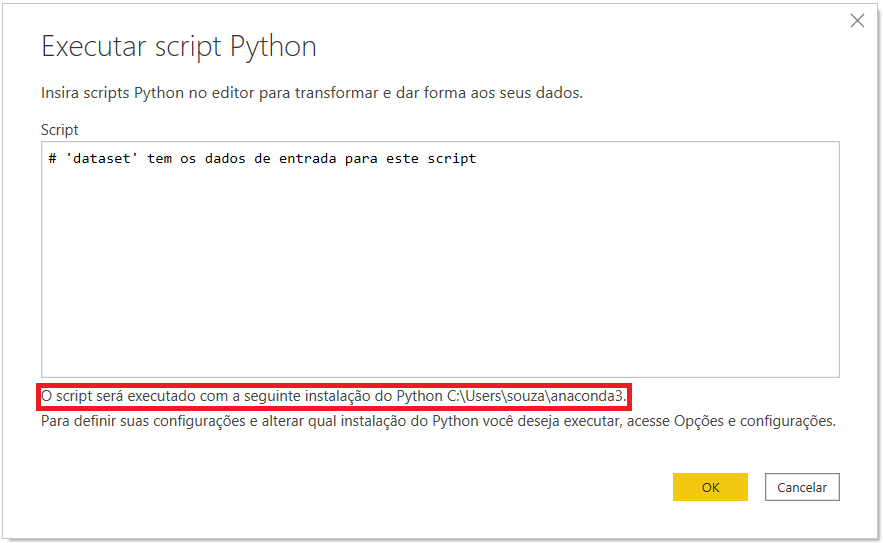
Esse é o editor de Script Python no Power Query. Se a linguagem Python está instalada em seu computador, a mensagem abaixo do editor do script (dentro do retângulo vermelho) indicará o local de instalação.
Caso a linguagem ainda não esteja instalada, você deverá fazê-lo para que possa prosseguir com o tutorial, pois o Python não pode ser executado diretamente pelo Power BI. Recomendamos que siga o tutorial abaixo, você verá que a instalação é bem simples:
Ao instalar o Python utilizando o Anaconda, você terá acesso a diversos pacotes e facilidades para as execuções de Scripts Python em análise de dados e machine learning.
Após a instalação, encerre o Power BI e execute-o novamente. Dessa forma, você conseguirá ver, abaixo do editor, onde o script está instalado. Caso isso não aconteça, o Python não irá funcionar corretamente.
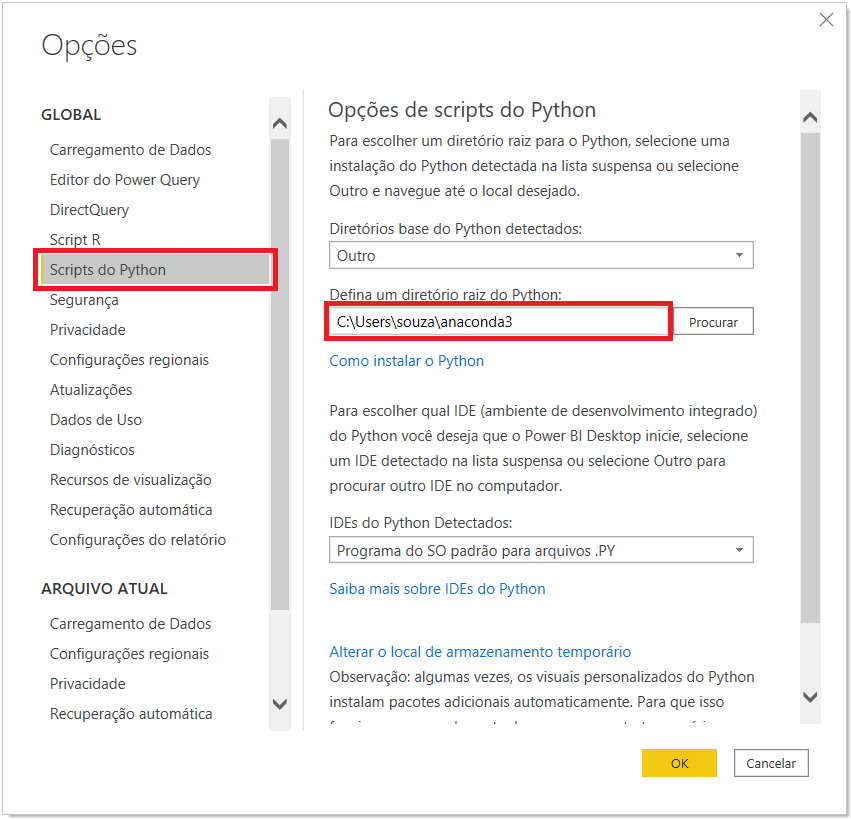
Para corrigir isso você deve clicar em “Cancelar”. Vá na aba “Arquivo”, clique em “Opções e configurações” e depois em “Opções”. Selecione a opção “Scripts do Python” e defina um diretório raiz.
Testando o Script Python
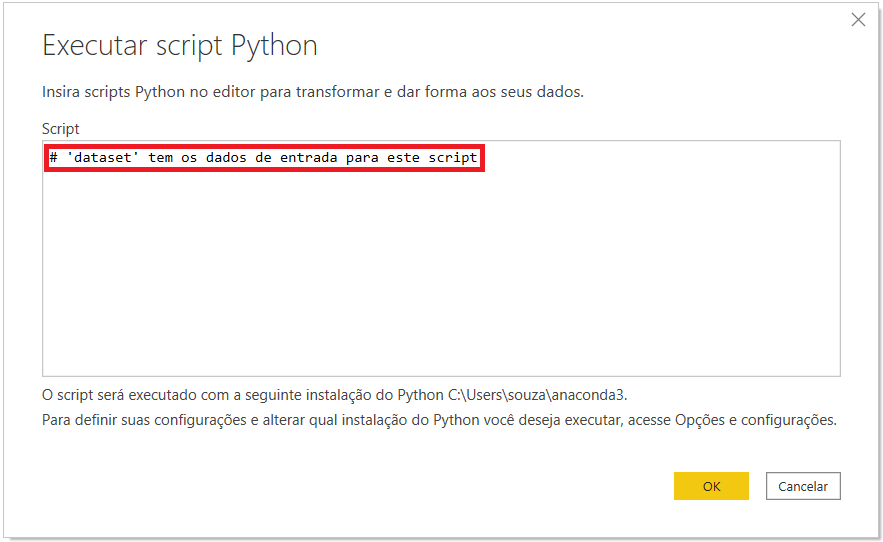
Agora que a linguagem Python foi instalada, podemos voltar ao nosso script. Você pode ver, na imagem abaixo, a frase: # ‘dataset’ tem os dados de entrada para este script. Isso significa que utilizaremos o objeto “dataset”.
Talvez você esteja se perguntando o que significa o hashtag (#) no início da frase. Esse símbolo é colocado para fazer comentários ao longo código. Toda vez que houver um “#” na frente de uma linha, significa que ela não será executada como parte do código. Você pode apagar essa linha se assim desejar.
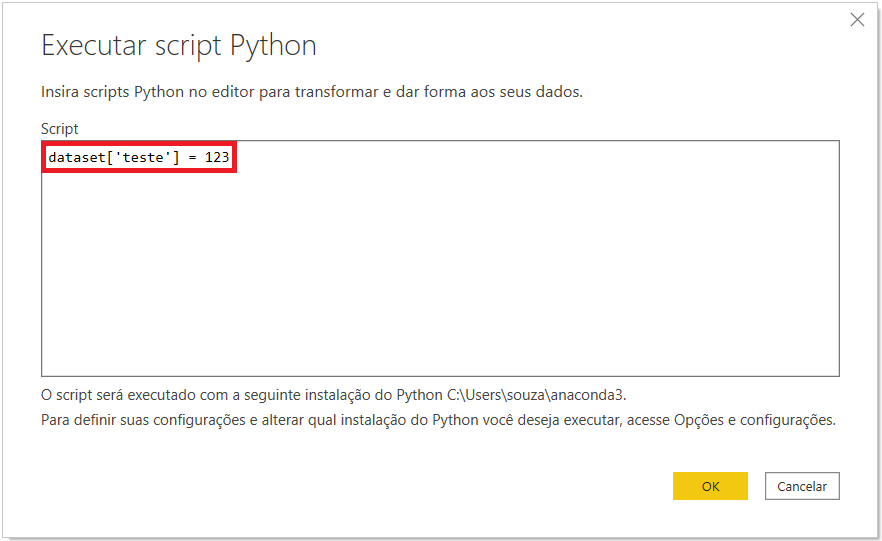
Agora, você poderá fazer um teste com um Script Python: vamos inserir uma coluna por meio de um código. Nesse caso, iremos inserir a coluna “teste”. Essa coluna terá como valores o número 123. Para isso, digite o seguinte código no editor:
Ao clicarmos em OK, a tela abaixo aparecerá:
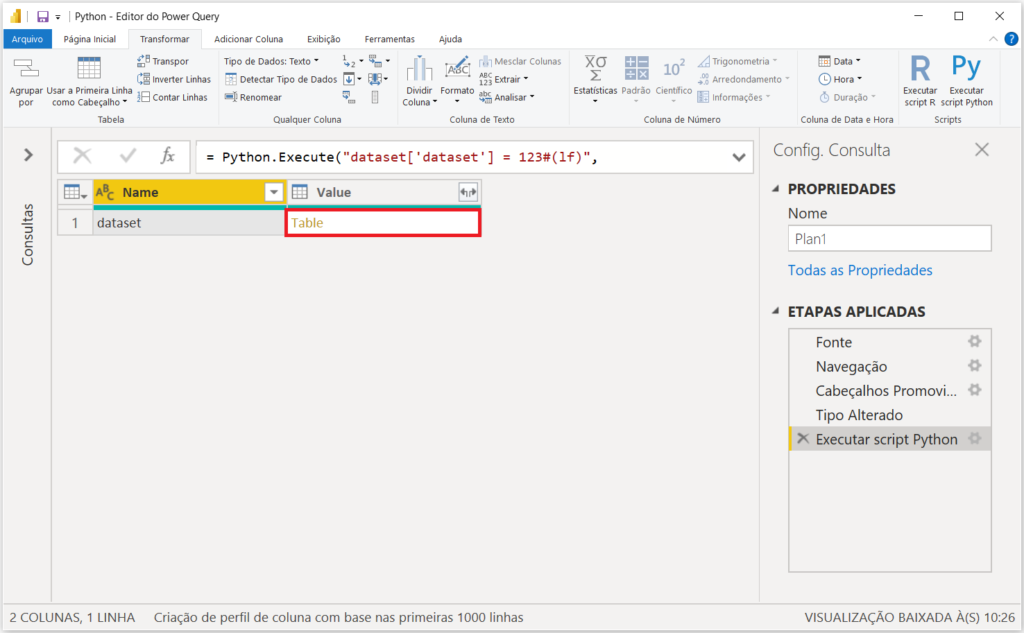
Ao contrário do que acontece com o Script R, ao utilizarmos o Python, conseguiremos fazer ajustes e tratamentos diretamente na nossa base de dados a partir do objeto “dataset”.
Aqui, podemos perceber que incluímos uma nova coluna, e o programa está nos retornando a tabela “dataset”. Ao clicar em “Table” veremos que continuamos com a tabela anterior adicionada de uma nova coluna – que é a coluna “Teste”, com os valores 123 em todas as linhas.
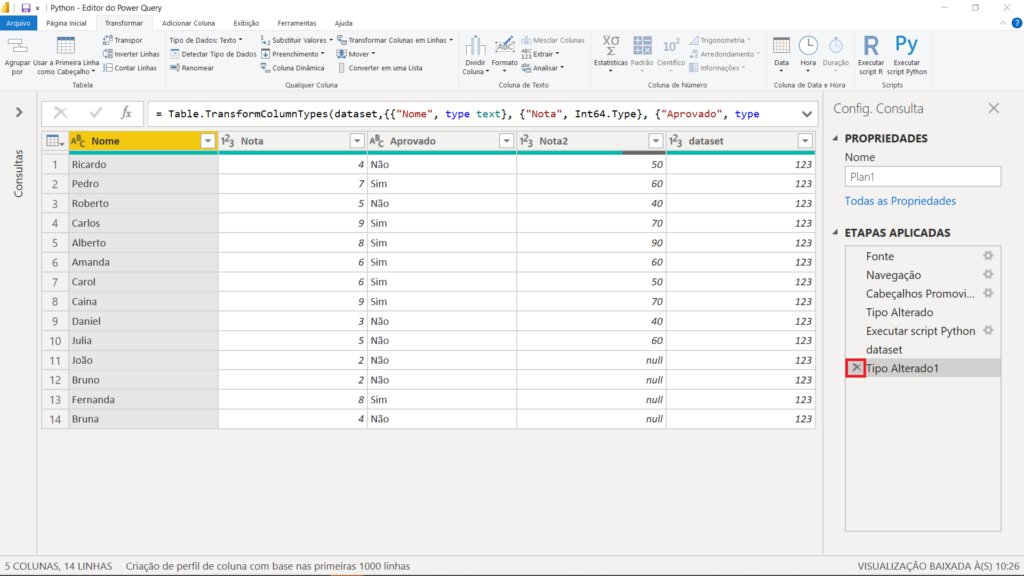
Um ponto interessante para observarmos com o Python é que normalmente o Power Query nos sugere uma alteração nos tipos dos dados. Entretanto, temos que tomar um pouco de cuidado.
No caso de nossa tabela, tínhamos na coluna “Nota 2” os valores 5, 6, e assim por diante. Após adicionada a nova coluna, o Power Query transformou para 50, 60 e 40. Nesse caso, essa alteração não foi correta; por isso precisamos excluir essa etapa. Para isso, clique no “X” ao lado de “Tipo Alterado 1”. Assim, voltamos a ter todos os dados com o tipo texto.
Se precisarmos do tipo numérico, temos que clicar em “ABC”, no lado esquerdo da coluna que queremos alterar. Podemos selecionar o tipo que quisermos. Abaixo, selecionamos a opção “Número inteiro”.
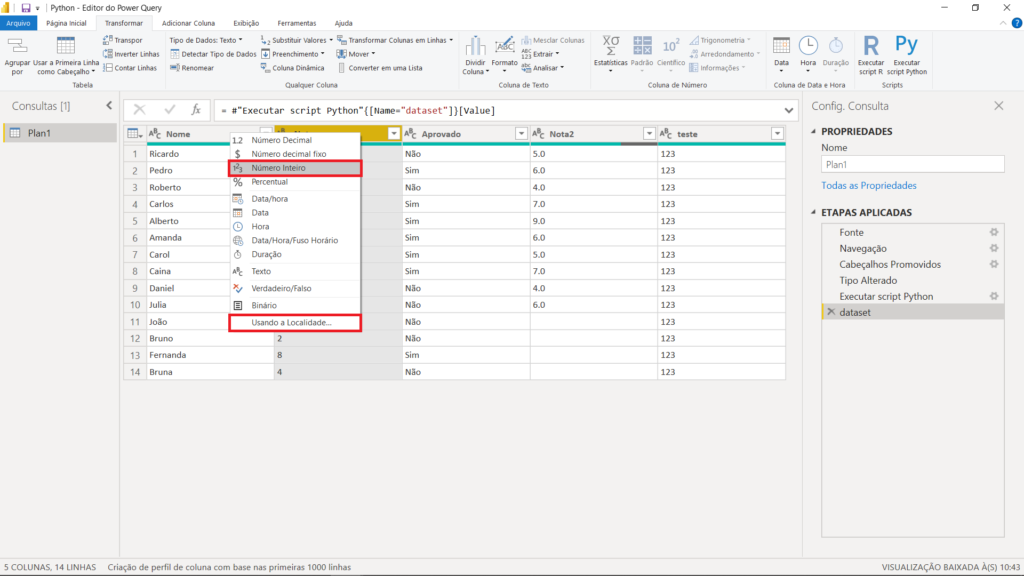
Na nota 2, temos valores como 5.0, 6.0 etc. Como o nosso Power BI está configurado no idioma português (Brasil), o sistema não irá interpretar o ponto (.) como separador decimal, pois utilizamos a vírgula (,) para esse fim.
Sendo assim, se nós simplesmente convertermos esse valor para um número inteiro, o ponto será ignorado, e o valor será transformado em 50 ou 60 – justamente o que já havia ocorrido anteriormente.
Para resolver isso, selecionamos a última opção que aparece quando clicamos em “ABC”: a opção “Usando a Localidade”. Dessa forma poderemos alterar o padrão de localidade de Português (Brasil) para Inglês (Estados Unidos).
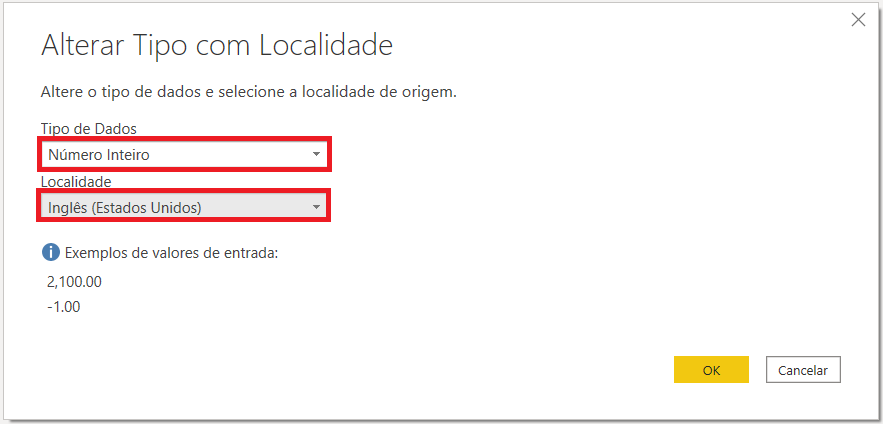
Assim, nesse padrão, o ponto (.) representará o separador decimal dos números. Ao darmos o OK, teremos a coluna em formato numérico com os valores corretos (5, 6, 4 etc.).
