Machine Learning é uma tecnologia em alta, muito utilizada por grandes empresas e presente nos softwares mais atuais. Isto nos leva a pensar que aplicar machine learning é algo extremamente complexo e para poucos, porém este pensamento não poderia estar mais errado.
Criar nossos próprios modelos de machine learning com linguagens como Python e R é muito simples, e está ao alcance de todos, até mesmo daqueles que estão começando seu aprendizado nestas áreas.
Para provar o que estamos falando, vamos criar, com poucas linhas de código, um poderoso modelo de machine learning com Python.
O script
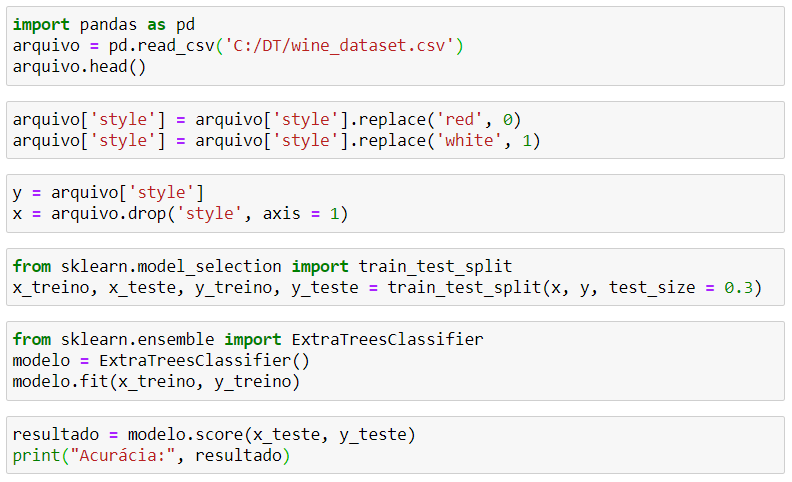
O script será muito simples. Inicialmente, carregamos uma base de dados que contém características de vinhos, estando eles divididos entre tintos e brancos, senda esta a característica que tentaremos prever.
Separaremos os dados em treino e teste, para que o modelo possa ser treinado e depois testado. Com esta separação feita, já poderemos apresentar os dados de treino ao algoritmo de machine learning que utilizaremos, e nosso modelo será criado. Apresentaremos então os dados de treino ao modelo para verificar sua acurácia, e posteriormente alguns valores específicos serão previstos.
Passo a passo
Para iniciar precisamos carregar o dataset que será utilizado. Para acompanhar, acesse este link no Kaggle e efetue o download do arquivo, conforme imagem abaixo. Caso você ainda não tenha cadastro na plataforma, será solicitado. Este um processo bem simples que lhe dará acesso a todos os arquivos disponíveis no site.
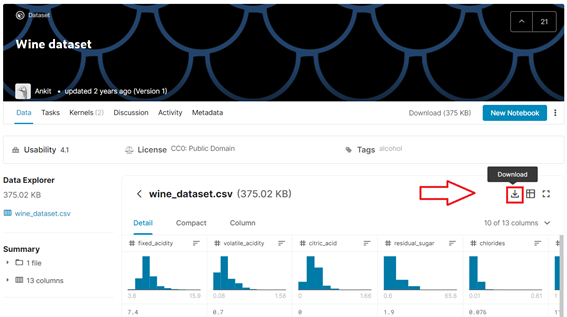
Com o arquivo .csv salvo no computador, podemos carregá-lo. Para isso utilizaremos o pacote Pandas, com a função read_csv(), indicando o diretório e nome do arquivo. No computador que estamos utilizando o arquivo está na pasta “C:/DT/”, com o nome “wine_dataset.csv”.
Altere estes valores de acordo com a pasta do seu computador, e o nome do seu arquivo.
import pandas as pd
arquivo = pd.read_csv('C:/DT/wine_dataset.csv')
arquivo.head()
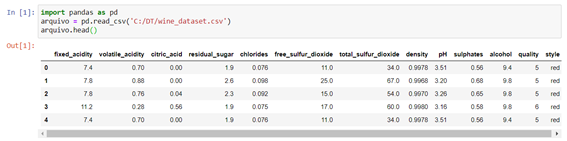
Como podemos ver com a função head(), o dataset contém muitas variáveis com as características de cada vinho. Neste exemplo trataremos como variável target a “style”, que define se o vinho em questão é tinto ou branco. As demais variáveis serão utilizadas como variáveis preditoras.
Seguindo, precisamos tornar os termos “red” e “white” existentes na coluna “style” compreensíveis para o algoritmo, que espera receber dados numéricos. Assim, transformaremos o termo “red” em “0” e “white” em “1”.
arquivo['style'] = arquivo['style'].replace('red', 0)
arquivo['style'] = arquivo['style'].replace('white', 1)
Criamos então a variável “y” com os dados da coluna “style”, ou seja, os dados que iremos prever. Criamos também a variável “x” com as demais colunas do dataset, que são as variáveis preditoras.
y = arquivo['style']
x = arquivo.drop('style', axis = 1)
Neste ponto já poderíamos criar o modelo de machine learning utilizando validação cruzada k-fold, mas para simplificar este primeiro entendimento, vamos ainda separar os dados em treino e teste, de maneira que fique evidente os dados utilizados na criação do modelo, e aqueles utilizados apenas para testar seu desempenho.
Aqui utilizaremos uma função desenvolvida para este fim, que é a train_test_split() do pacote sklearn. Com ela garantimos que os dados serão aleatoriamente distribuídos entre os dois grupos, e facilmente informamos o tamanho de cada grupo.
Indicando as variáveis “x” e “y” estamos dizendo que queremos separar estas duas variáveis em dois grupos, sendo que com o parâmetro “test_size = 0.3” determinamos que os dados de teste receberão 30% dos dados, e os dados de treino 70%. Como estamos dividindo duas bases, como resultado teremos quatro bases, sendo que cada uma será salva na respectiva variável.
from sklearn.model_selection import train_test_split
x_treino, x_teste, y_treino, y_teste = train_test_split(x, y, test_size = 0.3)
print(arquivo.shape, x_treino.shape, x_teste.shape, y_treino.shape, y_teste.shape)
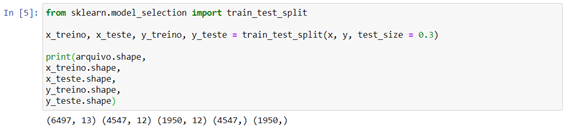
Acima vemos que originalmente nosso dataset possuía 6497 linhas e 13 colunas. Ao separarmos esta base em variável target e variáveis preditoras, a base “x” passou a ter 12 colunas, e a “y” uma. Assim vemos que os formatos resultantes da separação entre treino e teste são arquivos com 70% do número de linhas do original para treino, ou seja, 4547 linhas, e as 30% restantes, que são 1950, para teste.
Até aqui tratamos apenas do pré-processamento dos dados. Ou seja, nenhuma destas linhas de código envolveu a utilização de um algoritmo de machine learning. Esta parte será uma das mais simples deste exemplo. Com apenas 4 linhas de código o modelo será criado e testado, estando pronto para previsões futuras.
Machine Learning
Vamos utilizar um algoritmo muito poderoso, chamado ExtraTrees, que criará várias árvores de decisão. Este algoritmo está pronto para ser utilizado, sendo que precisamos apenas indicar sua função. Como estamos trabalhando em um problema de classificação utilizaremos a função “ExtraTreesClassifier()”.
Com o método “fit” passamos ao algoritmo as variáveis preditoras e a variável target, para que ele possa entender a relação entre estes dados, e chagar ao modelo ideal. Com o método “score” passamos ao modelo os dados de teste, para que possamos avaliar seu desempenho.
from sklearn.ensemble import ExtraTreesClassifier
modelo = ExtraTreesClassifier()
modelo.fit(x_treino, y_treino)
resultado = modelo.score(x_teste, y_teste)
print("Acurácia:", resultado)