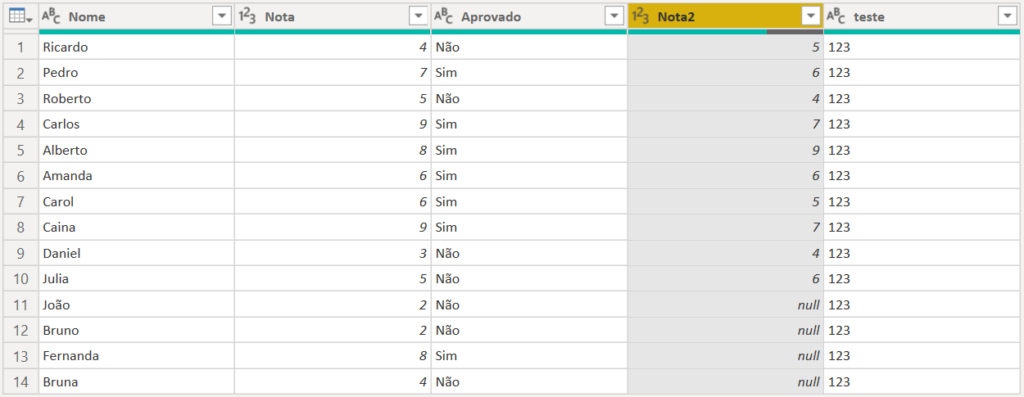
Note que é comum, quando utilizamos scripts em Python, que o programa altere o tipo dos dados e faça essa conversão. Se o seu Power BI estiver configurado com um padrão de linguagem diferente é possível que você não tenha esse problema.
Agora que você já viu que a execução do script Python funciona, você pode excluir a coluna de teste inserida. Para isso, aperte no “X” ao lado esquerdo da etapa aplicada que você quer excluir.
Executando uma regressão linear
Iremos, agora, passar para uma utilização mais prática do Script em Python. Para isso, utilizaremos a coluna com a nota 2. Qual será a nossa ideia? Iremos supor que, nessa turma, tivemos duas provas: nota 1 e nota 2 respectivamente.
Todos os alunos realizaram a primeira prova e por isso já têm a Nota 1. Entretanto, nem todos os alunos realizaram a prova 2; por isso, algumas linhas da coluna Nota 2 estão faltando. Nosso objetivo será, a partir da nota 1, obter uma previsão de qual será a nota 2 desses alunos que ainda não realizaram a segunda prova.
Para esse fim, utilizaremos um modelo simples de regressão linear. Nesse modelo, a nota 1 será a variável preditora e a nota 2 será a variável target. Dessa forma, traçaremos a reta de regressão linear que melhor se ajusta nesses dados.
Assim, poderemos utilizar essa reta para fazer as previsões das notas faltantes dos alunos. Além disso, poderemos conferir, a partir dos alunos que já têm a segunda nota, qual foi o erro obtido em cada um dos casos.
Talvez alguns desses termos tenham ficado um pouco confusos. Se esse for o seu caso, recomendamos que você confira nosso curso introdutório de Machine Learning.
Ele é composto de aulas gratuitas que irão explicar o que cada conceito significa. Além disso, se você não tem um conhecimento muito aprofundado sobre o que é regressão linear, a aula abaixo irá lhe ajudar:
Seguindo em frente, para começar a utilizar o script, você deve selecionar a opção “Executar Script em Python”. Você pode deletar a linha “# dataset’ tem os dados de entrada para este script“. Após isso, digite o código abaixo:
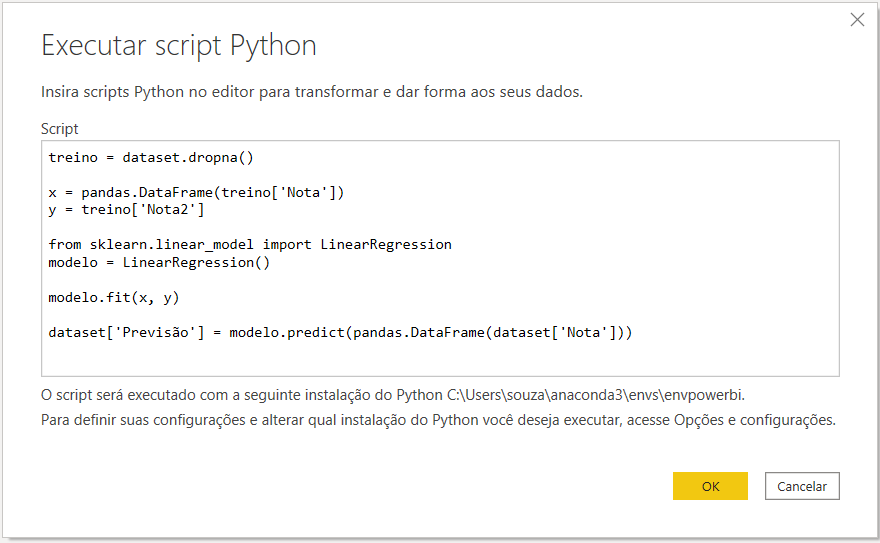
Você pode copiar e colar o código se preferir:
treino = dataset.dropna()
x = pandas.DataFrame(treino['Nota'])
y = treino['Nota2']
from sklearn.linear_model import LinearRegression
modelo = LinearRegression()
modelo.fit(x, y)
dataset['Previsão'] = modelo.predict(pandas.DataFrame(dataset['Nota']))Mas o que esse código faz? Vamos explicar linha por linha. Caso prefira, antes de seguir você pode conferir nossos cursos de Python básico e Python para Machine Learning, ambos gratuitos, que lhe darão a base necessária para um entendimento completo do script.
treino = dataset.dropna()Como, na mesma base de dados, temos alguns alunos que realizaram a segunda prova e outros não, utilizamos a função “dropna()” para excluir da nossa base todas as linhas que têm ao menos um dado faltante.
Ou seja, os quatro alunos que não realizaram a segunda prova serão excluídos da base. Nós salvamos isso em uma nova base, que nesse caso é a base “treino”. Assim, a tabela “dataset” continua da mesma forma – não excluímos da tabela original nenhum dos valores.
A nova base conterá os dados sem os valores faltantes e será utilizada para separar os dados em variável “x” (preditora) e variável “y” (target).
x = pandas.DataFrame(treino['Nota'])A variável “x”, nossa variável preditora, conterá os dados da coluna “Nota”. Além disso, faremos uma pequena conversão para um objeto “DataFrame” do Pandas, que será salvo na variável “x”.
y = treino['Nota2']Na nossa variável “y”, salvaremos os dados da nota 2, que é a nossa variável target.
from sklearn.linear_model import LinearRegressionAqui, carregaremos o pacote “LinearRegression“, que contem o algoritmo de regressão linear que será utilizado para a criação do nosso modelo.
Essa linha, então, simplesmente carrega, para a nossa seção, o pacote que precisamos para utilizar a função. Se você fez a instalação com o anaconda, conforme indicamos no nosso tutorial, poderá fazer essa execução sem nenhum problema.
modelo = LinearRegression()Com essa linha, vamos instanciar a função “LinearRegression” para a variável “modelo” que estamos criando, o que possibilitará o treinamento do modelo.
modelo.fit(x, y)Na sequência, daremos um “fit” no modelo. Esse método “fit” aqui indicado é o treinamento efetivo do nosso modelo. Por isso, informamos os dados da variável preditora e da variável target “(x, y)”.
Assim, o modelo será treinado e, nesse caso aqui, a reta de regressão linear será criada. A partir desse momento, a reta já existirá e poderemos realizar as previsões.
dataset['Previsão'] = modelo.predict(pandas.DataFrame(dataset['Nota']))Para isso, utilizaremos o método “predict”, que precisará receber os novos dados. Nós devemos indicar os dados de “Nota” da primeira prova que temos.
Entretanto, vamos indicar os dados da base completa (dataset) e não apenas da base de treino, porque queremos inclusive os alunos que não tiveram a “Nota 2” registrada.
Por fim, nós salvaremos essas previsões em uma nova coluna que estamos criando, para o nosso dataset, com o nome de “Previsão”.
Após digitado esse código, podemos dar um ok. Nós teremos, então, todos os dataframes que esse nosso script retorna:
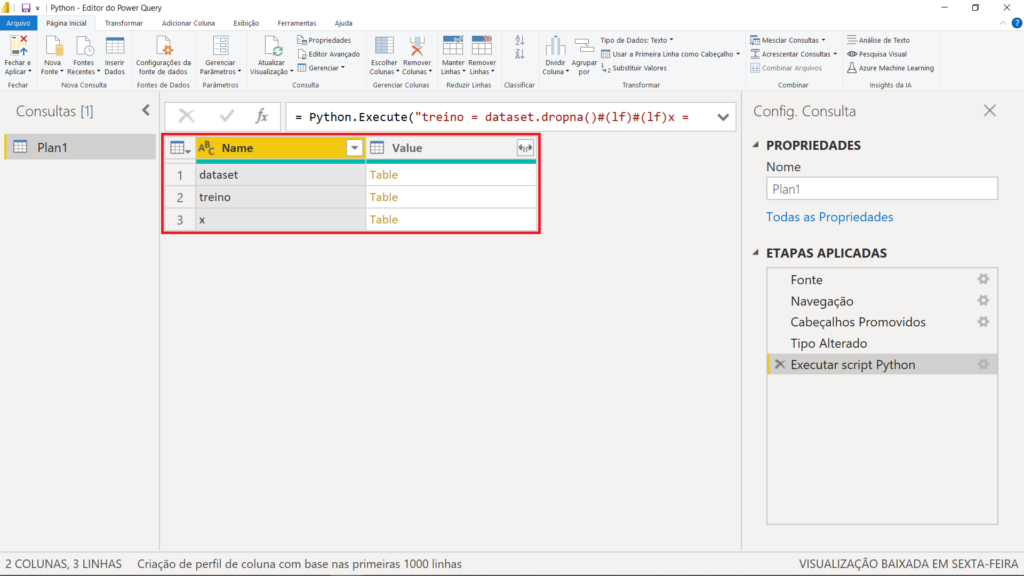
Se clicarmos na opção “Table” do “Treino”, podemos conferir a tabela que foi utilizada no treino do modelo. Você verá que teremos a mesma situação da conversão dos dados já mencionada anteriormente.
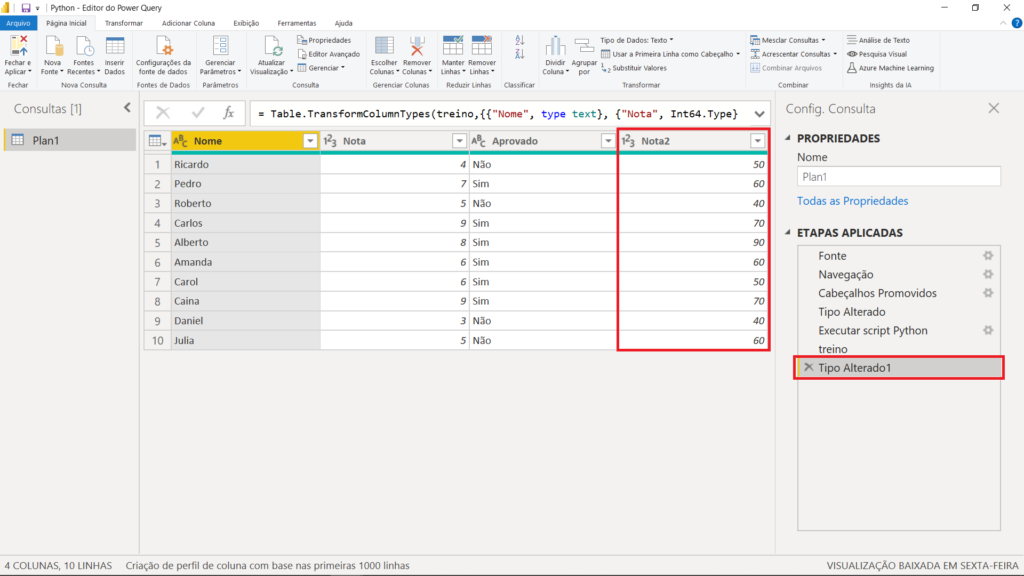
No entanto, não foi isso que o Python utilizou. Se retirarmos a conversão clicando no “X” ao lado de “Tipo Aalterado1”, veremos os valores originais. Podemos ver que temos menos nomes porque aqueles que não têm a nota 2 foram excluídos dessa base de dados de treino.
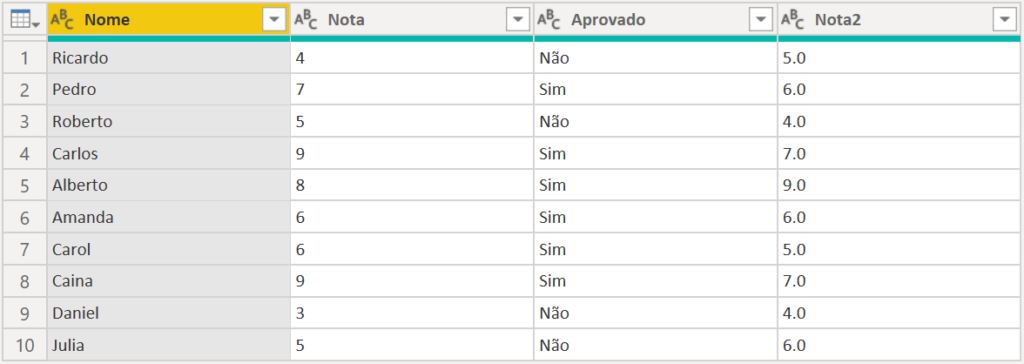
Ao voltarmos e clicarmos na opção “Table” do “dataset”, teremos nossa tabela completa com as previsões.
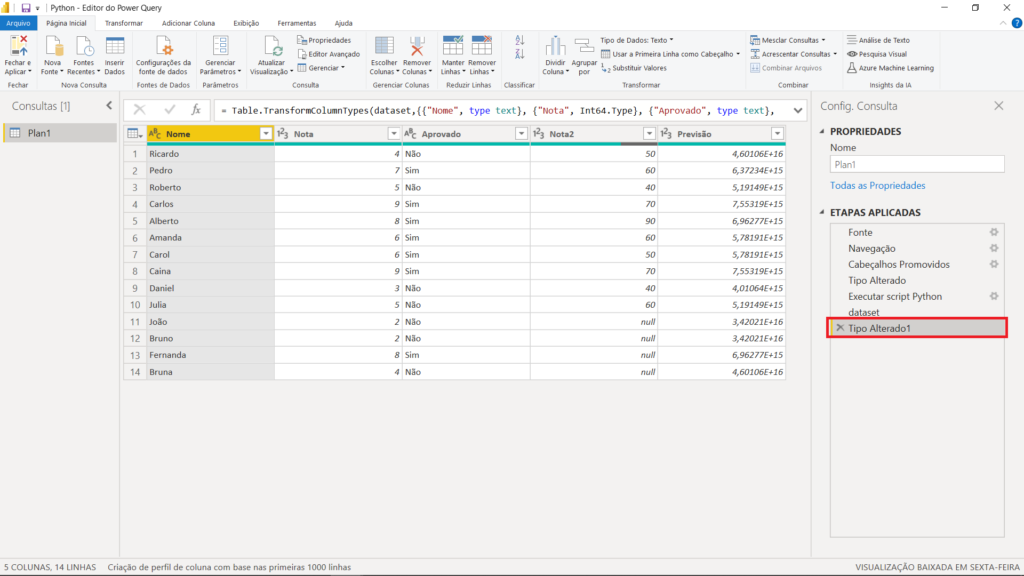
Você também pode excluir a alteração do tipo de dado clicando no “X” ao lado de “Tipo Alterado1”.
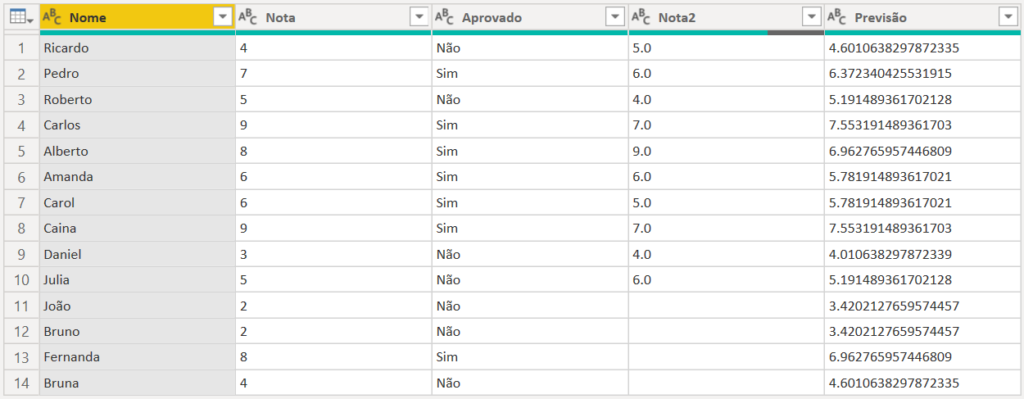
Aqui é possível ver as previsões da nossa reta de regressão linear. De acordo esse modelo, veremos que a Bruna, que tirou 4 na primeira prova, deverá tirar uma nota de 4.6 na segunda.
Fernanda, que teve uma nota 8 na primeira avaliação, tem uma previsão de tirar 6.9 na segunda. Nós podemos, inclusive, pegar o exemplo de um aluno que tenha feito as duas provas para calcular o erro do modelo.
Roberto teve 4 como segunda nota; tendo tirado 5 na primeira avaliação, segundo nosso modelo ele deveria ter 5.19 como segunda nota. Nesse caso, a regressão linear teve um erro de 1.19 na previsão de nota do aluno.
Você pode continuar analisando as notas de cada aluno para avaliar o modelo como um todo, ou conferir neste artigo uma análise mais completa sobre Regressão Linear.
Se você preferir, pode conferir um resumo do assunto na videoaula abaixo:
Aprofunde seus conhecimentos
Viu como foi fácil aliar a linguagem Pyhton com o Power BI? Se você gostou de trabalhar essas ferramentas, recomendamos nosso curso de Machine Learning Online (com Power BI).
Nele, você vai aprender diversos tópicos citados nesse artigo de uma forma aprofundada. Você verá que em algumas aula já será capaz de aplicar modelos de Machine Learning e fazer suas próprias análises.
Você também pode conferir o curso de Pyhton para Machine Learning. Aqui, você poderá avançar em seus conhecimentos sobre essa linguagem de programação cada vez mais utilizada.
Além disso, temos diversas outras opções de cursos, todos voltados para o aprendizado do aluno, com muita didática e exemplos práticos. Clique aqui e confira!
Leia também outros artigos:
- Tudo sobre Python
- O que é Business Intelligence?
- O que é Machine Learning (Aprendizado de Máquina)
- O que é inteligência artificial?
- O que é Ciência de Dados?
- O pacote Numpy – Python para Machine Learning
- O pacote Pandas – Python para Machine Learning
- A biblioteca scikit-learn – Python para Machine Learning
- Seu primeiro código de Machine Learning com Python