Acima vemos nosso resultado final, uma acurácia superior a 99%. Ou seja, em praticamente todos os testes realizados o modelo acertou sua previsão, indicando corretamente se determinado vinho é tinto ou branco.
Podemos visualizar alguns exemplos. Selecionando aleatoriamente 5 amostras, vemos que 4 delas são vinhos brancos (valor 1), e uma vinho tinto (valor 0).
y_teste[400:405]

Vamos passar exatamente estas amostras acima para que nosso modelo efetue a previsão destes cinco valores. Lembrando que ao indicar a base “x_teste” estamos apresentando ao modelo apenas as 12 variáveis preditoras. Com o método “predict” o modelo irá retornar as previsões para cada uma das amostras indicadas.
previsoes = modelo.predict(x_teste[400:405])
print(previsoes)

Como podemos ver, o modelo indicou que as 4 primeiras amostras devem ser de vinhos brancos, e a última de vinho tinto, ou seja, ele acertou nestas 5 previsões, conforme vimos acima.
Caso prefira, confira no vídeo abaixo a execução deste mesmo script:
Machine Learning – Teoria e Prática
Neste exemplo vimos como é simples, rápida e prática a criação de modelos de machine learning com Python, mas é claro que para utilizar efetivamente a tecnologia com toda sua capacidade alguns conhecimentos mais aprofundados são necessários.
Caso você realmente queira aprender machine learning e Python para machine learning, comece com nosso curso de machine learning com Python – módulo 1.
Você irá do básico ao avançado, de maneira simples e objetiva. Nossos cursos são focados na didática, olhando sempre para o entendimento do aluno, sem enrolações ou lacunas no aprendizado.
Leia também:
